
-
1. Erste Schritte
-
2. Git Grundlagen
-
3. Git Branching
- 3.1 Branches auf einen Blick
- 3.2 Einfaches Branching und Merging
- 3.3 Branch-Management
- 3.4 Branching-Workflows
- 3.5 Remote-Branches
- 3.6 Rebasing
- 3.7 Zusammenfassung
-
4. Git auf dem Server
- 4.1 Die Protokolle
- 4.2 Git auf einem Server einrichten
- 4.3 Erstellung eines SSH-Public-Keys
- 4.4 Einrichten des Servers
- 4.5 Git-Daemon
- 4.6 Smart HTTP
- 4.7 GitWeb
- 4.8 GitLab
- 4.9 Von Drittanbietern gehostete Optionen
- 4.10 Zusammenfassung
-
5. Verteiltes Git
-
6. GitHub
-
7. Git Tools
- 7.1 Revisions-Auswahl
- 7.2 Interaktives Stagen
- 7.3 Stashen und Bereinigen
- 7.4 Deine Arbeit signieren
- 7.5 Suchen
- 7.6 Den Verlauf umschreiben
- 7.7 Reset entzaubert
- 7.8 Fortgeschrittenes Merging
- 7.9 Rerere
- 7.10 Debuggen mit Git
- 7.11 Submodule
- 7.12 Bundling
- 7.13 Replace (Ersetzen)
- 7.14 Anmeldeinformationen speichern
- 7.15 Zusammenfassung
-
8. Git einrichten
- 8.1 Git Konfiguration
- 8.2 Git-Attribute
- 8.3 Git Hooks
- 8.4 Beispiel für Git-forcierte Regeln
- 8.5 Zusammenfassung
-
9. Git und andere VCS-Systeme
- 9.1 Git als Client
- 9.2 Migration zu Git
- 9.3 Zusammenfassung
-
10. Git Interna
-
A1. Anhang A: Git in anderen Umgebungen
- A1.1 Grafische Schnittstellen
- A1.2 Git in Visual Studio
- A1.3 Git in Visual Studio Code
- A1.4 Git in IntelliJ / PyCharm / WebStorm / PhpStorm / RubyMine
- A1.5 Git in Sublime Text
- A1.6 Git in Bash
- A1.7 Git in Zsh
- A1.8 Git in PowerShell
- A1.9 Zusammenfassung
-
A2. Anhang B: Git in deine Anwendungen einbetten
- A2.1 Die Git-Kommandozeile
- A2.2 Libgit2
- A2.3 JGit
- A2.4 go-git
- A2.5 Dulwich
-
A3. Anhang C: Git Kommandos
- A3.1 Setup und Konfiguration
- A3.2 Projekte importieren und erstellen
- A3.3 Einfache Snapshot-Funktionen
- A3.4 Branching und Merging
- A3.5 Projekte gemeinsam nutzen und aktualisieren
- A3.6 Kontrollieren und Vergleichen
- A3.7 Debugging
- A3.8 Patchen bzw. Fehlerkorrektur
- A3.9 E-mails
- A3.10 Externe Systeme
- A3.11 Administration
- A3.12 Basisbefehle
7.8 Git Tools - Fortgeschrittenes Merging
Fortgeschrittenes Merging
Das Mergen ist mit Git in der Regel ziemlich einfach. Da es in Git recht einfach ist, einen Branch mehrfach zu mergen, kannst du manchmal sehr langlebigen Branch haben. Du solltest ihn aber während deiner Arbeit immer wieder aktualisieren und dabei mögliche kleine Konflikte lösen, anstatt am Ende der Arbeit von enorm großen Konflikten überrascht zu werden.
Manchmal kommt es jedoch zu heiklen Konflikten. Im Gegensatz zu einigen anderen Versionskontrollsystemen versucht Git nicht, bei der Lösung von Merge-Konflikten eigenständig vorzugehen. Die Philosophie von Git ist es, intelligent zu erkennen, wann eine Merge-Lösung eindeutig ist, doch wenn es einen Konflikt gibt, versucht es nicht, automatisch eine Lösung zu finden. Wenn du also zu lange mit dem Zusammenführen zweier Branches wartest, die sich auseinander entwickeln, so kannst du auf einige Probleme stoßen.
In diesem Abschnitt stellen wir dir vor, welche Probleme sich daraus ergeben könnten und welche Werkzeuge Git dir zur Verfügung stellt, um diese heiklen Situationen zu bewältigen. Wir werden auch einige der verschiedenen, atypischen Merges vorstellen, die dir zur Verfügung stehen. Außerdem werden wir dir zeigen, wie du Merges wieder rückgängig machen kannst, die bereits durchgeführt wurden.
Merge-Konflikte
Während wir einige Grundlagen zur Lösung von Merge-Konflikten in Kapitel 3, Einfache Merge-Konflikte, behandelt haben, bietet Git für komplexere Konflikte einige Werkzeuge, die dir helfen, herauszufinden, was passiert ist und wie du den Konflikt am besten lösen kannst.
Vergewissere dich zunächst einmal, dass dein Arbeitsverzeichnis sauber ist, bevor du einen Merge startest bei dem Konflikte auftreten können. Committe aktuelle Arbeiten auf einem temporären Branch oder stashe sie. Auf diese Weise kannst du alles, was du hier ausprobierst, wieder rückgängig machen. Falls du nicht gespeicherte Änderungen in deinem Arbeitsverzeichnis hast, während du einen Merge ausführst, können dir einige dieser Tipps helfen, diese Arbeit zu nicht zu verlieren.
Lass uns ein sehr einfaches Beispiel betrachten. Hier haben wir eine extrem einfache Ruby-Datei, die „hello world“ ausgibt.
#! /usr/bin/env ruby
def hello
puts 'hello world'
end
hello()In unserem Repository erstellen wir einen neuen Branch mit der Bezeichnung whitespace. Dann ändern wir alle Unix-Zeilenendungen in DOS-Zeilenendungen für jede Zeile der Datei, also ändern wir nur mit Leerzeichen.
Dann ändern wir die Zeile „hello world“ in „hello mundo“.
$ git checkout -b whitespace
Switched to a new branch 'whitespace'
$ unix2dos hello.rb
unix2dos: converting file hello.rb to DOS format ...
$ git commit -am 'Convert hello.rb to DOS'
[whitespace 3270f76] Convert hello.rb to DOS
1 file changed, 7 insertions(+), 7 deletions(-)
$ vim hello.rb
$ git diff -b
diff --git a/hello.rb b/hello.rb
index ac51efd..e85207e 100755
--- a/hello.rb
+++ b/hello.rb
@@ -1,7 +1,7 @@
#! /usr/bin/env ruby
def hello
- puts 'hello world'
+ puts 'hello mundo'^M
end
hello()
$ git commit -am 'Use Spanish instead of English'
[whitespace 6d338d2] Use Spanish instead of English
1 file changed, 1 insertion(+), 1 deletion(-)Jetzt wechseln wir wieder zu unserem Branch master und fügen einige Kommentare für die Funktion hinzu.
