
-
1. Pierwsze kroki
- 1.1 Wprowadzenie do kontroli wersji
- 1.2 Krótka historia Git
- 1.3 Podstawy Git
- 1.4 Linia poleceń
- 1.5 Instalacja Git
- 1.6 Wstępna konfiguracja Git
- 1.7 Uzyskiwanie pomocy
- 1.8 Podsumowanie
-
2. Podstawy Gita
- 2.1 Pierwsze repozytorium Gita
- 2.2 Rejestrowanie zmian w repozytorium
- 2.3 Podgląd historii rewizji
- 2.4 Cofanie zmian
- 2.5 Praca ze zdalnym repozytorium
- 2.6 Tagowanie
- 2.7 Aliasy
- 2.8 Podsumowanie
-
3. Gałęzie Gita
- 3.1 Czym jest gałąź
- 3.2 Podstawy rozgałęziania i scalania
- 3.3 Zarządzanie gałęziami
- 3.4 Sposoby pracy z gałęziami
- 3.5 Gałęzie zdalne
- 3.6 Zmiana bazy
- 3.7 Podsumowanie
-
4. Git na serwerze
- 4.1 Protokoły
- 4.2 Uruchomienie Git na serwerze
- 4.3 Generowanie Twojego publicznego klucza SSH
- 4.4 Konfigurowanie serwera
- 4.5 Git Daemon
- 4.6 Smart HTTP
- 4.7 GitWeb
- 4.8 GitLab
- 4.9 Inne opcje hostowania przez podmioty zewnętrzne
- 4.10 Podsumowanie
-
5. Rozproszony Git
-
6. GitHub
-
7. Narzędzia Gita
- 7.1 Wskazywanie rewizji
- 7.2 Interaktywne używanie przechowali
- 7.3 Schowek i czyszczenie
- 7.4 Signing Your Work
- 7.5 Searching
- 7.6 Przepisywanie historii
- 7.7 Reset Demystified
- 7.8 Advanced Merging
- 7.9 Rerere
- 7.10 Debugowanie z Gitem
- 7.11 Moduły zależne
- 7.12 Bundling
- 7.13 Replace
- 7.14 Credential Storage
- 7.15 Podsumowanie
-
8. Dostosowywanie Gita
- 8.1 Konfiguracja Gita
- 8.2 Git Attributes
- 8.3 Git Hooks
- 8.4 An Example Git-Enforced Policy
- 8.5 Summary
-
9. Git i inne systemy
- 9.1 Git jako klient
- 9.2 Migracja do Gita
- 9.3 Podsumowanie
-
10. Mechanizmy wewnętrzne w Git
- 10.1 Komendy typu plumbing i porcelain
- 10.2 Obiekty Gita
- 10.3 Referencje w Git
- 10.4 Spakowane pliki (packfiles)
- 10.5 Refspec
- 10.6 Protokoły transferu
- 10.7 Konserwacja i odzyskiwanie danych
- 10.8 Environment Variables
- 10.9 Podsumowanie
-
A1. Appendix A: Git in Other Environments
- A1.1 Graphical Interfaces
- A1.2 Git in Visual Studio
- A1.3 Git in Eclipse
- A1.4 Git in Bash
- A1.5 Git in Zsh
- A1.6 Git in Powershell
- A1.7 Summary
-
A2. Appendix B: Embedding Git in your Applications
- A2.1 Command-line Git
- A2.2 Libgit2
- A2.3 JGit
-
A3. Appendix C: Git Commands
- A3.1 Setup and Config
- A3.2 Getting and Creating Projects
- A3.3 Basic Snapshotting
- A3.4 Branching and Merging
- A3.5 Sharing and Updating Projects
- A3.6 Inspection and Comparison
- A3.7 Debugging
- A3.8 Patching
- A3.9 Email
- A3.10 External Systems
- A3.11 Administration
- A3.12 Plumbing Commands
7.8 Narzędzia Gita - Advanced Merging
Advanced Merging
Merging in Git is typically fairly easy. Since Git makes it easy to merge another branch multiple times, it means that you can have a very long lived branch but you can keep it up to date as you go, solving small conflicts often, rather than be surprised by one enormous conflict at the end of the series.
