
-
1. Getting Started
- 1.1 About Version Control
- 1.2 A Short History of Git
- 1.3 What is Git?
- 1.4 The Command Line
- 1.5 Installing Git
- 1.6 First-Time Git Setup
- 1.7 Getting Help
- 1.8 Summary
-
2. Git Basics
- 2.1 Getting a Git Repository
- 2.2 Recording Changes to the Repository
- 2.3 Viewing the Commit History
- 2.4 Undoing Things
- 2.5 Working with Remotes
- 2.6 Tagging
- 2.7 Git Aliases
- 2.8 Summary
-
3. Git Branching
- 3.1 Branches in a Nutshell
- 3.2 Basic Branching and Merging
- 3.3 Branch Management
- 3.4 Branching Workflows
- 3.5 Remote Branches
- 3.6 Rebasing
- 3.7 Summary
-
4. Git on the Server
- 4.1 The Protocols
- 4.2 Getting Git on a Server
- 4.3 Generating Your SSH Public Key
- 4.4 Setting Up the Server
- 4.5 Git Daemon
- 4.6 Smart HTTP
- 4.7 GitWeb
- 4.8 GitLab
- 4.9 Third Party Hosted Options
- 4.10 Summary
-
5. Distributed Git
- 5.1 Distributed Workflows
- 5.2 Contributing to a Project
- 5.3 Maintaining a Project
- 5.4 Summary
-
6. GitHub
-
7. Git Tools
- 7.1 Revision Selection
- 7.2 Interactive Staging
- 7.3 Stashing and Cleaning
- 7.4 Signing Your Work
- 7.5 Searching
- 7.6 Rewriting History
- 7.7 Reset Demystified
- 7.8 Advanced Merging
- 7.9 Rerere
- 7.10 Debugging with Git
- 7.11 Submodules
- 7.12 Bundling
- 7.13 Replace
- 7.14 Credential Storage
- 7.15 Summary
-
8. Customizing Git
- 8.1 Git Configuration
- 8.2 Git Attributes
- 8.3 Git Hooks
- 8.4 An Example Git-Enforced Policy
- 8.5 Summary
-
9. Git and Other Systems
- 9.1 Git as a Client
- 9.2 Migrating to Git
- 9.3 Summary
-
10. Git Internals
- 10.1 Plumbing and Porcelain
- 10.2 Git Objects
- 10.3 Git References
- 10.4 Packfiles
- 10.5 The Refspec
- 10.6 Transfer Protocols
- 10.7 Maintenance and Data Recovery
- 10.8 Environment Variables
- 10.9 Summary
-
A1. Appendix A: Git in Other Environments
- A1.1 Graphical Interfaces
- A1.2 Git in Visual Studio
- A1.3 Git in Visual Studio Code
- A1.4 Git in IntelliJ / PyCharm / WebStorm / PhpStorm / RubyMine
- A1.5 Git in Sublime Text
- A1.6 Git in Bash
- A1.7 Git in Zsh
- A1.8 Git in PowerShell
- A1.9 Summary
-
A2. Appendix B: Embedding Git in your Applications
- A2.1 Command-line Git
- A2.2 Libgit2
- A2.3 JGit
- A2.4 go-git
- A2.5 Dulwich
-
A3. Appendix C: Git Commands
- A3.1 Setup and Config
- A3.2 Getting and Creating Projects
- A3.3 Basic Snapshotting
- A3.4 Branching and Merging
- A3.5 Sharing and Updating Projects
- A3.6 Inspection and Comparison
- A3.7 Debugging
- A3.8 Patching
- A3.9 Email
- A3.10 External Systems
- A3.11 Administration
- A3.12 Plumbing Commands
3.6 Git Branching - Rebasing
Rebasing
In Git, there are two main ways to integrate changes from one branch into another: the merge and the rebase.
In this section you’ll learn what rebasing is, how to do it, why it’s a pretty amazing tool, and in what cases you won’t want to use it.
The Basic Rebase
If you go back to an earlier example from Basic Merging, you can see that you diverged your work and made commits on two different branches.