$ git checkout master
Switched to branch 'master'
$ vim hello.rb
$ git diff
diff --git a/hello.rb b/hello.rb
index ac51efd..36c06c8 100755
--- a/hello.rb
+++ b/hello.rb
@@ -1,5 +1,6 @@
#! /usr/bin/env ruby
+# prints out a greeting
def hello
puts 'hello world'
end
$ git commit -am 'Add comment documenting the function'
[master bec6336] Add comment documenting the function
1 file changed, 1 insertion(+)Jetzt versuchen wir unseren whitespace branch zu mergen, es kommt zu einem Konflikt wegen der Änderungen an den Whitespaces (dt. Leerzeichen).
$ git merge whitespace
Auto-merging hello.rb
CONFLICT (content): Merge conflict in hello.rb
Automatic merge failed; fix conflicts and then commit the result.Einen Merge abbrechen
Wir haben jetzt einige Optionen.
Zunächst einmal sollten wir uns überlegen, wie wir aus dieser Situation herauskommen können.
Vielleicht hast du nicht mit Konflikten gerechnet und willst dich noch nicht ganz mit der Situation auseinandersetzen, dann kannst du einfach mit git merge --abort den Merge abbrechen.
$ git status -sb
## master
UU hello.rb
$ git merge --abort
$ git status -sb
## masterDie Option git merge --abort versucht, zu dem Zustand zurückzukehren, der vor dem Merge bestand.
Die einzigen Ausnahmen, in denen diese Funktion nicht perfekt funktioniert, wären nicht gestashte oder nicht committete Einträge in deinem Arbeitsverzeichnis. Wenn das nicht der Fall ist, sollte sie einwandfrei funktionieren.
Wenn du aus irgendeinem Grund noch einmal von vorne anfangen möchtest, kannst du auch git reset --hard HEAD ausführen. Dein Repository wird dann wieder in den Zustand direkt nach dem letzten Commit versetzt.
Denke daran, dass jede nicht committete Arbeit verloren geht. Stelle also sicher, dass du diese Arbeit wirklich nicht mehr benötigst.
Leerzeichen ignorieren
In diesem speziellen Fall sind die Konflikte durch Leerzeichen verursacht. Dieser Konflikt ist ziemlich eindeutig. Aber auch in anderen Fällen ist der Konflikt ziemlich leicht zu erkennen, da jede Zeile auf der einen Seite gelöscht und auf der anderen Seite wieder hinzugefügt wird. Standardmäßig sieht Git alle diese Zeilen als geändert an, weshalb es die Dateien nicht miteinander mergen kann.
Der Standard Merge-Strategie kann man Argumente mitgeben. Einige beziehen sich auf die Nichtbeachtung von Leerzeichen-Änderungen.
Wenn du weißt, dass du viele Leerzeichen-Änderungen bei einem Merge hast, kannst du ihn einfach abbrechen und erneut durchführen, diesmal mit den Optionen -Xignore-all-space oder -Xignore-space-change.
Die erste Option ignoriert Leerzeichen beim Vergleich von Zeilen komplett, die zweite betrachtet Folgen von einem oder mehreren Leerzeichen als identisch.
$ git merge -Xignore-space-change whitespace
Auto-merging hello.rb
Merge made by the 'recursive' strategy.
hello.rb | 2 +-
1 file changed, 1 insertion(+), 1 deletion(-)Da in diesem Fall die tatsächlichen Dateiänderungen keinen Konflikt darstellen, mergen die einzelnen Dateien problemlos miteinander, wenn wir die Änderungen der Leerzeichen ignorieren.
Das ist sehr praktisch, falls du jemand in deinem Team hast, der gerne alles von Leerzeichen auf Tabulatoren oder umgekehrt formatiert.
Manuelles Re-Mergen von Dateien
Obwohl Git die Behandlung von Leerzeichen vorab relativ gut verarbeitet, gibt es andere Änderungen, die Git nicht automatisch übernehmen kann, die jedoch verskriptet werden können. Nehmen wir beispielsweise an, dass Git nicht mit der Änderung der Leerzeichen umgehen konnte und wir es von Hand machen müssten.
Was wir unbedingt machen müssen, ist die Datei, die wir mergen wollen, durch das Programms dos2unix laufen zu lassen, noch vor dem eigentlichen Mergen der Datei.
Also, wie sollten wir das realisieren?
Als Erstes geraten wir in einen Merge-Konflikt beim Aufruf des Befehls. Anschließend wollen wir Kopien von unserer Version der Datei, deren Version (aus dem Branch, in den wir mergen wollen) und der gemeinsamen Version (von der beide Seiten abstammen) bekommen. Danach sollten wir entweder deren oder unsere Seite korrigieren und den Merge für diese einzelne Datei noch ein zweites Mal versuchen.
Es ist eigentlich ganz einfach, die drei Dateiversionen zu erhalten. Git speichert alle diese Versionen im Index unter „stages“ (dt. Stufe), die jeweils mit Ziffern versehen sind. Stage 1 ist der gemeinsame Vorgänger, Stage 2 ist deine Version und Stage 3 stammt aus dem MERGE_HEAD, „deren“ Version, zu der die Datei(en) gemerged werden.
Du kannst eine Kopie jeder dieser Versionen der Konfliktdatei mit dem Befehl git show mit einer speziellen Syntax extrahieren.
$ git show :1:hello.rb > hello.common.rb
$ git show :2:hello.rb > hello.ours.rb
$ git show :3:hello.rb > hello.theirs.rbWenn du es etwas mehr Hard-Core willst, kannst du auch den Basisbefehl ls-files -u verwenden, um die aktuellen SHA-1s der Git-Blobs für jede dieser Dateien zu erhalten.
$ git ls-files -u
100755 ac51efdc3df4f4fd328d1a02ad05331d8e2c9111 1 hello.rb
100755 36c06c8752c78d2aff89571132f3bf7841a7b5c3 2 hello.rb
100755 e85207e04dfdd5eb0a1e9febbc67fd837c44a1cd 3 hello.rbDas :1:hello.rb ist nur eine Kurzform für die Suche nach dem Blob SHA-1.
Nachdem wir jetzt den Inhalt von allen drei Stufen in unserem Arbeitsverzeichnis haben, können wir deren es manuell korrigieren, um das Problem mit den Leerzeichen zu beheben und die Datei mit dem dafür vorgesehenen, kaum bekannten Befehl git merge-file neu zu mergen.
$ dos2unix hello.theirs.rb
dos2unix: converting file hello.theirs.rb to Unix format ...
$ git merge-file -p \
hello.ours.rb hello.common.rb hello.theirs.rb > hello.rb
$ git diff -b
diff --cc hello.rb
index 36c06c8,e85207e..0000000
--- a/hello.rb
+++ b/hello.rb
@@@ -1,8 -1,7 +1,8 @@@
#! /usr/bin/env ruby
+# prints out a greeting
def hello
- puts 'hello world'
+ puts 'hello mundo'
end
hello()An dieser Stelle haben wir die Datei geschickt miteinander gemerged.