However, sometimes tricky conflicts do occur. Unlike some other version control systems, Git does not try to be overly clever about merge conflict resolution. Git’s philosophy is to be smart about determining when a merge resolution is unambiguous, but if there is a conflict, it does not try to be clever about automatically resolving it. Therefore, if you wait too long to merge two branches that diverge quickly, you can run into some issues.
In this section, we’ll go over what some of those issues might be and what tools Git gives you to help handle these more tricky situations. We’ll also cover some of the different, non-standard types of merges you can do, as well as see how to back out of merges that you’ve done.
Merge Conflicts
While we covered some basics on resolving merge conflicts in Podstawowe konflikty scalania, for more complex conflicts, Git provides a few tools to help you figure out what’s going on and how to better deal with the conflict.
First of all, if at all possible, try to make sure your working directory is clean before doing a merge that may have conflicts. If you have work in progress, either commit it to a temporary branch or stash it. This makes it so that you can undo anything you try here. If you have unsaved changes in your working directory when you try a merge, some of these tips may help you lose that work.
Let’s walk through a very simple example. We have a super simple Ruby file that prints hello world.
#! /usr/bin/env ruby
def hello
puts 'hello world'
end
hello()In our repository, we create a new branch named whitespace and proceed to change all the Unix line endings to DOS line endings, essentially changing every line of the file, but just with whitespace. Then we change the line “hello world” to “hello mundo”.
$ git checkout -b whitespace
Switched to a new branch 'whitespace'
$ unix2dos hello.rb
unix2dos: converting file hello.rb to DOS format ...
$ git commit -am 'converted hello.rb to DOS'
[whitespace 3270f76] converted hello.rb to DOS
1 file changed, 7 insertions(+), 7 deletions(-)
$ vim hello.rb
$ git diff -b
diff --git a/hello.rb b/hello.rb
index ac51efd..e85207e 100755
--- a/hello.rb
+++ b/hello.rb
@@ -1,7 +1,7 @@
#! /usr/bin/env ruby
def hello
- puts 'hello world'
+ puts 'hello mundo'^M
end
hello()
$ git commit -am 'hello mundo change'
[whitespace 6d338d2] hello mundo change
1 file changed, 1 insertion(+), 1 deletion(-)Now we switch back to our master branch and add some documentation for the function.
$ git checkout master
Switched to branch 'master'
$ vim hello.rb
$ git diff
diff --git a/hello.rb b/hello.rb
index ac51efd..36c06c8 100755
--- a/hello.rb
+++ b/hello.rb
@@ -1,5 +1,6 @@
#! /usr/bin/env ruby
+# prints out a greeting
def hello
puts 'hello world'
end
$ git commit -am 'document the function'
[master bec6336] document the function
1 file changed, 1 insertion(+)Now we try to merge in our whitespace branch and we’ll get conflicts because of the whitespace changes.
$ git merge whitespace
Auto-merging hello.rb
CONFLICT (content): Merge conflict in hello.rb
Automatic merge failed; fix conflicts and then commit the result.Aborting a Merge
We now have a few options. First, let’s cover how to get out of this situation. If you perhaps weren’t expecting conflicts and don’t want to quite deal with the situation yet, you can simply back out of the merge with git merge --abort.
$ git status -sb
## master
UU hello.rb
$ git merge --abort
$ git status -sb
## masterThe git merge --abort option tries to revert back to your state before you ran the merge. The only cases where it may not be able to do this perfectly would be if you had unstashed, uncommitted changes in your working directory when you ran it, otherwise it should work fine.
If for some reason you find yourself in a horrible state and just want to start over, you can also run git reset --hard HEAD or wherever you want to get back to. Remember again that this will blow away your working directory, so make sure you don’t want any changes there.
Ignoring Whitespace
In this specific case, the conflicts are whitespace related. We know this because the case is simple, but it’s also pretty easy to tell in real cases when looking at the conflict because every line is removed on one side and added again on the other. By default, Git sees all of these lines as being changed, so it can’t merge the files.
