
-
1. Pierwsze kroki
- 1.1 Wprowadzenie do kontroli wersji
- 1.2 Krótka historia Git
- 1.3 Podstawy Git
- 1.4 Linia poleceń
- 1.5 Instalacja Git
- 1.6 Wstępna konfiguracja Git
- 1.7 Uzyskiwanie pomocy
- 1.8 Podsumowanie
-
2. Podstawy Gita
- 2.1 Pierwsze repozytorium Gita
- 2.2 Rejestrowanie zmian w repozytorium
- 2.3 Podgląd historii rewizji
- 2.4 Cofanie zmian
- 2.5 Praca ze zdalnym repozytorium
- 2.6 Tagowanie
- 2.7 Aliasy
- 2.8 Podsumowanie
-
3. Gałęzie Gita
- 3.1 Czym jest gałąź
- 3.2 Podstawy rozgałęziania i scalania
- 3.3 Zarządzanie gałęziami
- 3.4 Sposoby pracy z gałęziami
- 3.5 Gałęzie zdalne
- 3.6 Zmiana bazy
- 3.7 Podsumowanie
-
4. Git na serwerze
- 4.1 Protokoły
- 4.2 Uruchomienie Git na serwerze
- 4.3 Generowanie Twojego publicznego klucza SSH
- 4.4 Konfigurowanie serwera
- 4.5 Git Daemon
- 4.6 Smart HTTP
- 4.7 GitWeb
- 4.8 GitLab
- 4.9 Inne opcje hostowania przez podmioty zewnętrzne
- 4.10 Podsumowanie
-
5. Rozproszony Git
-
6. GitHub
-
7. Narzędzia Gita
- 7.1 Wskazywanie rewizji
- 7.2 Interaktywne używanie przechowali
- 7.3 Schowek i czyszczenie
- 7.4 Signing Your Work
- 7.5 Searching
- 7.6 Przepisywanie historii
- 7.7 Reset Demystified
- 7.8 Advanced Merging
- 7.9 Rerere
- 7.10 Debugowanie z Gitem
- 7.11 Moduły zależne
- 7.12 Bundling
- 7.13 Replace
- 7.14 Credential Storage
- 7.15 Podsumowanie
-
8. Dostosowywanie Gita
- 8.1 Konfiguracja Gita
- 8.2 Git Attributes
- 8.3 Git Hooks
- 8.4 An Example Git-Enforced Policy
- 8.5 Summary
-
9. Git i inne systemy
- 9.1 Git jako klient
- 9.2 Migracja do Gita
- 9.3 Podsumowanie
-
10. Mechanizmy wewnętrzne w Git
- 10.1 Komendy typu plumbing i porcelain
- 10.2 Obiekty Gita
- 10.3 Referencje w Git
- 10.4 Spakowane pliki (packfiles)
- 10.5 Refspec
- 10.6 Protokoły transferu
- 10.7 Konserwacja i odzyskiwanie danych
- 10.8 Environment Variables
- 10.9 Podsumowanie
-
A1. Appendix A: Git in Other Environments
- A1.1 Graphical Interfaces
- A1.2 Git in Visual Studio
- A1.3 Git in Eclipse
- A1.4 Git in Bash
- A1.5 Git in Zsh
- A1.6 Git in Powershell
- A1.7 Summary
-
A2. Appendix B: Embedding Git in your Applications
- A2.1 Command-line Git
- A2.2 Libgit2
- A2.3 JGit
-
A3. Appendix C: Git Commands
- A3.1 Setup and Config
- A3.2 Getting and Creating Projects
- A3.3 Basic Snapshotting
- A3.4 Branching and Merging
- A3.5 Sharing and Updating Projects
- A3.6 Inspection and Comparison
- A3.7 Debugging
- A3.8 Patching
- A3.9 Email
- A3.10 External Systems
- A3.11 Administration
- A3.12 Plumbing Commands
1.3 Pierwsze kroki - Podstawy Git
Podstawy Git
Czym jest w skrócie Git? To jest bardzo istotna sekcja tej książki, ponieważ jeśli zrozumiesz czym jest Git i podstawy jego działania to efektywne używanie go powinno być dużo prostsze. Podczas uczenia się Git staraj się nie myśleć o tym co wiesz o innych systemach VCS, takich jak Subversion czy Perforce; pozwoli Ci to uniknąć subtelnych błędów przy używaniu tego narzędzia. Git przechowuje i traktuje informacje kompletnie inaczej niż te pozostałe systemy, mimo że interfejs użytkownika jest dość zbliżony. Rozumienie tych różnic powinno pomóc Ci w unikaniu błędów przy korzystaniu z Git.