Das funktioniert sogar besser als die Option ignore-space-change, weil dadurch die Änderungen an den Leerzeichen vor dem Zusammenführen korrigiert werden, statt sie einfach zu ignorieren.
Beim Merge mit ignore-space-change haben wir sogar ein paar Zeilen mit DOS-Zeilenenden erhalten, wodurch die Sache uneinheitlich wurde.
Wenn du dir vor dem Abschluss dieses Commits ein Bild davon machen willst, was tatsächlich auf der einen oder anderen Stufe geändert wurde, kannst du mit git diff vergleichen, was sich in deinem Arbeitsverzeichnis befindet, das du als Ergebnis der Zusammenführung in einer dieser Stufen übergeben willst.
Wir können sie alle nacheinander durchspielen.
Um das Resultat mit dem zu vergleichen, was du vor dem Merge in deinem Branch hattest oder anders gesagt, um herauszufinden, was durch den Merge entstanden ist, kannst du git diff --ours folgendermaßen ausführen:
$ git diff --ours
* Unmerged path hello.rb
diff --git a/hello.rb b/hello.rb
index 36c06c8..44d0a25 100755
--- a/hello.rb
+++ b/hello.rb
@@ -2,7 +2,7 @@
# prints out a greeting
def hello
- puts 'hello world'
+ puts 'hello mundo'
end
hello()Hier können wir leicht erkennen, dass das, was in unserem Branch entstanden ist, was wir mit diesem Merge eigentlich in diese Datei aufnehmen, diese einzelne Zeile ändert.
Wenn man sehen will, wie sich das Ergebnis des merges von dem unterscheidet, was in der Remote-Version war, kannst du git diff --theirs nutzen.
In diesem und dem folgenden Beispiel müssen wir -b verwenden, um die Leerzeichen zu löschen. Wir vergleichen das Ergebnis mit dem, was in Git enthalten ist, nicht mit der bereinigten Datei hello.theirs.rb.
$ git diff --theirs -b
* Unmerged path hello.rb
diff --git a/hello.rb b/hello.rb
index e85207e..44d0a25 100755
--- a/hello.rb
+++ b/hello.rb
@@ -1,5 +1,6 @@
#! /usr/bin/env ruby
+# prints out a greeting
def hello
puts 'hello mundo'
endSchließlich kannst du mit git diff --base sehen, wie sich die Datei beiderseits geändert hat.
$ git diff --base -b
* Unmerged path hello.rb
diff --git a/hello.rb b/hello.rb
index ac51efd..44d0a25 100755
--- a/hello.rb
+++ b/hello.rb
@@ -1,7 +1,8 @@
#! /usr/bin/env ruby
+# prints out a greeting
def hello
- puts 'hello world'
+ puts 'hello mundo'
end
hello()An diesem Punkt können wir mit dem Befehl git clean die zusätzlichen Dateien löschen, die wir für den manuellen Merge angelegt haben und nicht mehr benötigen.
$ git clean -f
Removing hello.common.rb
Removing hello.ours.rb
Removing hello.theirs.rbDie Konflikte austesten
Womöglich sind wir aus irgendeinem Grund nicht zufrieden mit der vorliegenden Lösung oder die manuelle Korrektur einer oder beider Seiten hat noch immer nicht gut funktioniert und wir benötigen weitere Informationen.
Lass uns das Beispiel etwas verändern. Hier haben wir zwei schon länger existierende Branches, die jeweils einige Commits enthalten, aber bei einem Merge einen begründeten inhaltlichen Konflikt erzeugen.
$ git log --graph --oneline --decorate --all
* f1270f7 (HEAD, master) Update README
* 9af9d3b Create README
* 694971d Update phrase to 'hola world'
| * e3eb223 (mundo) Add more tests
| * 7cff591 Create initial testing script
| * c3ffff1 Change text to 'hello mundo'
|/
* b7dcc89 Initial hello world codeWir haben jetzt drei individuelle Commits, die nur auf dem Branch master existieren und drei weitere, die auf dem Branch mundo liegen.
Wenn wir nun versuchen, den mundo Branch zu integrieren, bekommen wir einen Konflikt.
$ git merge mundo
Auto-merging hello.rb
CONFLICT (content): Merge conflict in hello.rb
Automatic merge failed; fix conflicts and then commit the result.Wir möchten jetzt wissen, was den Merge-Konflikt verursacht. Beim Öffnen der Datei sehen wir etwas wie das hier:
#! /usr/bin/env ruby
def hello
<<<<<<< HEAD
puts 'hola world'
=======
puts 'hello mundo'
>>>>>>> mundo
end
hello()Beide Seiten des Merges haben dieser Datei inhaltlich etwas verändert. Manche der Commits haben die Datei jedoch an gleicher Stelle verändert, wodurch dieser Konflikt entstanden ist.
Lass uns einige Tools näher betrachten, die dir zur Verfügung stehen, um herauszufinden, wie es zu diesem Konflikt gekommen ist. Vielleicht ist es nicht ganz eindeutig, wie genau du diesen Konflikt lösen solltest. Du benötigst weitere Informationen.
Ein hilfreiches Werkzeug ist die Funktion git checkout mit der Option --conflict.
Dadurch wird die Datei erneut ausgecheckt und die Konfliktmarkierungen für den Merge-Prozess ersetzt.
Das kann praktisch sein, wenn du die Markierungen zurücksetzen und erneut versuchen willst, sie aufzulösen.
Du kannst mit --conflict die Werte diff3 oder merge (der Default-Wert) übergeben.
Wenn du diff3 übergibst, wird Git eine etwas andere Variante von Konfliktmarkern verwenden und dir nicht nur die „ours“ and „theirs“ Version, sondern auch die „base“-Version mit zur Verfügung stellen, um dir mehr Kontext zu geben.
$ git checkout --conflict=diff3 hello.rbDanach sollte die Datei wie folgt aussehen:
#! /usr/bin/env ruby
def hello
<<<<<<< ours
puts 'hola world'
||||||| base
puts 'hello world'
=======
puts 'hello mundo'
>>>>>>> theirs
end
hello()Wenn dir dieses Format gefällt, kannst du es als Standard für zukünftige Merge-Konflikte festlegen, indem du die Einstellung merge.conflictstyle auf diff3 setzt.
$ git config --global merge.conflictstyle diff3Der Befehl git checkout kann auch die Optionen --ours und --theirs nutzen, wodurch man sehr schnell entweder nur die eine oder die andere Seite wählen kann, ohne die beiden Seiten zu vermischen.
Das kann speziell bei Konflikten mit Binärdateien nützlich sein, bei denen du einfach die eine Seite wählen kannst oder bei denen du nur bestimmte Dateien aus einem anderen Branch einbinden willst. Du kannst den Merge starten und dann bestimmte Dateien von der einen oder anderen Seite auschecken, bevor du sie committest.
Merge-Protokoll
Ein weiteres nützliches Werkzeug bei der Lösung von Merge-Konflikten ist git log.
So kannst du den Bezug zu dem herstellen, was zu den Konflikten beigetragen haben könnte.
Es ist manchmal sehr nützlich, die Historie ein wenig Revue passieren zu lassen, um sich zu erinnern, warum zwei Entwicklungslinien den gleichen Bereich des Quellcodes tangieren.