The default merge strategy can take arguments though, and a few of them are about properly ignoring whitespace changes. If you see that you have a lot of whitespace issues in a merge, you can simply abort it and do it again, this time with -Xignore-all-space or -Xignore-space-change. The first option ignores whitespace completely when comparing lines, the second treats sequences of one or more whitespace characters as equivalent.
$ git merge -Xignore-space-change whitespace
Auto-merging hello.rb
Merge made by the 'recursive' strategy.
hello.rb | 2 +-
1 file changed, 1 insertion(+), 1 deletion(-)Since in this case, the actual file changes were not conflicting, once we ignore the whitespace changes, everything merges just fine.
This is a lifesaver if you have someone on your team who likes to occasionally reformat everything from spaces to tabs or vice-versa.
Manual File Re-merging
Though Git handles whitespace pre-processing pretty well, there are other types of changes that perhaps Git can’t handle automatically, but are scriptable fixes. As an example, let’s pretend that Git could not handle the whitespace change and we needed to do it by hand.
What we really need to do is run the file we’re trying to merge in through a dos2unix program before trying the actual file merge. So how would we do that?
First, we get into the merge conflict state. Then we want to get copies of my version of the file, their version (from the branch we’re merging in) and the common version (from where both sides branched off). Then we want to fix up either their side or our side and re-try the merge again for just this single file.
Getting the three file versions is actually pretty easy. Git stores all of these versions in the index under “stages” which each have numbers associated with them. Stage 1 is the common ancestor, stage 2 is your version and stage 3 is from the MERGE_HEAD, the version you’re merging in (“theirs”).
You can extract a copy of each of these versions of the conflicted file with the git show command and a special syntax.
$ git show :1:hello.rb > hello.common.rb
$ git show :2:hello.rb > hello.ours.rb
$ git show :3:hello.rb > hello.theirs.rbIf you want to get a little more hard core, you can also use the ls-files -u plumbing command to get the actual SHA-1s of the Git blobs for each of these files.
$ git ls-files -u
100755 ac51efdc3df4f4fd328d1a02ad05331d8e2c9111 1 hello.rb
100755 36c06c8752c78d2aff89571132f3bf7841a7b5c3 2 hello.rb
100755 e85207e04dfdd5eb0a1e9febbc67fd837c44a1cd 3 hello.rbThe :1:hello.rb is just a shorthand for looking up that blob SHA-1.
Now that we have the content of all three stages in our working directory, we can manually fix up theirs to fix the whitespace issue and re-merge the file with the little-known git merge-file command which does just that.
$ dos2unix hello.theirs.rb
dos2unix: converting file hello.theirs.rb to Unix format ...
$ git merge-file -p \
hello.ours.rb hello.common.rb hello.theirs.rb > hello.rb
$ git diff -b
diff --cc hello.rb
index 36c06c8,e85207e..0000000
--- a/hello.rb
+++ b/hello.rb
@@@ -1,8 -1,7 +1,8 @@@
#! /usr/bin/env ruby
+# prints out a greeting
def hello
- puts 'hello world'
+ puts 'hello mundo'
end
hello()At this point we have nicely merged the file. In fact, this actually works better than the ignore-space-change option because this actually fixes the whitespace changes before merge instead of simply ignoring them. In the ignore-space-change merge, we actually ended up with a few lines with DOS line endings, making things mixed.
If you want to get an idea before finalizing this commit about what was actually changed between one side or the other, you can ask git diff to compare what is in your working directory that you’re about to commit as the result of the merge to any of these stages. Let’s go through them all.
To compare your result to what you had in your branch before the merge, in other words, to see what the merge introduced, you can run git diff --ours
$ git diff --ours
* Unmerged path hello.rb
diff --git a/hello.rb b/hello.rb
index 36c06c8..44d0a25 100755
--- a/hello.rb
+++ b/hello.rb
@@ -2,7 +2,7 @@
# prints out a greeting
def hello
- puts 'hello world'
+ puts 'hello mundo'
end
hello()So here we can easily see that what happened in our branch, what we’re actually introducing to this file with this merge, is changing that single line.
If we want to see how the result of the merge differed from what was on their side, you can run git diff --theirs. In this and the following example, we have to use -b to strip out the whitespace because we’re comparing it to what is in Git, not our cleaned up hello.theirs.rb file.