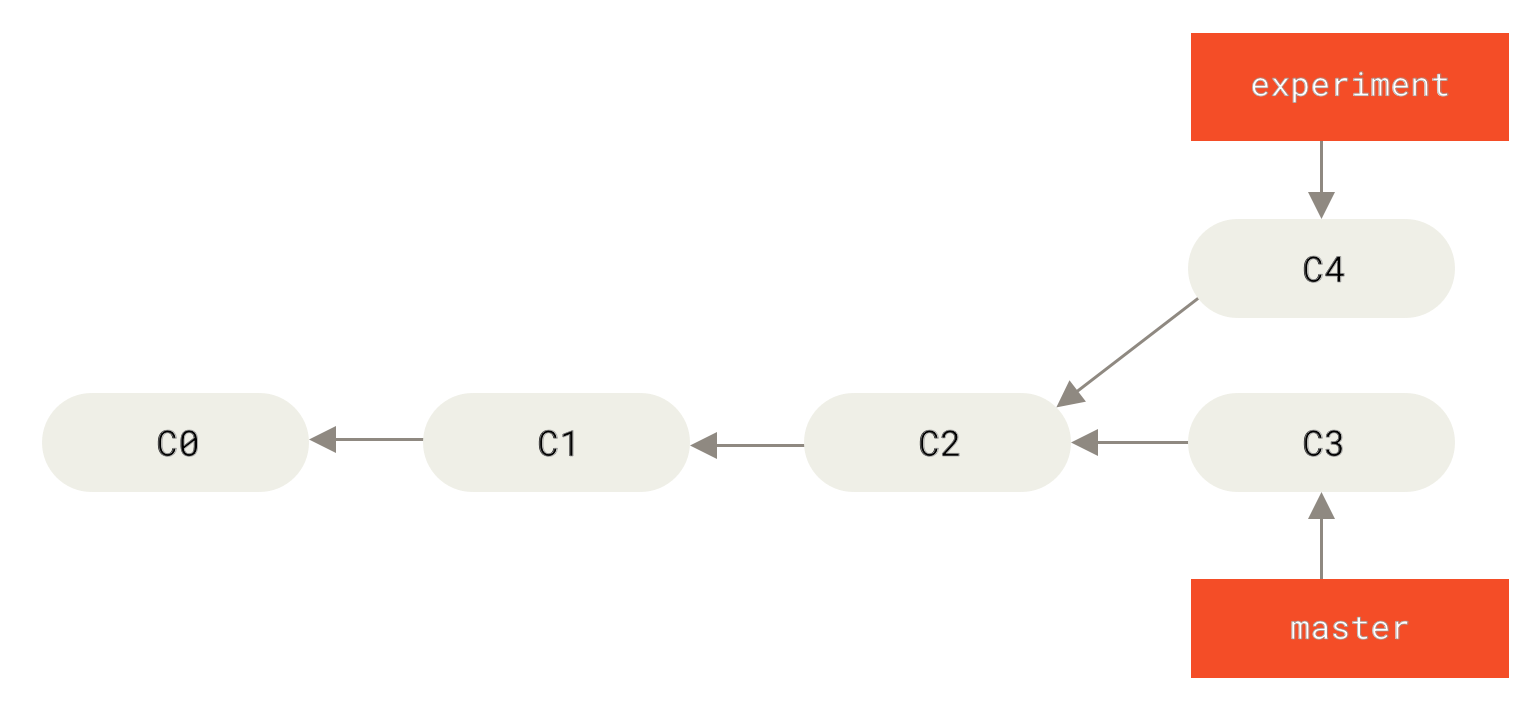
The easiest way to integrate the branches, as we’ve already covered, is the merge command.
It performs a three-way merge between the two latest branch snapshots (C3 and C4) and the most recent common ancestor of the two (C2), creating a new snapshot (and commit).
However, there is another way: you can take the patch of the change that was introduced in C4 and reapply it on top of C3.
In Git, this is called rebasing.
With the rebase command, you can take all the changes that were committed on one branch and replay them on a different branch.
For this example, you would check out the experiment branch, and then rebase it onto the master branch as follows:
$ git checkout experiment
$ git rebase master
First, rewinding head to replay your work on top of it...
Applying: added staged commandThis operation works by going to the common ancestor of the two branches (the one you’re on and the one you’re rebasing onto), getting the diff introduced by each commit of the branch you’re on, saving those diffs to temporary files, resetting the current branch to the same commit as the branch you are rebasing onto, and finally applying each change in turn.