Um eine vollständige Liste aller eindeutigen Commits zu erhalten, die in den beiden an dieser Zusammenführung beteiligten Branches enthalten waren, können wir die „triple dot“-Syntax verwenden, die wir in Dreifacher Punkt kennengelernt haben.
$ git log --oneline --left-right HEAD...MERGE_HEAD
< f1270f7 Update README
< 9af9d3b Create README
< 694971d Update phrase to 'hola world'
> e3eb223 Add more tests
> 7cff591 Create initial testing script
> c3ffff1 Change text to 'hello mundo'Das ist eine detaillierte Liste der insgesamt sechs beteiligten Commits und der Entwicklungslinie, in der jeder Commit erfolgte.
Wir können das aber noch weiter vereinfachen, um uns einen viel spezifischeren Hintergrund zu geben.
Fügen wir die Option --merge zu git log hinzu, zeigt sie nur die Commits auf beiden Seiten des Merges an, die eine Datei betreffen, bei der ein Konflikt vorliegt.
$ git log --oneline --left-right --merge
< 694971d Update phrase to 'hola world'
> c3ffff1 Change text to 'hello mundo'Wenn du diesen Befehl stattdessen mit der Option -p ausführst, erhältst du nur die Diffs zu der Datei, die in Konflikt steht.
Das kann äußerst wertvoll sein, um dir schnell den notwendigen Kontext zu liefern. So kannst du besser verstehen, warum sich etwas in Widerspruch befindet und wie du es auf intelligentere Weise auflösen kannst.
Kombiniertes Diff-Format
Da Git alle Ergebnisse der erfolgreichen Merges staged, wenn du git diff ausführst, solange du dich in einem Merge-Konflikt-Zustand befindest, wird nur das angezeigt, was derzeit auch tatsächlich noch im Konflikt steht.
Das hilft dir beim Erkennen der noch zu lösenden Fehler.
Wenn du git diff direkt nach einem Merge-Konflikt ausführst, erhältst du Informationen in einem ziemlich eindeutigen diff-Ausgabeformat.
$ git diff
diff --cc hello.rb
index 0399cd5,59727f0..0000000
--- a/hello.rb
+++ b/hello.rb
@@@ -1,7 -1,7 +1,11 @@@
#! /usr/bin/env ruby
def hello
++<<<<<<< HEAD
+ puts 'hola world'
++=======
+ puts 'hello mundo'
++>>>>>>> mundo
end
hello()Das Format wird „Combined Diff“ genannt und liefert dir zwei Datenspalten neben jeder Zeile. Die erste Spalte zeigt dir an, ob diese Zeile zwischen dem Branch „ours“ und der Datei in deinem Arbeitsverzeichnis unterschiedlich (hinzugefügt oder gelöscht) ist. Die zweite Spalte macht das Gleiche zwischen dem Branch „theirs“ und deiner Kopie des Arbeitsverzeichnisses.
In diesem Beispiel kannst du sehen, dass die Zeilen <<<<<<<<< und >>>>>>>> in der Arbeitskopie sind, aber nicht auf beiden Seiten des Merges stehen.
Das macht Sinn, weil das Merge-Tool sie für unseren Kontext dort eingefügt hat. Es wird aber von uns erwartet, dass wir sie wieder entfernen.
Wenn der Konflikt gelöst wird und wir wieder git diff laufen lassen, werden wir dasselbe sehen, nun allerdings etwas hilfreicher.
$ vim hello.rb
$ git diff
diff --cc hello.rb
index 0399cd5,59727f0..0000000
--- a/hello.rb
+++ b/hello.rb
@@@ -1,7 -1,7 +1,7 @@@
#! /usr/bin/env ruby
def hello
- puts 'hola world'
- puts 'hello mundo'
++ puts 'hola mundo'
end
hello()Das zeigt uns, dass „hola world“ auf unserer Seite enthalten war, aber nicht in der Arbeitskopie, dass „hello mundo“ auf deren Seite, aber nicht in der Arbeitskopie war, und schließlich, dass „hola mundo“ auf keiner Seite existierte, aber jetzt in der Arbeitskopie ist. Es kann sinnvoll sein, dieses vor dem Committen der Lösung zu überprüfen.
Das kannst du auch aus dem git log für jeden Merge entnehmen, um zu verfolgen, wie etwas im Anschluss daran gelöst wurde.
Git wird dieses Format dann ausgeben, wenn du git show bei einem Merge-Commit ausführst oder wenn du die Option --cc zu einem git log -p hinzufügst (welches standardmäßig nur Patches für Non-Merge-Commits anzeigt).
$ git log --cc -p -1
commit 14f41939956d80b9e17bb8721354c33f8d5b5a79
Merge: f1270f7 e3eb223
Author: Scott Chacon <schacon@gmail.com>
Date: Fri Sep 19 18:14:49 2014 +0200
Merge branch 'mundo'
Conflicts:
hello.rb
diff --cc hello.rb
index 0399cd5,59727f0..e1d0799
--- a/hello.rb
+++ b/hello.rb
@@@ -1,7 -1,7 +1,7 @@@
#! /usr/bin/env ruby
def hello
- puts 'hola world'
- puts 'hello mundo'
++ puts 'hola mundo'
end
hello()Merges annullieren
Nachdem du jetzt weißt, wie man einen Merge-Commit erstellt, wirst du vermutlich ein paar davon versehentlich machen. Eine der besten Eigenschaften von Git ist, dass es völlig in Ordnung ist, Fehler zu machen. Es ist immer möglich ist, sie rückgängig zu machen (und in vielen Fällen ist das auch sehr leicht).
Merge-Commits sind da keine Ausnahme.