$ git diff --theirs -b
* Unmerged path hello.rb
diff --git a/hello.rb b/hello.rb
index e85207e..44d0a25 100755
--- a/hello.rb
+++ b/hello.rb
@@ -1,5 +1,6 @@
#! /usr/bin/env ruby
+# prints out a greeting
def hello
puts 'hello mundo'
endFinally, you can see how the file has changed from both sides with git diff --base.
$ git diff --base -b
* Unmerged path hello.rb
diff --git a/hello.rb b/hello.rb
index ac51efd..44d0a25 100755
--- a/hello.rb
+++ b/hello.rb
@@ -1,7 +1,8 @@
#! /usr/bin/env ruby
+# prints out a greeting
def hello
- puts 'hello world'
+ puts 'hello mundo'
end
hello()At this point we can use the git clean command to clear out the extra files we created to do the manual merge but no longer need.
$ git clean -f
Removing hello.common.rb
Removing hello.ours.rb
Removing hello.theirs.rbChecking Out Conflicts
Perhaps we’re not happy with the resolution at this point for some reason, or maybe manually editing one or both sides still didn’t work well and we need more context.
Let’s change up the example a little. For this example, we have two longer lived branches that each have a few commits in them but create a legitimate content conflict when merged.
$ git log --graph --oneline --decorate --all
* f1270f7 (HEAD, master) update README
* 9af9d3b add a README
* 694971d update phrase to hola world
| * e3eb223 (mundo) add more tests
| * 7cff591 add testing script
| * c3ffff1 changed text to hello mundo
|/
* b7dcc89 initial hello world codeWe now have three unique commits that live only on the master branch and three others that live on the mundo branch. If we try to merge the mundo branch in, we get a conflict.
$ git merge mundo
Auto-merging hello.rb
CONFLICT (content): Merge conflict in hello.rb
Automatic merge failed; fix conflicts and then commit the result.We would like to see what the merge conflict is. If we open up the file, we’ll see something like this:
#! /usr/bin/env ruby
def hello
<<<<<<< HEAD
puts 'hola world'
=======
puts 'hello mundo'
>>>>>>> mundo
end
hello()Both sides of the merge added content to this file, but some of the commits modified the file in the same place that caused this conflict.
Let’s explore a couple of tools that you now have at your disposal to determine how this conflict came to be. Perhaps it’s not obvious how exactly you should fix this conflict. You need more context.
One helpful tool is git checkout with the ‘--conflict’ option. This will re-checkout the file again and replace the merge conflict markers. This can be useful if you want to reset the markers and try to resolve them again.
You can pass --conflict either diff3 or merge (which is the default). If you pass it diff3, Git will use a slightly different version of conflict markers, not only giving you the “ours” and “theirs” versions, but also the “base” version inline to give you more context.
$ git checkout --conflict=diff3 hello.rbOnce we run that, the file will look like this instead:
#! /usr/bin/env ruby
def hello
<<<<<<< ours
puts 'hola world'
||||||| base
puts 'hello world'
=======
puts 'hello mundo'
>>>>>>> theirs
end
hello()If you like this format, you can set it as the default for future merge conflicts by setting the merge.conflictstyle setting to diff3.
$ git config --global merge.conflictstyle diff3The git checkout command can also take --ours and --theirs options, which can be a really fast way of just choosing either one side or the other without merging things at all.
This can be particularly useful for conflicts of binary files where you can simply choose one side, or where you only want to merge certain files in from another branch - you can do the merge and then checkout certain files from one side or the other before committing.
Merge Log
Another useful tool when resolving merge conflicts is git log. This can help you get context on what may have contributed to the conflicts. Reviewing a little bit of history to remember why two lines of development were touching the same area of code can be really helpful sometimes.
To get a full list of all of the unique commits that were included in either branch involved in this merge, we can use the “triple dot” syntax that we learned in Potrójna kropka.
$ git log --oneline --left-right HEAD...MERGE_HEAD
< f1270f7 update README
< 9af9d3b add a README
< 694971d update phrase to hola world
> e3eb223 add more tests
> 7cff591 add testing script
> c3ffff1 changed text to hello mundoThat’s a nice list of the six total commits involved, as well as which line of development each commit was on.