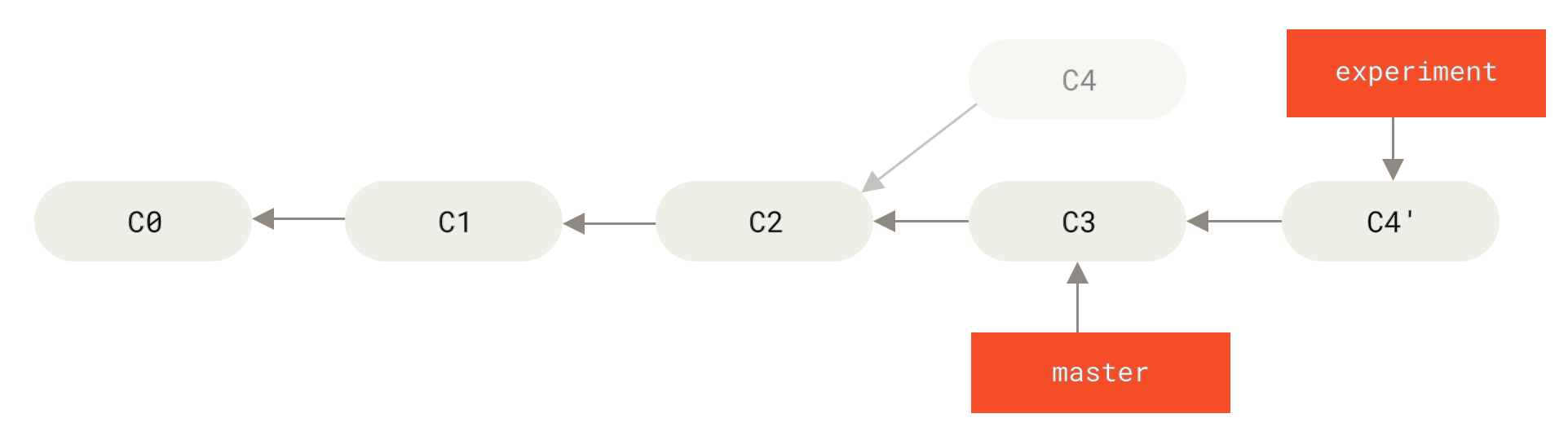
C4 onto C3
At this point, you can go back to the master branch and do a fast-forward merge.
$ git checkout master
$ git merge experiment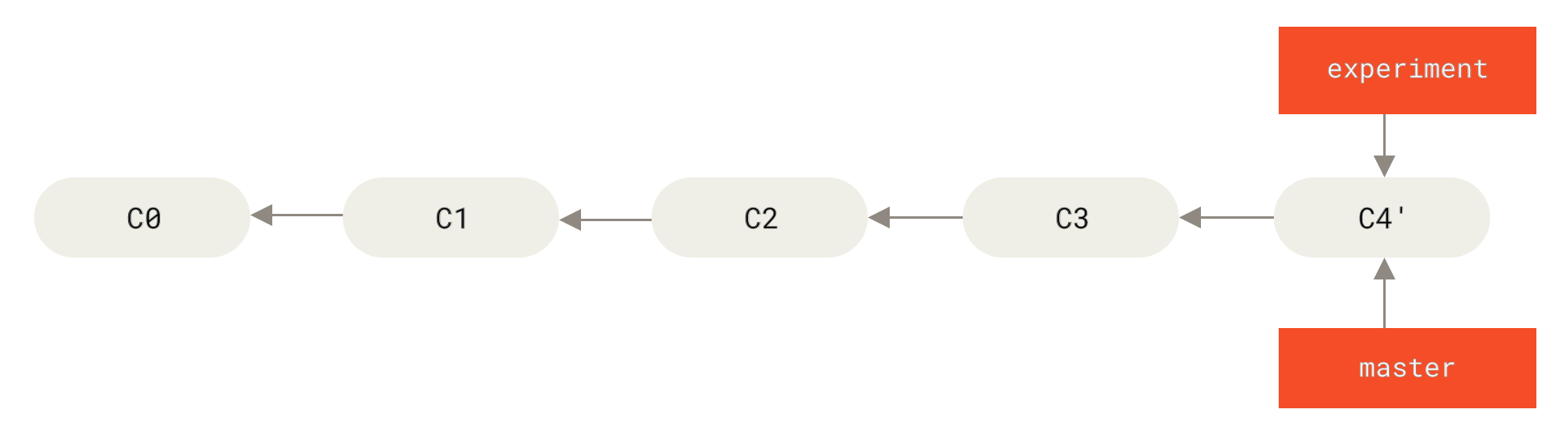
master branchNow, the snapshot pointed to by C4' is exactly the same as the one that was pointed to by C5 in the merge example.