Angenommen, du hast mit der Arbeit an einem Feature-Branch begonnen, ihn versehentlich in master gemerged und jetzt sieht deine Commit-Historie so aus:
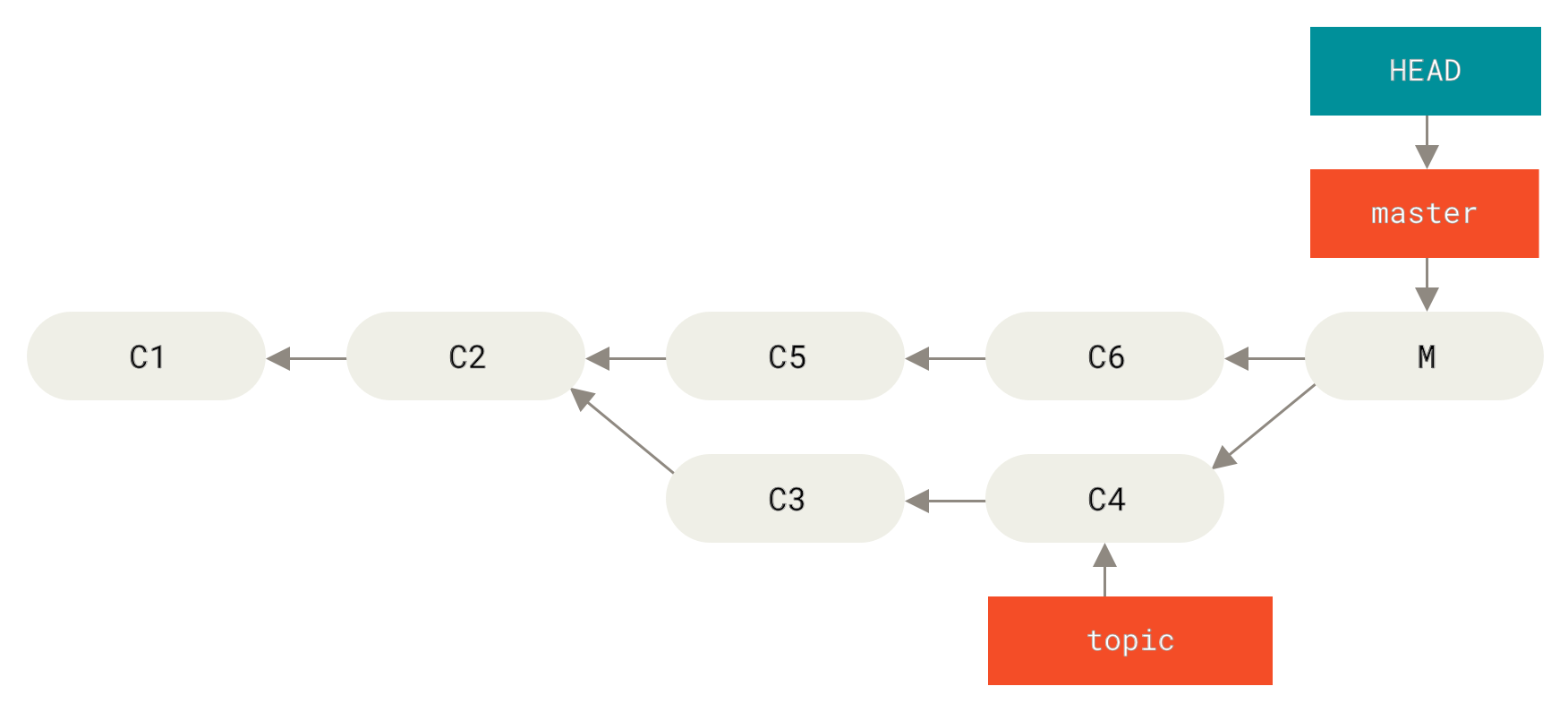
Es gibt zwei Möglichkeiten, dieses Problem zu lösen, je nachdem, welches Ergebnis du dir vorstellst.
Reparieren der Referenzen
Wenn der unerwünschte Merge-Commit nur auf deinem lokalen Repository existiert, ist die einfachste und beste Lösung, die Branches so zu verschieben, dass sie dorthin zeigen, wo du sie haben wolltest.
Meistens, wenn dem irrtümlichen git merge ein git reset --hard HEAD~ folgt, wird das die Branch-Pointer zurücksetzen, so dass sie wie folgt aussehen:
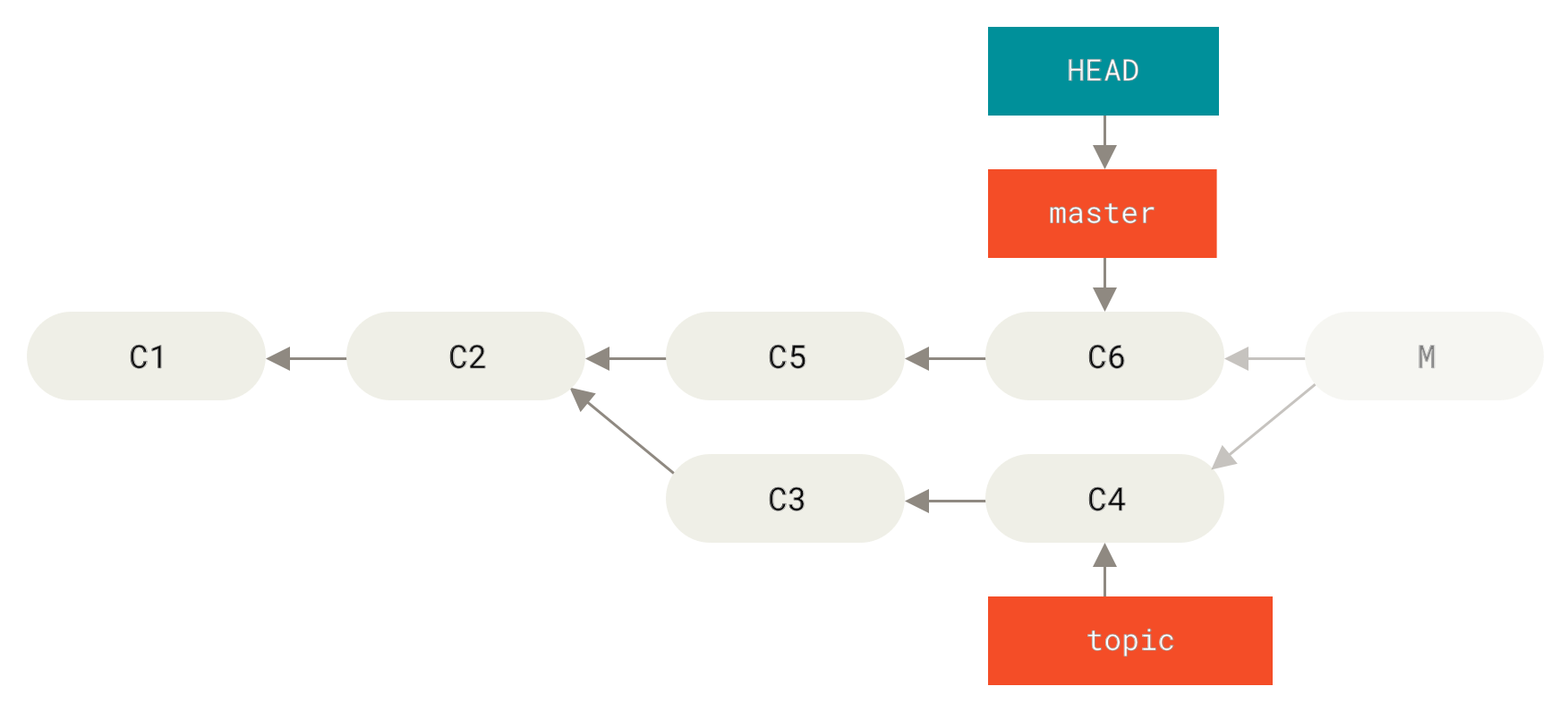
git reset --hard HEAD~
Wir haben bereits in Reset entzaubert über reset geschrieben, also sollte es nicht allzu schwer sein, zu verstehen, was hier passiert.
Hier nur zur Erinnerung: reset --hard durchläuft normalerweise drei Phasen:
-
Verschieben, wohin der Branch HEAD zeigt. Hier wollen wir
masterdorthin verschieben, wo er vor dem Merge-Commit stand (C6). -
Den Index wie HEAD aussehen lassen.