We can further simplify this though to give us much more specific context. If we add the --merge option to git log, it will only show the commits in either side of the merge that touch a file that’s currently conflicted.
$ git log --oneline --left-right --merge
< 694971d update phrase to hola world
> c3ffff1 changed text to hello mundoIf you run that with the -p option instead, you get just the diffs to the file that ended up in conflict. This can be really helpful in quickly giving you the context you need to help understand why something conflicts and how to more intelligently resolve it.
Combined Diff Format
Since Git stages any merge results that are successful, when you run git diff while in a conflicted merge state, you only get what is currently still in conflict. This can be helpful to see what you still have to resolve.
When you run git diff directly after a merge conflict, it will give you information in a rather unique diff output format.
$ git diff
diff --cc hello.rb
index 0399cd5,59727f0..0000000
--- a/hello.rb
+++ b/hello.rb
@@@ -1,7 -1,7 +1,11 @@@
#! /usr/bin/env ruby
def hello
++<<<<<<< HEAD
+ puts 'hola world'
++=======
+ puts 'hello mundo'
++>>>>>>> mundo
end
hello()The format is called “Combined Diff” and gives you two columns of data next to each line. The first column shows you if that line is different (added or removed) between the “ours” branch and the file in your working directory and the second column does the same between the “theirs” branch and your working directory copy.
So in that example you can see that the <<<<<<< and >>>>>>> lines are in the working copy but were not in either side of the merge. This makes sense because the merge tool stuck them in there for our context, but we’re expected to remove them.
If we resolve the conflict and run git diff again, we’ll see the same thing, but it’s a little more useful.
$ vim hello.rb
$ git diff
diff --cc hello.rb
index 0399cd5,59727f0..0000000
--- a/hello.rb
+++ b/hello.rb
@@@ -1,7 -1,7 +1,7 @@@
#! /usr/bin/env ruby
def hello
- puts 'hola world'
- puts 'hello mundo'
++ puts 'hola mundo'
end
hello()This shows us that “hola world” was in our side but not in the working copy, that “hello mundo” was in their side but not in the working copy and finally that “hola mundo” was not in either side but is now in the working copy. This can be useful to review before committing the resolution.
You can also get this from the git log for any merge after the fact to see how something was resolved after the fact. Git will output this format if you run git show on a merge commit, or if you add a --cc option to a git log -p (which by default only shows patches for non-merge commits).
$ git log --cc -p -1
commit 14f41939956d80b9e17bb8721354c33f8d5b5a79
Merge: f1270f7 e3eb223
Author: Scott Chacon <schacon@gmail.com>
Date: Fri Sep 19 18:14:49 2014 +0200
Merge branch 'mundo'
Conflicts:
hello.rb
diff --cc hello.rb
index 0399cd5,59727f0..e1d0799
--- a/hello.rb
+++ b/hello.rb
@@@ -1,7 -1,7 +1,7 @@@
#! /usr/bin/env ruby
def hello
- puts 'hola world'
- puts 'hello mundo'
++ puts 'hola mundo'
end
hello()Undoing Merges
Now that you know how to create a merge commit, you’ll probably make some by mistake. One of the great things about working with Git is that it’s okay to make mistakes, because it’s possible (and in many cases easy) to fix them.
Merge commits are no different.
Let’s say you started work on a topic branch, accidentally merged it into master, and now your commit history looks like this:
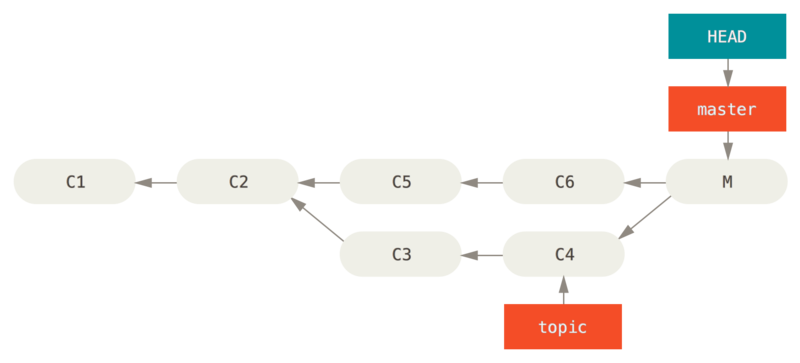
There are two ways to approach this problem, depending on what your desired outcome is.