Migawki, nie różnice
Podstawową różnicą pomiędzy Git a każdym innym systemem VCS (włączając w to Subversion) jest podejście Git do przechowywanych danych. Większość pozostałych systemów przechowuje informacje jako listę zmian na plikach. Systemy te (CVS, Subversion, Perforce, Bazaar i inne) traktują przechowywane informacje jako zbiór plików i zmian dokonanych na każdym z nich w okresie czasu. Obrazuje to Rysunek 1-4.
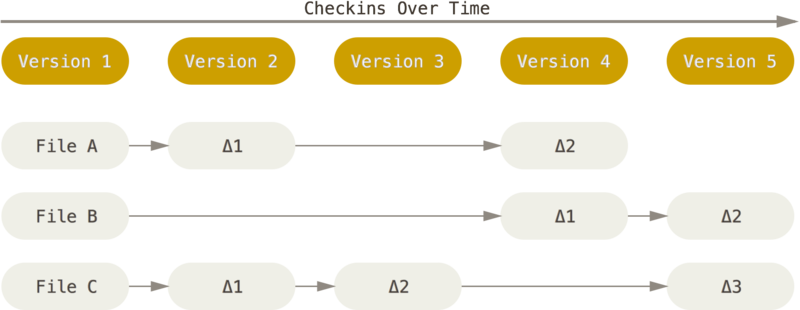
Git podchodzi do przechowywania danych w odmienny sposób. Traktuje on dane podobnie jak zestaw migawek (ang. snapshots) małego systemu plików. Za każdym razem jak tworzysz commit lub zapisujesz stan projektu, Git tworzy obraz przedstawiający to jak wyglądają wszystkie pliki w danym momencie i przechowuje referencję do tej migawki. W celu uzyskania dobrej wydajności, jeśli dany plik nie został zmieniony, Git nie zapisuje ponownie tego pliku, a tylko referencję do jego poprzedniej, identycznej wersji, która jest już zapisana. Git myśli o danych w sposób podobny do przedstawionego na Rysunku 1-5.
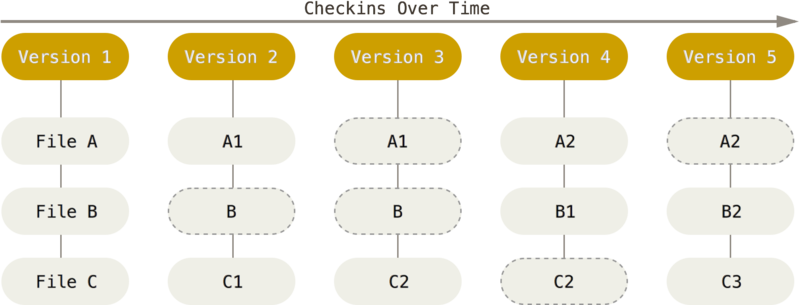
To jest istotna różnica pomiędzy Git i prawie wszystkimi innymi systemami VCS. Jej konsekwencją jest to, że Git rewiduje prawie wszystkie aspekty kontroli wersji, które pozostałe systemy po prostu kopiowały z poprzednich generacji. Powoduje także, że Git jest bardziej podobny do mini systemu plików ze zbudowanymi na nim potężnymi narzędziami, niż do zwykłego systemu VCS. Odkryjemy niektóre z zalet które zyskuje się poprzez myślenie o danych w ten sposób, gdy w trzecim rozdziale będziemy omawiać tworzenie gałęzi w Git. Gałęzie Gita.