-
Das Arbeitsverzeichnis an den Index anpassen.
Der Nachteil dieser Vorgehensweise ist, dass der Verlauf umgeschrieben wird, was mit einem gemeinsam genutzten Repository problematisch sein kann.
Sieh dir Die Gefahren des Rebasing an, um Näheres zu erfahren, was passieren kann. Die Kurzfassung ist: Wenn andere Benutzer Commits vorliegen haben, die du gerade umschreiben willst, dann solltest du besser ein reset vermeiden.
Dieser Vorgang wird auch dann nicht funktionieren, wenn seit dem Merge weitere Commits erstellt wurden. Ein Verschieben der Refs würde zum Verlust diese Änderungen führen.
Den Commit umkehren
Falls das Verschieben der Branch-Pointer für dich nicht in Frage kommt, bietet dir Git die Option, einen neuen Commit durchzuführen, der alle Änderungen eines bestehenden Commits rückgängig macht. Git nennt diese Operation „revert“. In diesem konkreten Szenario würdest du sie wie folgt aufrufen:
$ git revert -m 1 HEAD
[master b1d8379] Revert "Merge branch 'topic'"Das -m 1 Flag gibt an, welches Elternteil auf der „Hauptlinie“ ist und beibehalten werden sollte.
Wenn du einen Merge zu HEAD (git merge topic) startest, hat der neue Commit zwei Elternteile: der erste ist HEAD (C6), und der zweite ist das Ende des Branchs, der gemerged wird (C4).
Hier wollen wir alle Änderungen rückgängig machen, die durch das Mergen im übergeordneten Teil #2 (C4) vorgenommen wurden, wobei der gesamte Inhalt des übergeordneten Teils #1 (C6) beibehalten wird.
Der Verlauf mit dem Revert-Commit sieht so aus:
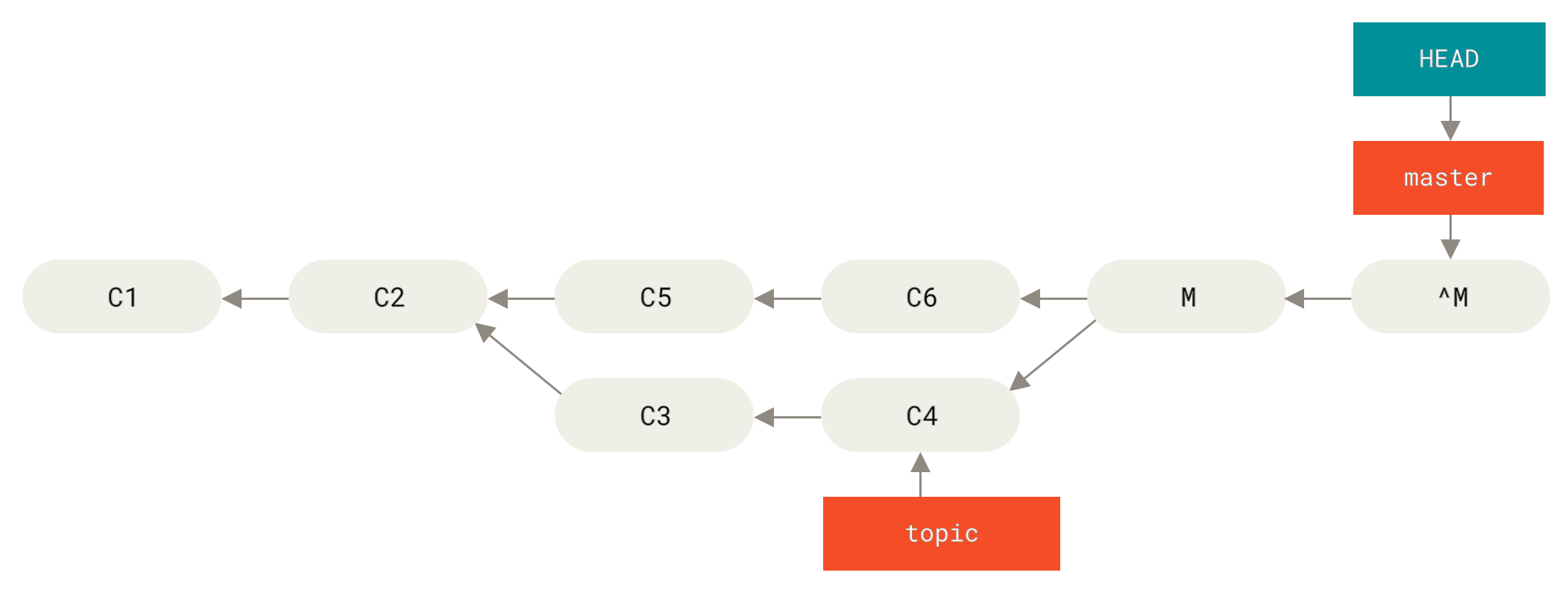
git revert -m 1
Der neue Commit ^M hat genau den gleichen Inhalt wie C6, so dass es von hier an so aussieht, als ob der Merge nie stattgefunden hätte, außer dass die jetzt nicht mehr gemergeten Commits noch im Verlauf von HEAD stehen.
Git würde verwirrt werden, wenn du erneut versuchen solltest, topic in master zu mergen:
$ git merge topic
Already up-to-date.Es gibt nichts in topic, was nicht schon von master aus erreichbar wäre.