Fix the references
If the unwanted merge commit only exists on your local repository, the easiest and best solution is to move the branches so that they point where you want them to.
In most cases, if you follow the errant git merge with git reset --hard HEAD~, this will reset the branch pointers so they look like this:
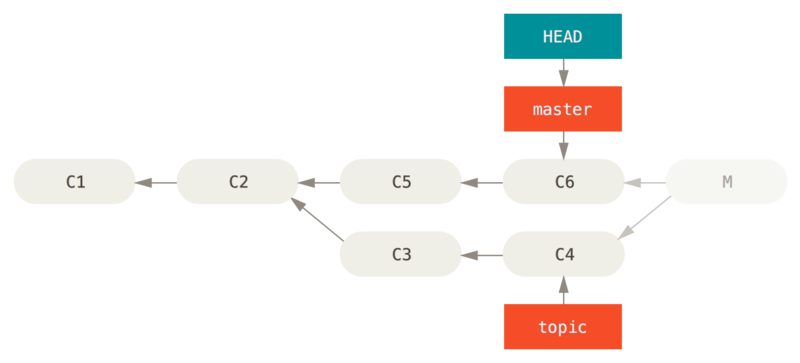
git reset --hard HEAD~
We covered reset back in Reset Demystified, so it shouldn’t be too hard to figure out what’s going on here.
Here’s a quick refresher: reset --hard usually goes through three steps:
-
Move the branch HEAD points to. In this case, we want to move
masterto where it was before the merge commit (C6). -
Make the index look like HEAD.
-
Make the working directory look like the index.
The downside of this approach is that it’s rewriting history, which can be problematic with a shared repository.
Check out Zagrożenia operacji zmiany bazy for more on what can happen; the short version is that if other people have the commits you’re rewriting, you should probably avoid reset.
This approach also won’t work if any other commits have been created since the merge; moving the refs would effectively lose those changes.
Reverse the commit
If moving the branch pointers around isn’t going to work for you, Git gives you the option of making a new commit which undoes all the changes from an existing one. Git calls this operation a “revert”, and in this particular scenario, you’d invoke it like this:
$ git revert -m 1 HEAD
[master b1d8379] Revert "Merge branch 'topic'"The -m 1 flag indicates which parent is the “mainline” and should be kept.
When you invoke a merge into HEAD (git merge topic), the new commit has two parents: the first one is HEAD (C6), and the second is the tip of the branch being merged in (C4).
In this case, we want to undo all the changes introduced by merging in parent #2 (C4), while keeping all the content from parent #1 (C6).
The history with the revert commit looks like this:
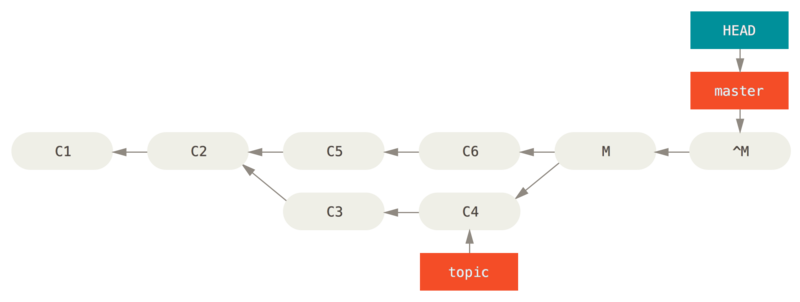
git revert -m 1
The new commit ^M has exactly the same contents as C6, so starting from here it’s as if the merge never happened, except that the now-unmerged commits are still in HEAD's history.
Git will get confused if you try to merge topic into master again:
$ git merge topic
Already up-to-date.There’s nothing in topic that isn’t already reachable from master.
