
-
1. Erste Schritte
-
2. Git Grundlagen
-
3. Git Branching
- 3.1 Branches auf einen Blick
- 3.2 Einfaches Branching und Merging
- 3.3 Branch-Management
- 3.4 Branching-Workflows
- 3.5 Remote-Branches
- 3.6 Rebasing
- 3.7 Zusammenfassung
-
4. Git auf dem Server
- 4.1 Die Protokolle
- 4.2 Git auf einem Server einrichten
- 4.3 Erstellung eines SSH-Public-Keys
- 4.4 Einrichten des Servers
- 4.5 Git-Daemon
- 4.6 Smart HTTP
- 4.7 GitWeb
- 4.8 GitLab
- 4.9 Von Drittanbietern gehostete Optionen
- 4.10 Zusammenfassung
-
5. Verteiltes Git
-
6. GitHub
-
7. Git Tools
- 7.1 Revisions-Auswahl
- 7.2 Interaktives Stagen
- 7.3 Stashen und Bereinigen
- 7.4 Deine Arbeit signieren
- 7.5 Suchen
- 7.6 Den Verlauf umschreiben
- 7.7 Reset entzaubert
- 7.8 Fortgeschrittenes Merging
- 7.9 Rerere
- 7.10 Debuggen mit Git
- 7.11 Submodule
- 7.12 Bundling
- 7.13 Replace (Ersetzen)
- 7.14 Anmeldeinformationen speichern
- 7.15 Zusammenfassung
-
8. Git einrichten
- 8.1 Git Konfiguration
- 8.2 Git-Attribute
- 8.3 Git Hooks
- 8.4 Beispiel für Git-forcierte Regeln
- 8.5 Zusammenfassung
-
9. Git und andere VCS-Systeme
- 9.1 Git als Client
- 9.2 Migration zu Git
- 9.3 Zusammenfassung
-
10. Git Interna
-
A1. Anhang A: Git in anderen Umgebungen
- A1.1 Grafische Schnittstellen
- A1.2 Git in Visual Studio
- A1.3 Git in Visual Studio Code
- A1.4 Git in IntelliJ / PyCharm / WebStorm / PhpStorm / RubyMine
- A1.5 Git in Sublime Text
- A1.6 Git in Bash
- A1.7 Git in Zsh
- A1.8 Git in PowerShell
- A1.9 Zusammenfassung
-
A2. Anhang B: Git in deine Anwendungen einbetten
- A2.1 Die Git-Kommandozeile
- A2.2 Libgit2
- A2.3 JGit
- A2.4 go-git
- A2.5 Dulwich
-
A3. Anhang C: Git Kommandos
- A3.1 Setup und Konfiguration
- A3.2 Projekte importieren und erstellen
- A3.3 Einfache Snapshot-Funktionen
- A3.4 Branching und Merging
- A3.5 Projekte gemeinsam nutzen und aktualisieren
- A3.6 Kontrollieren und Vergleichen
- A3.7 Debugging
- A3.8 Patchen bzw. Fehlerkorrektur
- A3.9 E-mails
- A3.10 Externe Systeme
- A3.11 Administration
- A3.12 Basisbefehle
1.3 Erste Schritte - Was ist Git?
Was ist Git?
Also, was ist Git denn nun? Dies ist ein wichtiger Teil, den es zu beachten gilt, denn wenn du verstehst, was Git und das grundlegenden Konzept seiner Arbeitsweise ist, dann wird die effektive Nutzung von Git für dich wahrscheinlich viel einfacher sein. Wenn du Git erlernst, solltest du versuchen, deinen Kopf von den Dingen zu befreien, die du über andere VCSs, wie CVS, Subversion oder Perforce, weist. Das wird dir helfen, unangenehme Missverständnisse bei der Verwendung des Tools zu vermeiden. Auch wenn die Benutzeroberfläche von Git den VCSs sehr ähnlich ist, speichert und betrachtet Git Informationen auf eine ganz andere Weise, und das Verständnis dieser Unterschiede hilft dir Unklarheiten bei der Verwendung zu vermeiden.
Snapshots statt Unterschiede
Der Hauptunterschied zwischen Git und anderen Versionsverwaltungssystemen (insbesondere auch Subversion und vergleichbaren Systemen) besteht in der Art und Weise wie Git die Daten betrachtet. Konzeptionell speichern die meisten anderen Systeme Informationen als eine Liste dateibasierter Änderungen. Diese Systeme (CVS, Subversion, Perforce, Bazaar usw.) betrachtet die Informationen, die sie verwaltet, als eine Reihe von Dateien an denen im Laufe der Zeit Änderungen vorgenommen werden (dies wird allgemein als deltabasierte Versionskontrolle bezeichnet).