Was viel schlimmer wäre, wenn du Arbeiten zu topic beitragen und erneut mergen sollst. Dann wird Git nur die Änderungen seit dem rückgängig gemachten Merge vornehmen:
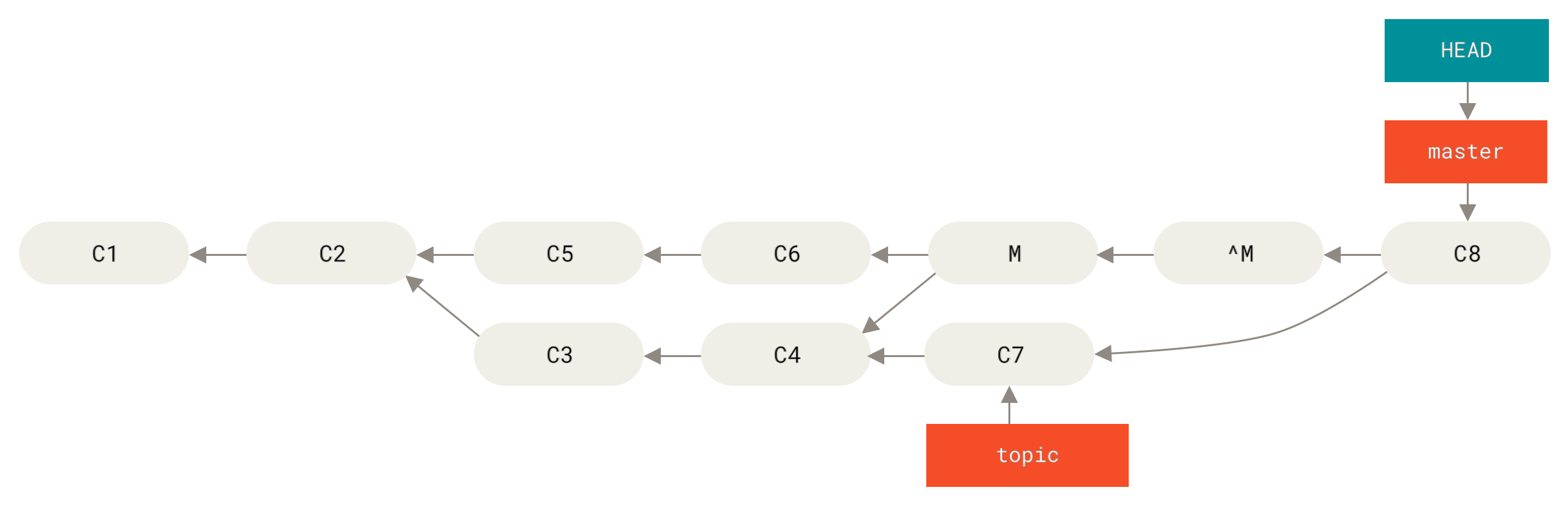
Der optimale Weg dies zu umgehen besteht darin, den ursprüngliche Merge rückgängig zu machen. Da du jetzt die Änderungen übernehmen möchtest, die annulliert wurden, erstellst du dann einen neuen Merge-Commit:
$ git revert ^M
[master 09f0126] Revert "Revert "Merge branch 'topic'""
$ git merge topic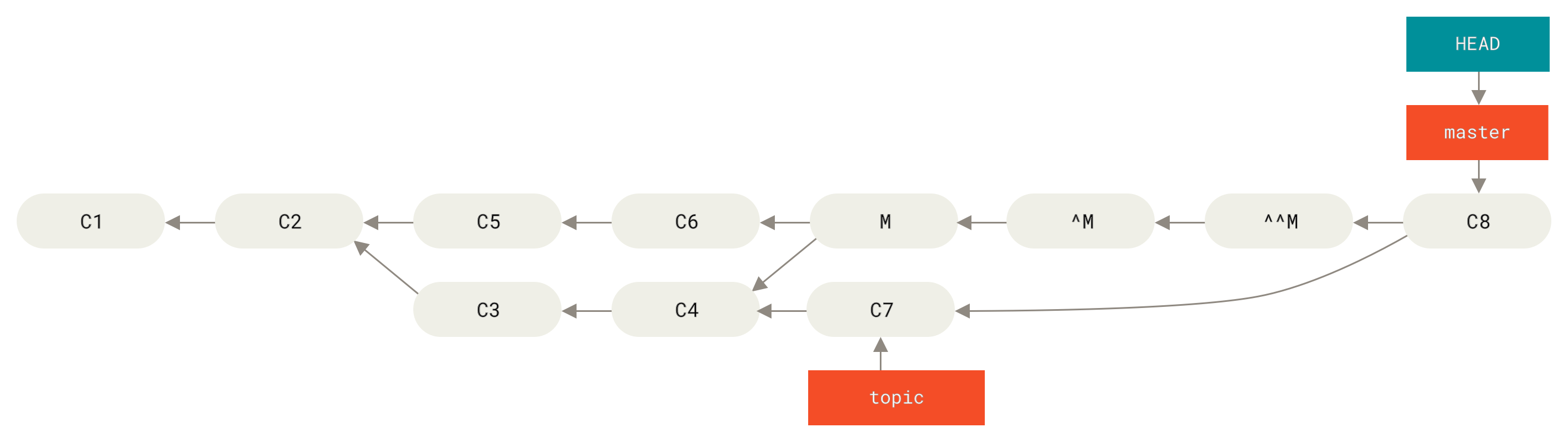
In diesem Beispiel heben sich M und ^M gegenseitig auf.
Der Commit ^^M merged wirksam mit den Änderungen von C3 und C4, und C8 merged mit den Änderungen von C7, so dass jetzt das topic vollständig gemerged ist.
Andere Arten von Merges
Bisher haben wir den normalen Merge von zwei Branches behandelt, der normalerweise mit der so genannten "rekursiven" Strategie des Mergens bearbeitet wird. Es gibt jedoch auch andere Möglichkeiten, um Branches miteinander zu mergen. Lass uns kurz einige davon untersuchen.
Unsere oder deren Präferenz
Erstens, es gibt noch eine weitere praktische Funktion, die wir mit dem normalen „rekursiven“ Modus des Merging anwenden können.
Wir haben uns bereits die Optionen ignore-all-space und ignore-space-change angesehen, die mit -X übergeben werden. Wir können Git aber auch anweisen, die eine oder die andere Seite zu bevorzugen, falls ein Konflikt auftritt.
Wenn Git einen Konflikt zwischen zwei zu mergende Branches feststellt, fügt es standardmäßig Konfliktmarkierungen in deinem Code ein und markiert die Datei als im Konflikt stehend und ermöglicht dir, den Konflikt zu beheben.
Solltest du es vorziehen, dass Git einfach eine bestimmte Version auswählt und die andere ignorieren soll, anstatt dich den Konflikt manuell auflösen zu lassen, kannst du den merge Befehl entweder mit -Xours oder -Xtheirs übergeben.
Erkennt Git diese Einstellung, wird es keine Konfliktmarkierungen hinzufügen. Alle miteinander in Einklang zu bringenden Abweichungen werden gemerged. Bei allen sich widersprechenden Änderungen wird einfach die von dir angegebene Version ausgewählt, einschließlich binärer Dateien.
Wenn wir auf das „hello world“-Beispiel zurückkommen, das wir zuvor benutzt haben, können wir erkennen, dass der Merge in unserem Branch Konflikte verursacht.
$ git merge mundo
Auto-merging hello.rb
CONFLICT (content): Merge conflict in hello.rb
Resolved 'hello.rb' using previous resolution.
Automatic merge failed; fix conflicts and then commit the result.Wenn wir das Beispiel aber mit -Xours oder -Xtheirs ausführen, dann funktioniert das Merging.
$ git merge -Xours mundo
Auto-merging hello.rb
Merge made by the 'recursive' strategy.
hello.rb | 2 +-
test.sh | 2 ++
2 files changed, 3 insertions(+), 1 deletion(-)
create mode 100644 test.shDann würden keine Konfliktmarkierungen bei „hello mundo“ auf der einen Seite und „hola world“ auf der anderen in die Datei eingefügt, sondern einfach „hola world“ übernommen. Alle anderen, konfliktfreien Änderungen auf dieser Branch werden jedoch korrekt in die Version aufgenommen.
Diese Option kann auch an den Befehl git merge-file übergeben werden, den wir weiter oben beschrieben haben, als wir git merge-file --ours für individuelle Datei-Merges ausgeführt haben.
Wenn man so etwas machen will, aber Git nicht einmal versucht, Änderungen von der anderen Seite einzubinden, gibt es eine drastischere Option, nämlich die „ours“ Merge-Strategie. Die unterscheidet sich von der rekursiven, „ours“ Merge-Option.