Niemal każda operacja jest lokalna
Większość operacji w Git do działania wymaga jedynie dostępu do lokalnych plików i zasobów, lub inaczej – nie są potrzebne żadne dane przechowywane na innym komputerze w sieci. Jeśli jesteś przyzwyczajony do systemów CVCS, w których większość operacji posiada narzut związany z dostępem sieciowym, ten aspekt Git sprawi, że uwierzysz w bogów szybkości, którzy musieli obdarzyć Git nieziemskimi mocami. Ponieważ kompletna historia projektu znajduje się w całości na Twoim dysku, odnosi się wrażenie, że większość operacji działa niemal natychmiast.
Przykładowo, w celu przeglądu historii projektu, Git nie musi łączyć się z serwerem, aby pobrać historyczne dane - zwyczajnie odczytuje je wprost z lokalnej bazy danych. Oznacza to, że dostęp do historii jest niemal natychmiastowy. Jeśli chcesz przejrzeć zmiany wprowadzone pomiędzy bieżącą wersją pliku, a jego stanem sprzed miesiąca, Git może odnaleźć wersję pliku sprzed miesiąca i dokonać lokalnego porównania. Nie musi w tym celu prosić serwera o wygenerowanie różnicy, czy też o udostępnienie wcześniejszej wersji pliku.
Oznacza to również, że można zrobić prawie wszystko będąc poza zasięgiem sieci lub firmowego VPNa. Jeśli masz ochotę popracować w samolocie lub pociągu, możesz bez problemu zatwierdzać kolejne zmiany, by w momencie połączenia z siecią przesłać komplet zmian na serwer. Jeśli pracujesz w domu, a klient VPN odmawia współpracy, nie musisz czekać z pilnymi zmianami. W wielu innych systemach taki sposób pracy jest albo niemożliwy, albo co najmniej uciążliwy. Przykładowo w Perforce, nie możesz wiele zdziałać bez połączenia z serwerem; w Subversion, albo CVS możesz edytować pliki, ale nie masz możliwości zatwierdzania zmian w repozytorium (ponieważ nie masz do niego dostępu). Może nie wydaje się to wielkim problemem, ale zdziwisz się pewnie jak wielką stanowi to różnicę w sposobie pracy.
Git ma wbudowane mechanizmy spójności danych
Dla każdego obiektu Git wyliczana jest suma kontrolna przed jego zapisem i na podstawie tej sumy można od tej pory odwoływać się do danego obiektu. Oznacza to, że nie ma możliwości zmiany zawartości żadnego pliku, czy katalogu bez reakcji ze strony Git. Ta cecha wynika z wbudowanych, niskopoziomowych mechanizmów Git i stanowi integralną część jego filozofii. Nie ma szansy na utratę informacji, czy uszkodzenie zawartości pliku podczas przesyłania lub pobierania danych, bez możliwości wykrycia takiej sytuacji przez Git.
Mechanizmem, który wykorzystuje Git do wyznaczenia sumy kontrolnej jest tzw. skrót SHA-1. Jest to 40-znakowy łańcuch składający się z liczb szesnastkowych (0–9 oraz a–f), wyliczany na podstawie zawartości pliku lub struktury katalogu. Skrót SHA-1 wygląda mniej więcej tak:
24b9da6552252987aa493b52f8696cd6d3b00373Pracując z Git będziesz miał styczność z takimi skrótami w wielu miejscach, ponieważ są one wykorzystywane cały czas. W rzeczywistości Git przechowuje wszystko nie pod postacią plików i ich nazw, ale we własnej bazie danych, w której kluczami są skróty SHA-1, a wartościami - zawartości plików, czy struktur katalogów.
Standardowo Git wyłącznie dodaje nowe dane
Wykonując pracę z Git, niemal zawsze jedynie dodajemy dane do bazy danych Git. Bardzo trudno jest zmusić system do zrobienia czegoś, z czego nie można się następnie wycofać, albo sprawić, by niejawnie skasował jakieś dane. Podobnie jak w innych systemach VCS, można stracić lub nadpisać zmiany, które nie zostały jeszcze zatwierdzone; ale po zatwierdzeniu migawki do Git, bardzo trudno jest stracić te zmiany, zwłaszcza jeśli regularnie pchasz własną bazę danych Git do innego repozytorium.