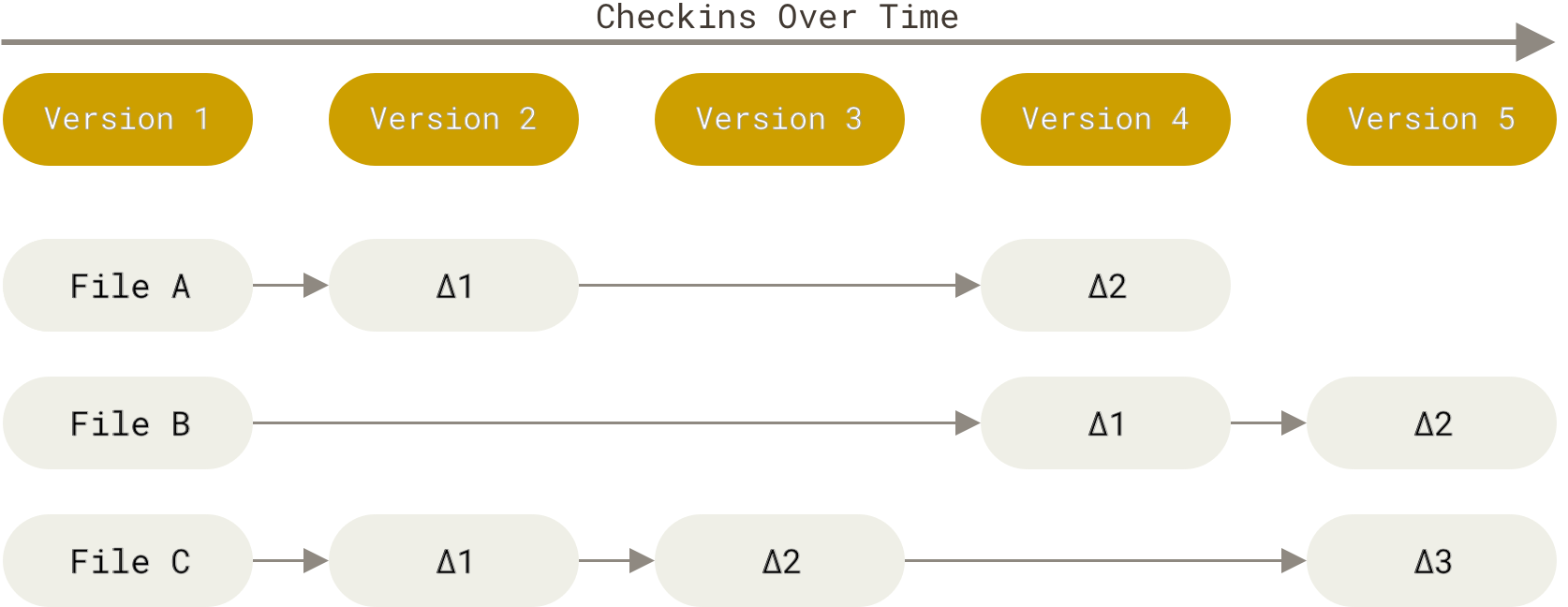
Git arbeitet nicht auf diese Art. Stattdessen betrachtet Git seine Daten eher wie eine Reihe von Schnappschüssen eines Mini-Dateisystems. Git macht jedes Mal, wenn du den Status deines Projekts committest (das heißt den gegenwärtigen Status deines Projekts als eine Version in Git speicherst) ein Abbild von all deinen Dateien wie sie gerade aussehen und speichert einen Verweis in diesem Schnappschuss. Um dies möglichst effizient und schnell tun zu können, kopiert Git unveränderte Dateien nicht, sondern legt lediglich eine Verknüpfung zu der vorherigen Version der Datei an. Git betrachtet seine Daten eher als einen Stapel von Schnappschüssen.