There is no difference in the end product of the integration, but rebasing makes for a cleaner history.
If you examine the log of a rebased branch, it looks like a linear history: it appears that all the work happened in series, even when it originally happened in parallel.
Often, you’ll do this to make sure your commits apply cleanly on a remote branch — perhaps in a project to which you’re trying to contribute but that you don’t maintain.
In this case, you’d do your work in a branch and then rebase your work onto origin/master when you were ready to submit your patches to the main project.
That way, the maintainer doesn’t have to do any integration work — just a fast-forward or a clean apply.
Note that the snapshot pointed to by the final commit you end up with, whether it’s the last of the rebased commits for a rebase or the final merge commit after a merge, is the same snapshot — it’s only the history that is different. Rebasing replays changes from one line of work onto another in the order they were introduced, whereas merging takes the endpoints and merges them together.
More Interesting Rebases
You can also have your rebase replay on something other than the rebase target branch.
Take a history like A history with a topic branch off another topic branch, for example.
You branched a topic branch (server) to add some server-side functionality to your project, and made a commit.
Then, you branched off that to make the client-side changes (client) and committed a few times.
Finally, you went back to your server branch and did a few more commits.
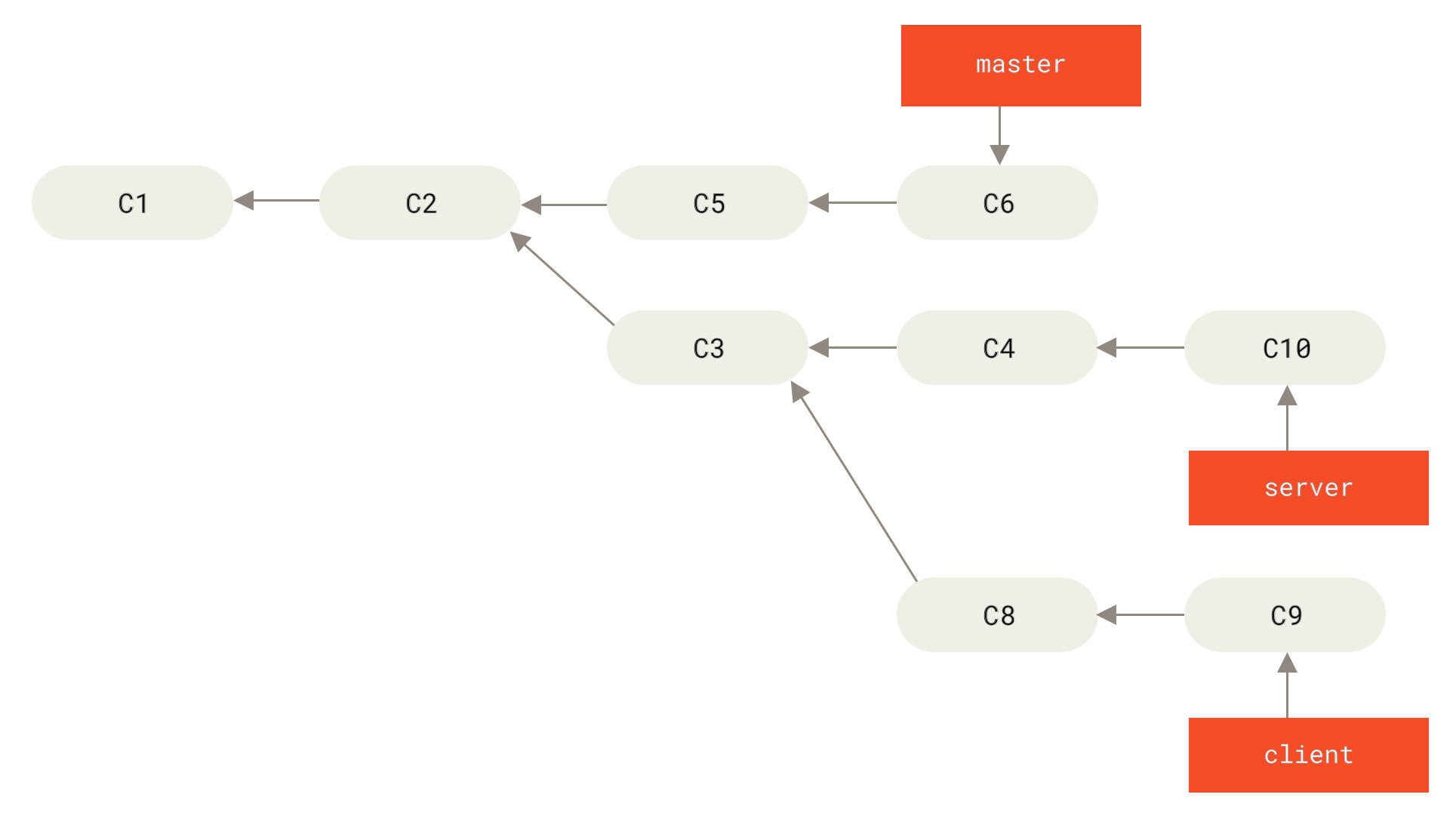
Suppose you decide that you want to merge your client-side changes into your mainline for a release, but you want to hold off on the server-side changes until it’s tested further.