What’s worse, if you add work to topic and merge again, Git will only bring in the changes since the reverted merge:
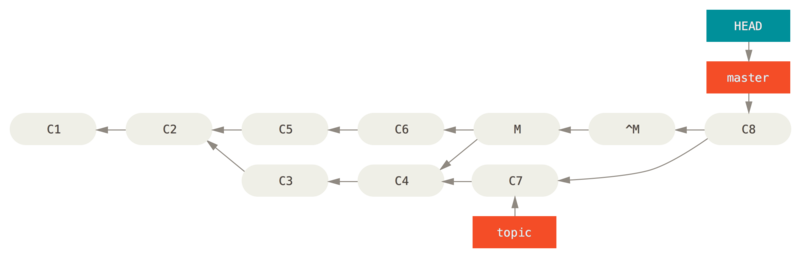
The best way around this is to un-revert the original merge, since now you want to bring in the changes that were reverted out, then create a new merge commit:
$ git revert ^M
[master 09f0126] Revert "Revert "Merge branch 'topic'""
$ git merge topic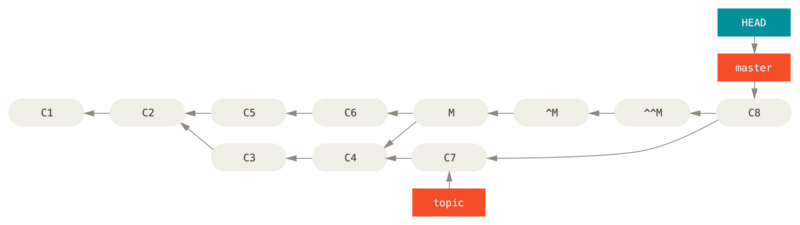
In this example, M and ^M cancel out.
^^M effectively merges in the changes from C3 and C4, and C8 merges in the changes from C7, so now topic is fully merged.
Other Types of Merges
So far we’ve covered the normal merge of two branches, normally handled with what is called the “recursive” strategy of merging. There are other ways to merge branches together however. Let’s cover a few of them quickly.
Our or Theirs Preference
First of all, there is another useful thing we can do with the normal “recursive” mode of merging. We’ve already seen the ignore-all-space and ignore-space-change options which are passed with a -X but we can also tell Git to favor one side or the other when it sees a conflict.
By default, when Git sees a conflict between two branches being merged, it will add merge conflict markers into your code and mark the file as conflicted and let you resolve it. If you would prefer for Git to simply choose a specific side and ignore the other side instead of letting you manually merge the conflict, you can pass the merge command either a -Xours or -Xtheirs.
If Git sees this, it will not add conflict markers. Any differences that are mergeable, it will merge. Any differences that conflict, it will simply choose the side you specify in whole, including binary files.
If we go back to the “hello world” example we were using before, we can see that merging in our branch causes conflicts.
$ git merge mundo
Auto-merging hello.rb
CONFLICT (content): Merge conflict in hello.rb
Resolved 'hello.rb' using previous resolution.
Automatic merge failed; fix conflicts and then commit the result.However if we run it with -Xours or -Xtheirs it does not.
$ git merge -Xours mundo
Auto-merging hello.rb
Merge made by the 'recursive' strategy.
hello.rb | 2 +-
test.sh | 2 ++
2 files changed, 3 insertions(+), 1 deletion(-)
create mode 100644 test.shIn that case, instead of getting conflict markers in the file with “hello mundo” on one side and “hola world” on the other, it will simply pick “hola world”. However, all the other non-conflicting changes on that branch are merged successfully in.
This option can also be passed to the git merge-file command we saw earlier by running something like git merge-file --ours for individual file merges.
If you want to do something like this but not have Git even try to merge changes from the other side in, there is a more draconian option, which is the “ours” merge strategy. This is different from the “ours” recursive merge option.
This will basically do a fake merge. It will record a new merge commit with both branches as parents, but it will not even look at the branch you’re merging in. It will simply record as the result of the merge the exact code in your current branch.
$ git merge -s ours mundo
Merge made by the 'ours' strategy.
$ git diff HEAD HEAD~
$You can see that there is no difference between the branch we were on and the result of the merge.
This can often be useful to basically trick Git into thinking that a branch is already merged when doing a merge later on. For example, say you branched off a “release” branch and have done some work on it that you will want to merge back into your “master” branch at some point. In the meantime some bugfix on “master” needs to be backported into your release branch. You can merge the bugfix branch into the release branch and also merge -s ours the same branch into your master branch (even though the fix is already there) so when you later merge the release branch again, there are no conflicts from the bugfix.