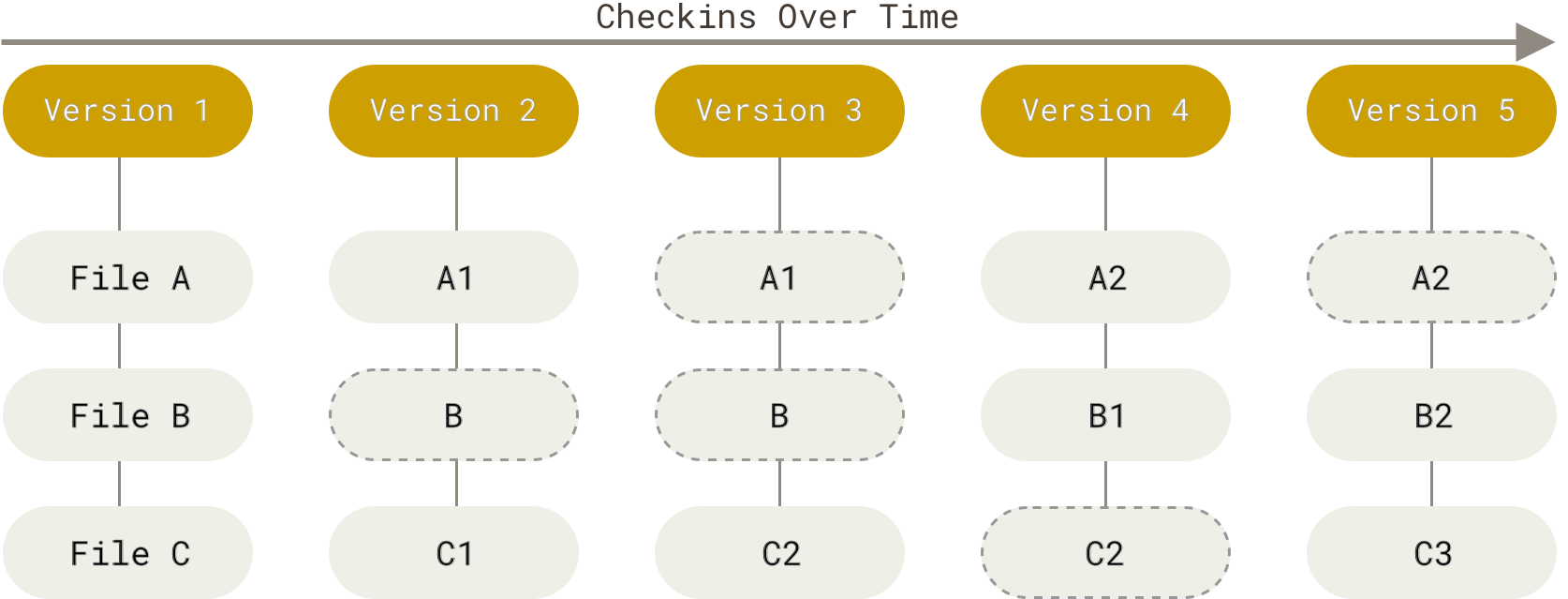
Das ist ein wichtiger Unterschied zwischen Git und praktisch allen anderen Versionsverwaltungssystemen. In Git wurden fast alle Aspekte der Versionsverwaltung neu überdacht, die in anderen Systemen mehr oder weniger von ihrer jeweiligen Vorgängergeneration übernommen worden waren. Git arbeitet im Großen und Ganzen eher wie ein mit einigen unglaublich mächtigen Werkzeugen ausgerüstetes Mini-Dateisystem, statt nur als Versionsverwaltungssystem. Auf einige der Vorteile, die es mit sich bringt, Daten in dieser Weise zu verwalten, werden wir in Kapitel 3, Git Branching, eingehen, wenn wir das Git Branching-Konzept kennenlernen.
Fast jede Funktion arbeitet lokal
Die meisten Aktionen in Git benötigen nur lokale Dateien und Ressourcen, um ausgeführt zu werden – im Allgemeinen werden keine Informationen von einem anderen Computer in deinem Netzwerk benötigt. Wenn du mit einem CVCS vertraut bist, bei dem die meisten Operationen durch Netzwerk-Latenzen langsam sind, dann wird diese Eigenschaft von Git glauben lassen, dass Git von mit übernatürlichen Kräften bedacht wurde. Die allermeisten Operationen können nahezu ohne jede Verzögerung ausgeführt werden, da die vollständige Historie eines Projekts bereits auf dem jeweiligen Rechner verfügbar ist.
Um beispielsweise die Historie des Projekts zu durchsuchen, braucht Git sie nicht von einem externen Server zu holen – es liest diese einfach aus der lokalen Datenbank. Das heißt, die vollständige Projekthistorie ist ohne jede Verzögerung verfügbar. Wenn man sich die Änderungen einer aktuellen Version einer Datei im Vergleich zu der vor einem Monat anschauen möchte, dann kann Git den Stand von vor einem Monat in der lokalen Historie nachschlagen und einen lokalen Vergleich zur vorliegenden Datei durchführen. Für diesen Anwendungsfall benötigt Git keinen externen Server, weder um Dateien dort nachzuschlagen, noch um Unterschiede zu finden.