Ta cecha sprawia, że praca z Git jest czystą przyjemnością, ponieważ wiemy, że możemy eksperymentować bez ryzyka zepsucia czegokolwiek. Więcej szczegółów na temat sposobu przechowywania danych przez Git oraz na temat mechanizmów odzyskiwania danych, które wydają się być utracone, znajduje się w rozdziale 9, "Mechanizmy wewnętrzne". Cofanie zmian.
Trzy stany
Teraz uwaga. To jedna z najważniejszych spraw do zapamiętania jeśli chodzi o pracę z Git, jeśli dalszy proces nauki ma przebiegać sprawnie. Git posiada trzy stany, w których mogą znajdować się pliki: zatwierdzony, zmodyfikowany oraz oczekujący w poczekalni. Zatwierdzony oznacza, że dane zostały bezpiecznie zachowane w Twojej lokalnej bazie danych. Zmodyfikowany oznacza, że plik został zmieniony, ale zmiany nie zostały wprowadzone do bazy danych. Oczekujący w poczekalni (ang. staged) - oznacza, że zmodyfikowany plik został przeznaczony do zatwierdzenia w bieżącej postaci w następnej operacji commit.
Z powyższego wynikają trzy główne sekcje projektu Git: katalog Git, katalog roboczy i przechowalnia (ang. staging area).
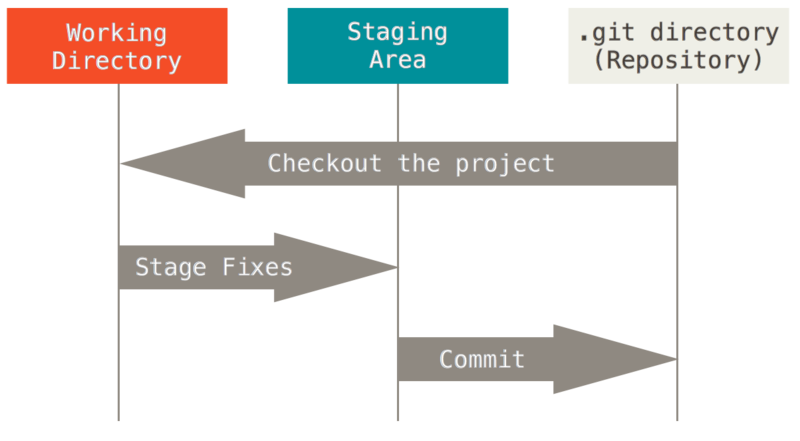
Katalog Git jest miejscem, w którym Git przechowuje własne metadane oraz obiektową bazę danych Twojego projektu. To najważniejsza część Git i to właśnie ten katalog jest kopiowany podczas klonowania repozytorium z innego komputera.
Katalog roboczy stanowi obraz jednej wersji projektu. Zawartość tego katalogu pobierana jest ze skompresowanej bazy danych zawartej w katalogu Git i umieszczana na dysku w miejscu, w którym można ją odczytać lub zmodyfikować.
Przechowalnia to prosty plik, zwykle przechowywany w katalogu Git, który zawiera informacje o tym, czego dotyczyć będzie następna operacja commit. Czasami można spotkać się z określeniem indeks, ale ostatnio przyjęło się odwoływać do niego właśnie jako przechowalnia.
Podstawowy sposób pracy z Git wygląda mniej więcej tak:
-
Dokonujesz modyfikacji plików w katalogu roboczym.
-
Oznaczasz zmodyfikowane pliki jako śledzone, dodając ich bieżący stan (migawkę) do przechowalni.
-
Dokonujesz zatwierdzenia (
commit), podczas którego zawartość plików z przechowalni zapisywana jest jako migawka projektu w katalogu Git.
Jeśli jakaś wersja pliku znajduje się w katalogu git, uznaje się ją jako zatwierdzoną. Jeśli plik jest zmodyfikowany, ale został dodany do przechowalni, plik jest oczekujący w poczekalni (ang. staged). Jeśli zaś plik jest zmodyfikowany od czasu ostatniego pobrania, ale nie został dodany do przechowalni, plik jest w stanie zmodyfikowanym. W Podstawy Gita dowiesz się więcej o wszystkich tych stanach oraz o tym jak wykorzystać je do ułatwienia sobie pracy lub jak zupełnie pominąć przechowalnię.