Dadurch wird eigentlich ein Schein-Merge ausgeführt. Es wird ein neuer Merge-Commit mit beiden Branches als Elternteil protokolliert, aber es wird noch nicht einmal der betreffende Branch angesehen. Als Ergebnis des Merges wird einfach der exakte Code in deinem aktuellen Branch gespeichert.
$ git merge -s ours mundo
Merge made by the 'ours' strategy.
$ git diff HEAD HEAD~
$Du kannst erkennen, dass es keinen Unterschied zwischen dem Branch, auf dem wir uns befanden und dem Resultat des Merges gibt.
Oft kann das nützlich sein, um Git bei einem späteren Merge im Grunde zu täuschen, dass ein Branch bereits gemerged ist.
Nehmen wir zum Beispiel an, du hast einen Branch release abgespalten und dort einige Änderungen vorgenommen, die du irgendwann wieder in deinem Branch master integrieren möchtest.
Zwischenzeitlich müssen einige Bugfixes auf master in deinem Branch release zurückportiert werden.
Du kannst den Bugfix-Branch in den Branch release mergen und ebenso den gleichen Branch mit merge -s ours in deinem master Branch mergen (auch wenn der Fix bereits vorhanden ist). Wenn du später den release Branch wieder mergst, gibt es keine Konflikte durch den Bugfix.
Subtree Merging
Der Grundgedanke des Teilbaum-Merge (engl. Subtree-Merge) besteht darin, dass du zwei Projekte hast und eines der Projekte auf ein Unterverzeichnis des anderen Projekts verweist. Wenn du einen Teilbaum-Merge durchführst, ist Git so versiert zu erkennen, dass das ein Unterverzeichnis ein Teilbaum des anderen ist und es entsprechend merged.
Wir werden ein Beispiel durcharbeiten, bei dem ein separates Projekt in ein bestehendes Projekt eingefügt und dann der Code des zweiten Projekts in ein Unterverzeichnis des ersten Projekts gemerged wird.
Zunächst werden wir die Anwendung „Rack“ zu unserem Projekt hinzufügen. Wir werden das Rack-Projekt in unserem eigenen Projekt als Remote-Referenz einbinden und es dann in einem eigenen Branch auschecken:
$ git remote add rack_remote https://github.com/rack/rack
$ git fetch rack_remote --no-tags
warning: no common commits
remote: Counting objects: 3184, done.
remote: Compressing objects: 100% (1465/1465), done.
remote: Total 3184 (delta 1952), reused 2770 (delta 1675)
Receiving objects: 100% (3184/3184), 677.42 KiB | 4 KiB/s, done.
Resolving deltas: 100% (1952/1952), done.
From https://github.com/rack/rack
* [new branch] build -> rack_remote/build
* [new branch] master -> rack_remote/master
* [new branch] rack-0.4 -> rack_remote/rack-0.4
* [new branch] rack-0.9 -> rack_remote/rack-0.9
$ git checkout -b rack_branch rack_remote/master
Branch rack_branch set up to track remote branch refs/remotes/rack_remote/master.
Switched to a new branch "rack_branch"Jetzt haben wir das Root-Verzeichnis des Rack-Projekts in unserem rack_branch und unser eigenes Projekt im master Branch.
Wenn du die beiden Branches prüfst, kannst du sehen, dass sie unterschiedliche Projekt-Roots haben:
$ ls
AUTHORS KNOWN-ISSUES Rakefile contrib lib
COPYING README bin example test
$ git checkout master
Switched to branch "master"
$ ls
READMEDas ist irgendwie ein merkwürdiges Konzept. Nicht alle Branches in deinem Repository müssen unbedingt Branches desselben Projektes sein. Es ist nicht allgemein üblich, weil es selten hilfreich ist. Allerdings ist es ziemlich wahrscheinlich, dass die Branches völlig unterschiedliche Verläufe enthalten.
In unserem Fall wollen wir das Rack-Projekt als Unterverzeichnis in unser Projekt master einbringen.
Das können wir in Git mit git read-tree tun.
Mehr über den Befehl read-tree und seiner Verwandten erfährst du in Git Interna. Vorab solltest du erfahren, dass er den Root-Tree eines Branchs in deine aktuelle Staging-Area und dein aktuelles Arbeitsverzeichnis einliest.
Wir sind gerade zu deinem Branch master zurückgewechselt und ziehen den Branch rack_branch in das Unterverzeichnis rack unseres master Branchs des Hauptprojektes:
$ git read-tree --prefix=rack/ -u rack_branchBei einem Commit sieht es so aus, als befänden sich alle Rack-Dateien unterhalb dieses Unterverzeichnisses — als ob wir sie aus einem Tarball hineinkopiert hätten. Interessant ist, dass wir Änderungen in einem der Branches relativ leicht mit anderen Branches mergen können. Falls das Rack-Projekt aktualisiert wird, können wir die Änderungen einbinden, indem wir zu diesem Branch wechseln und pullen:
$ git checkout rack_branch
$ git pullDann können wir diese Änderungen wieder in unserem Branch master zusammenführen.
Um die Änderungen zu pullen und die Commit-Nachricht vorzubereiten, verwendet man die Option --squash sowie die Option -Xsubtree der rekursiven Merge-Strategie.
Die rekursive Strategie ist hier die Voreinstellung, aber wir fügen sie der Klarheit halber ein.
$ git checkout master
$ git merge --squash -s recursive -Xsubtree=rack rack_branch
Squash commit -- not updating HEAD
Automatic merge went well; stopped before committing as requestedAlle Änderungen aus dem Rack-Projekt werden in das Projekt gemerged und können lokal committet werden.
Du kannst auch das Gegenteil tun — Änderungen im Unterverzeichnis rack deines master Branchs vornehmen und sie dann später in deinem Branch rack_branch mergen, um sie den Autoren zu übermitteln oder sie zum Upstream zu pushen.
Dadurch haben wir einen Workflow, der dem Submodul-Workflow ähnelt, ohne Submodule zu verwenden (die wir in Submodule behandeln werden). Wir können Branches mit anderen verwandten Projekten in unserem Repository vorhalten und sie gelegentlich in unserem Projekt mergen. In gewisser Weise ist das nützlich. Beispielsweise kann der gesamte Code an einen einzigen Ort übermittelt werden. Allerdings gibt es auch Nachteile. Es ist etwas komplizierter und somit leichter, Fehler bei der Re-Integration von Änderungen zu machen oder versehentlich einen Branch in ein nicht relevantes Repository zu pushen.
Eine weitere etwas eigenartige Eigenschaft ist, dass du den Unterschied zwischen dem, was in deinem Unterverzeichnis rack steht, und dem Code in deinem Branch rack_branch nicht mit dem normalen diff Befehl erhalten können (um zu prüfen, ob du sie mergen musst).
Stattdessen musst du git diff-tree auf dem Branch, mit dem du vergleichen willst, ausführen:
$ git diff-tree -p rack_branchUm den Inhalt deines rack Unterverzeichnisses mit dem Branch master auf dem Remote-Server zu vergleichen, kannst du auch folgendes ausführen:
$ git diff-tree -p rack_remote/master