Subtree Merging
The idea of the subtree merge is that you have two projects, and one of the projects maps to a subdirectory of the other one and vice versa. When you specify a subtree merge, Git is often smart enough to figure out that one is a subtree of the other and merge appropriately.
We’ll go through an example of adding a separate project into an existing project and then merging the code of the second into a subdirectory of the first.
First, we’ll add the Rack application to our project. We’ll add the Rack project as a remote reference in our own project and then check it out into its own branch:
$ git remote add rack_remote https://github.com/rack/rack
$ git fetch rack_remote
warning: no common commits
remote: Counting objects: 3184, done.
remote: Compressing objects: 100% (1465/1465), done.
remote: Total 3184 (delta 1952), reused 2770 (delta 1675)
Receiving objects: 100% (3184/3184), 677.42 KiB | 4 KiB/s, done.
Resolving deltas: 100% (1952/1952), done.
From https://github.com/rack/rack
* [new branch] build -> rack_remote/build
* [new branch] master -> rack_remote/master
* [new branch] rack-0.4 -> rack_remote/rack-0.4
* [new branch] rack-0.9 -> rack_remote/rack-0.9
$ git checkout -b rack_branch rack_remote/master
Branch rack_branch set up to track remote branch refs/remotes/rack_remote/master.
Switched to a new branch "rack_branch"Now we have the root of the Rack project in our rack_branch branch and our own project in the master branch.
If you check out one and then the other, you can see that they have different project roots:
$ ls
AUTHORS KNOWN-ISSUES Rakefile contrib lib
COPYING README bin example test
$ git checkout master
Switched to branch "master"
$ ls
READMEThis is sort of a strange concept. Not all the branches in your repository actually have to be branches of the same project. It’s not common, because it’s rarely helpful, but it’s fairly easy to have branches contain completely different histories.
In this case, we want to pull the Rack project into our master project as a subdirectory.
We can do that in Git with git read-tree.
You’ll learn more about read-tree and its friends in Mechanizmy wewnętrzne w Git, but for now know that it reads the root tree of one branch into your current staging area and working directory.
We just switched back to your master branch, and we pull the rack_branch branch into the rack subdirectory of our master branch of our main project:
$ git read-tree --prefix=rack/ -u rack_branchWhen we commit, it looks like we have all the Rack files under that subdirectory – as though we copied them in from a tarball. What gets interesting is that we can fairly easily merge changes from one of the branches to the other. So, if the Rack project updates, we can pull in upstream changes by switching to that branch and pulling:
$ git checkout rack_branch
$ git pullThen, we can merge those changes back into our master branch.
To pull in the changes and prepopulate the commit message, use the --squash option, as well as the recursive merge strategy’s -Xsubtree option. (The recursive strategy is the default here, but we include it for clarity.)
$ git checkout master
$ git merge --squash -s recursive -Xsubtree=rack rack_branch
Squash commit -- not updating HEAD
Automatic merge went well; stopped before committing as requestedAll the changes from the Rack project are merged in and ready to be committed locally.
You can also do the opposite – make changes in the rack subdirectory of your master branch and then merge them into your rack_branch branch later to submit them to the maintainers or push them upstream.
This gives us a way to have a workflow somewhat similar to the submodule workflow without using submodules (which we will cover in Moduły zależne). We can keep branches with other related projects in our repository and subtree merge them into our project occasionally. It is nice in some ways, for example all the code is committed to a single place. However, it has other drawbacks in that it’s a bit more complex and easier to make mistakes in reintegrating changes or accidentally pushing a branch into an unrelated repository.
Another slightly weird thing is that to get a diff between what you have in your rack subdirectory and the code in your rack_branch branch – to see if you need to merge them – you can’t use the normal diff command.
Instead, you must run git diff-tree with the branch you want to compare to:
$ git diff-tree -p rack_branchOr, to compare what is in your rack subdirectory with what the master branch on the server was the last time you fetched, you can run
$ git diff-tree -p rack_remote/master