Das bedeutet natürlich außerdem, dass es fast nichts gibt, was man nicht tun kann, nur weil man gerade offline ist oder keinen Zugriff auf ein VPN hat. Wenn man also gerade im Flugzeug oder Zug ein wenig arbeiten will, kann man problemlos seine Arbeit einchecken und dann, wenn man wieder mit einem Netzwerk verbunden ist, die Dateien auf den Server hochladen. Wenn man zu Hause sitzt, aber der VPN-Client gerade mal wieder nicht funktioniert, kann man immer noch arbeiten. Bei vielen anderen Systemen wäre dies unmöglich oder äußerst kompliziert umzusetzen. In Perforce kannst du beispielsweise nicht viel tun, wenn du nicht mit dem Server verbunden bist; in Subversion und CVS kannst du Dateien bearbeiten, aber du kannst keine Änderungen zu deinen Daten übertragen (weil die Datenbank offline ist). Das scheint keine große Sache zu sein, aber du wirst überrascht sein, was für einen großen Unterschied das machen kann.
Git stellt Integrität sicher
Von allen zu speichernden Daten berechnet Git Prüfsummen (engl. checksum) und speichert diese als Referenz zusammen mit den Daten ab. Das macht es unmöglich, dass sich Inhalte von Dateien oder Verzeichnissen ändern, ohne dass Git das mitbekommt. Git basiert auf dieser Funktionalität und sie ist ein integraler Teil der Git-Philosophie. Man kann Informationen deshalb z.B. nicht während der Übermittlung verlieren oder unwissentlich beschädigte Dateien verwenden, ohne dass Git in der Lage wäre, dies festzustellen.
Der Mechanismus, den Git verwendet, um diese Prüfsummen zu erstellen, heißt SHA-1-Hash. Eine solche Prüfsumme ist eine 40-Zeichen lange Zeichenkette, die aus hexadezimalen Zeichen (0-9 und a-f) besteht. Sie wird von Git aus den Inhalten einer Datei oder Verzeichnisstruktur berechnet. Ein SHA-1-Hash sieht wie folgt aus:
24b9da6552252987aa493b52f8696cd6d3b00373Diese Hashes begegnen einem überall bei der Arbeit, weil sie so ausgiebig von Git genutzt werden. Tatsächlich speichert Git alles in seiner Datenbank nicht nach Dateinamen, sondern nach dem Hash-Wert seines Inhalts.
Git fügt im Regelfall nur Daten hinzu
Wenn du Aktionen in Git durchführen, werden diese fast immer nur Daten zur Git-Datenbank hinzufügen. Deshalb ist es sehr schwer, das System dazu zu bewegen, irgendetwas zu tun, das nicht wieder rückgängig zu machen ist, oder dazu, Daten in irgendeiner Form zu löschen. Wie in jedem anderen VCS, kann man in Git Daten verlieren oder durcheinander bringen, solange man sie noch nicht eingecheckt hat. Aber sobald man einen Schnappschuss in Git eingecheckt hat, ist es sehr schwierig, diese Daten wieder zu verlieren, insbesondere wenn man regelmäßig seine lokale Datenbank auf ein anderes Repository hochlädt.
Unter anderem deshalb macht es so viel Spaß mit Git zu arbeiten. Man weiß genau, man kann ein wenig experimentieren, ohne befürchten zu müssen, irgendetwas zu zerstören oder durcheinander zu bringen. Wer sich genauer dafür interessiert, wie Git Daten speichert und wie man Daten, die scheinbar verloren sind, wiederherstellen kann, dem sei das Kapitel 2, Ungewollte Änderungen rückgängig machen, ans Herz gelegt.
Die drei Zustände
Jetzt heißt es aufgepasst! Es folgt die wichtigste Information, die man sich merken muss, wenn man Git erlernen und dabei Fallstricke vermeiden will. Git definiert drei Hauptzustände, in denen sich eine Datei befinden kann: committet (engl. committed), geändert (engl. modified) und für Commit vorgemerkt (engl. staged).
-
Modified bedeutet, dass eine Datei geändert, aber noch nicht in die lokale Datenbank eingecheckt wurde.
-
Staged bedeutet, dass eine geänderte Datei in ihrem gegenwärtigen Zustand für den nächsten Commit vorgemerkt ist.
-
Committed bedeutet, dass die Daten sicher in der lokalen Datenbank gespeichert sind.
Das führt uns zu den drei Hauptbereichen eines Git-Projekts: dem Verzeichnisbaum (engl. Working Tree), der sogenannten Staging-Area und dem Git-Verzeichnis.
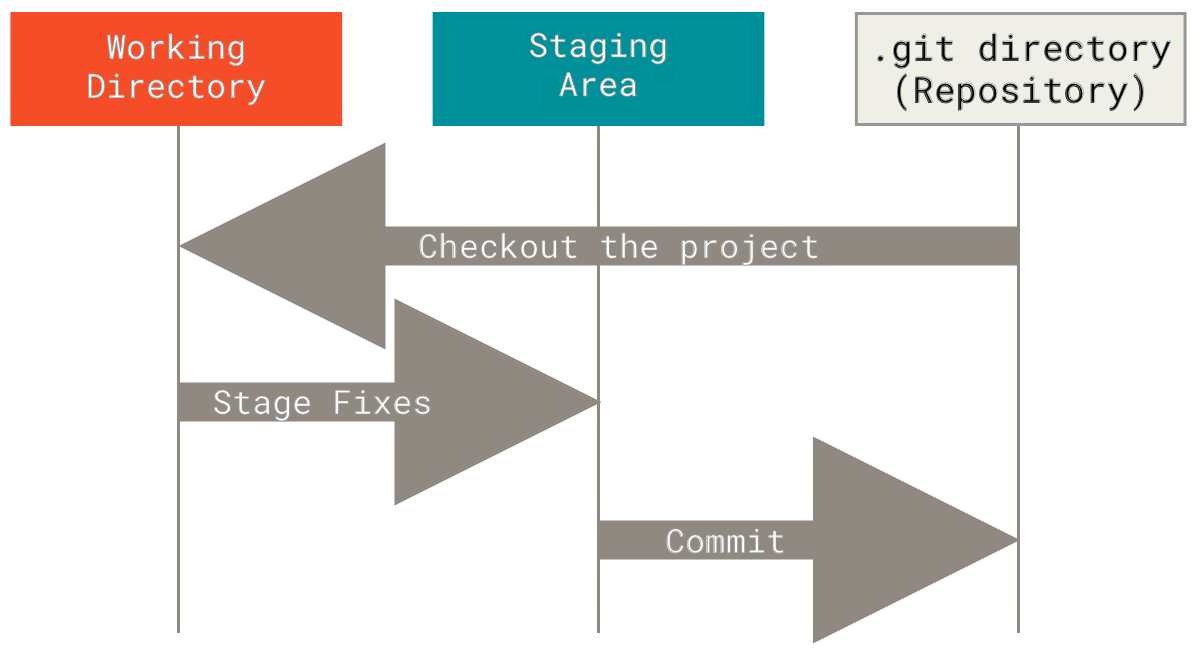
Der Verzeichnisbaum ist ein einzelner Checkout einer Version des Projekts. Diese Dateien werden aus der komprimierten Datenbank im Git-Verzeichnis geholt und auf der Festplatte so abgelegt, damit du sie verwenden oder ändern kannst.
Die Staging-Area ist in der Regel eine Datei, die sich in deinem Git-Verzeichnis befindet und Informationen darüber speichert, was in deinem nächsten Commit einfließen soll. Der technische Name im Git-Sprachgebrauch ist „Index“, aber der Ausdruck „Staging-Area“ funktioniert genauso gut.
Im Git-Verzeichnis werden die Metadaten und die Objektdatenbank für dein Projekt gespeichert. Das ist der wichtigste Teil von Git, dieser Teil wird kopiert, wenn man ein Repository von einem anderen Rechner klont.
Der grundlegende Git-Arbeitsablauf sieht in etwa so aus:
-
Du änderst Dateien in deinem Verzeichnisbaum.
-
Du stellst selektiv Änderungen bereit, die du bei deinem nächsten Commit berücksichtigen möchtest, wodurch nur diese Änderungen in den Staging-Bereich aufgenommen werden.
-
Du führst einen Commit aus, der die Dateien so übernimmt, wie sie sich in der Staging-Area befinden und diesen Snapshot dauerhaft in deinem Git-Verzeichnis speichert.
Wenn sich eine bestimmte Version einer Datei im Git-Verzeichnis befindet, wird sie als committed betrachtet. Wenn sie geändert und in die Staging-Area hinzugefügt wurde, gilt sie als für den Commit vorgemerkt (engl. staged). Und wenn sie geändert, aber noch nicht zur Staging-Area hinzugefügt wurde, gilt sie als geändert (engl. modified). Im Kapitel 2, Git Grundlagen, werden diese drei Zustände noch näher erläutert und wie man diese sinnvoll einsetzen kann oder alternativ, wie man den Zwischenschritt der Staging-Area überspringen kann.