You can take the changes on client that aren’t on server (C8 and C9) and replay them on your master branch by using the --onto option of git rebase:
$ git rebase --onto master server clientThis basically says, “Take the client branch, figure out the patches since it diverged from the server branch, and replay these patches in the client branch as if it was based directly off the master branch instead.”
It’s a bit complex, but the result is pretty cool.
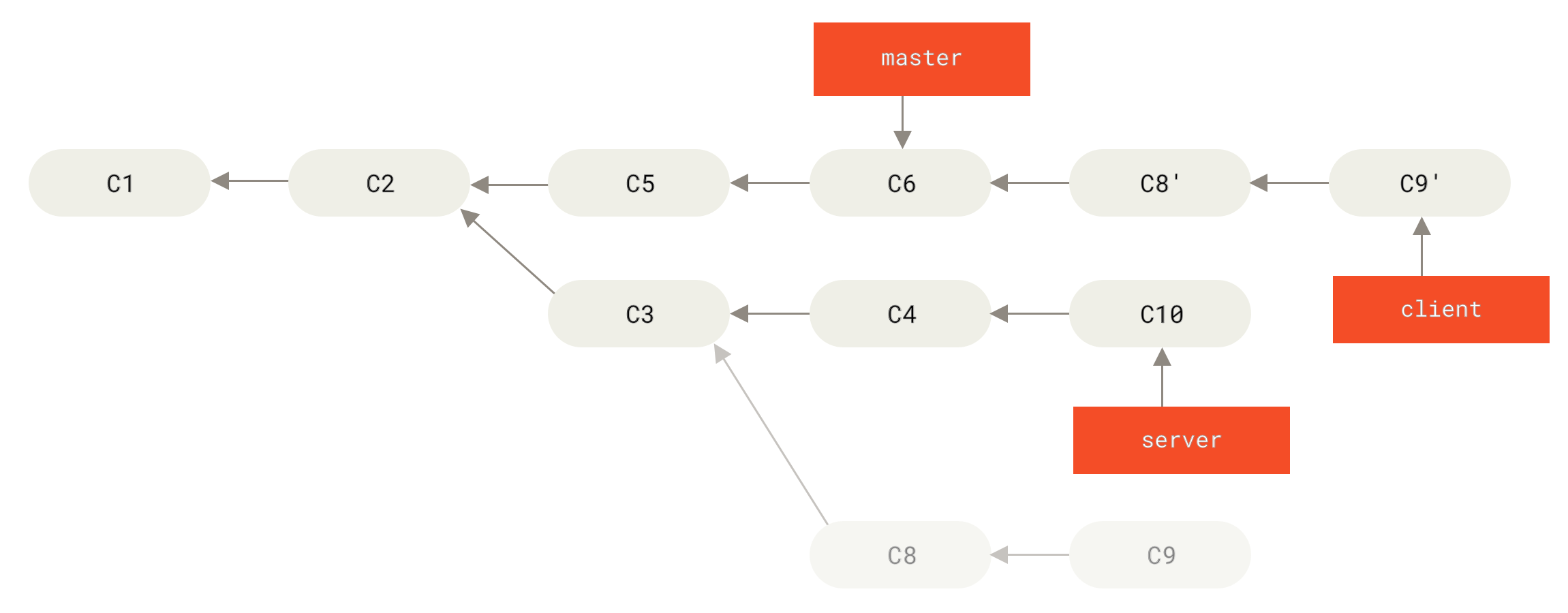
Now you can fast-forward your master branch (see Fast-forwarding your master branch to include the client branch changes):
$ git checkout master
$ git merge client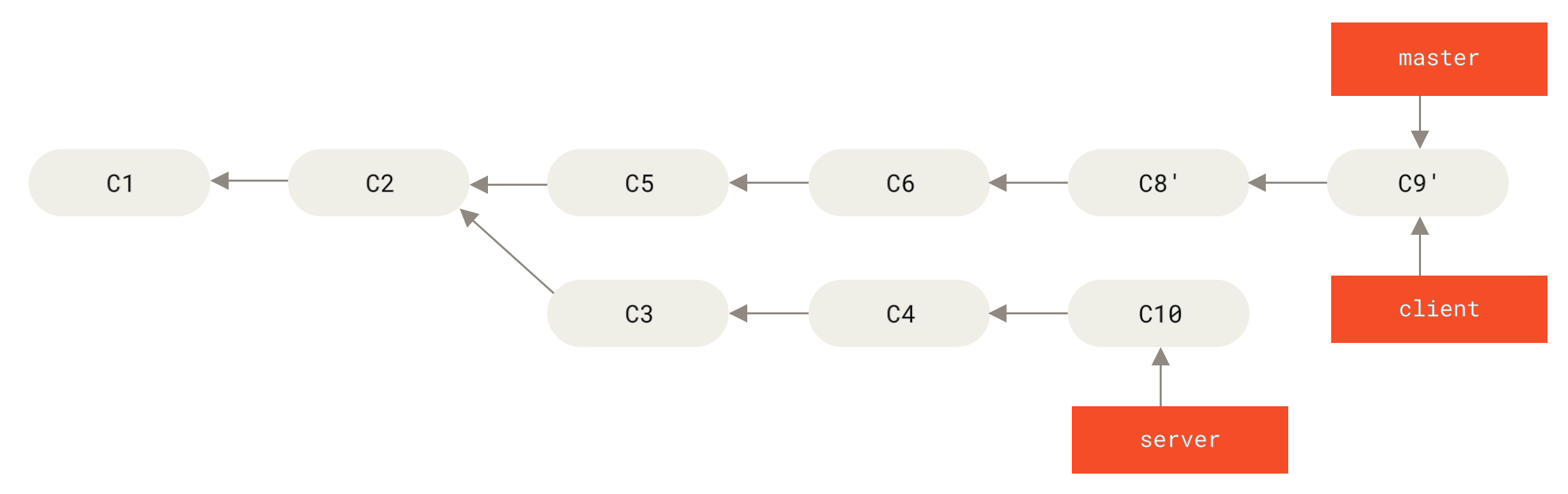
master branch to include the client branch changesLet’s say you decide to pull in your server branch as well.
You can rebase the server branch onto the master branch without having to check it out first by running git rebase <basebranch> <topicbranch> — which checks out the topic branch (in this case, server) for you and replays it onto the base branch (master):
$ git rebase master serverThis replays your server work on top of your master work, as shown in Rebasing your server branch on top of your master branch.

server branch on top of your master branchThen, you can fast-forward the base branch (master):
$ git checkout master
$ git merge serverYou can remove the client and server branches because all the work is integrated and you don’t need them anymore, leaving your history for this entire process looking like Final commit history:
$ git branch -d client
$ git branch -d server
The Perils of Rebasing
Ahh, but the bliss of rebasing isn’t without its drawbacks, which can be summed up in a single line:
Do not rebase commits that exist outside your repository and that people may have based work on.
If you follow that guideline, you’ll be fine. If you don’t, people will hate you, and you’ll be scorned by friends and family.
When you rebase stuff, you’re abandoning existing commits and creating new ones that are similar but different.
If you push commits somewhere and others pull them down and base work on them, and then you rewrite those commits with git rebase and push them up again, your collaborators will have to re-merge their work and things will get messy when you try to pull their work back into yours.
Let’s look at an example of how rebasing work that you’ve made public can cause problems. Suppose you clone from a central server and then do some work off that. Your commit history looks like this:
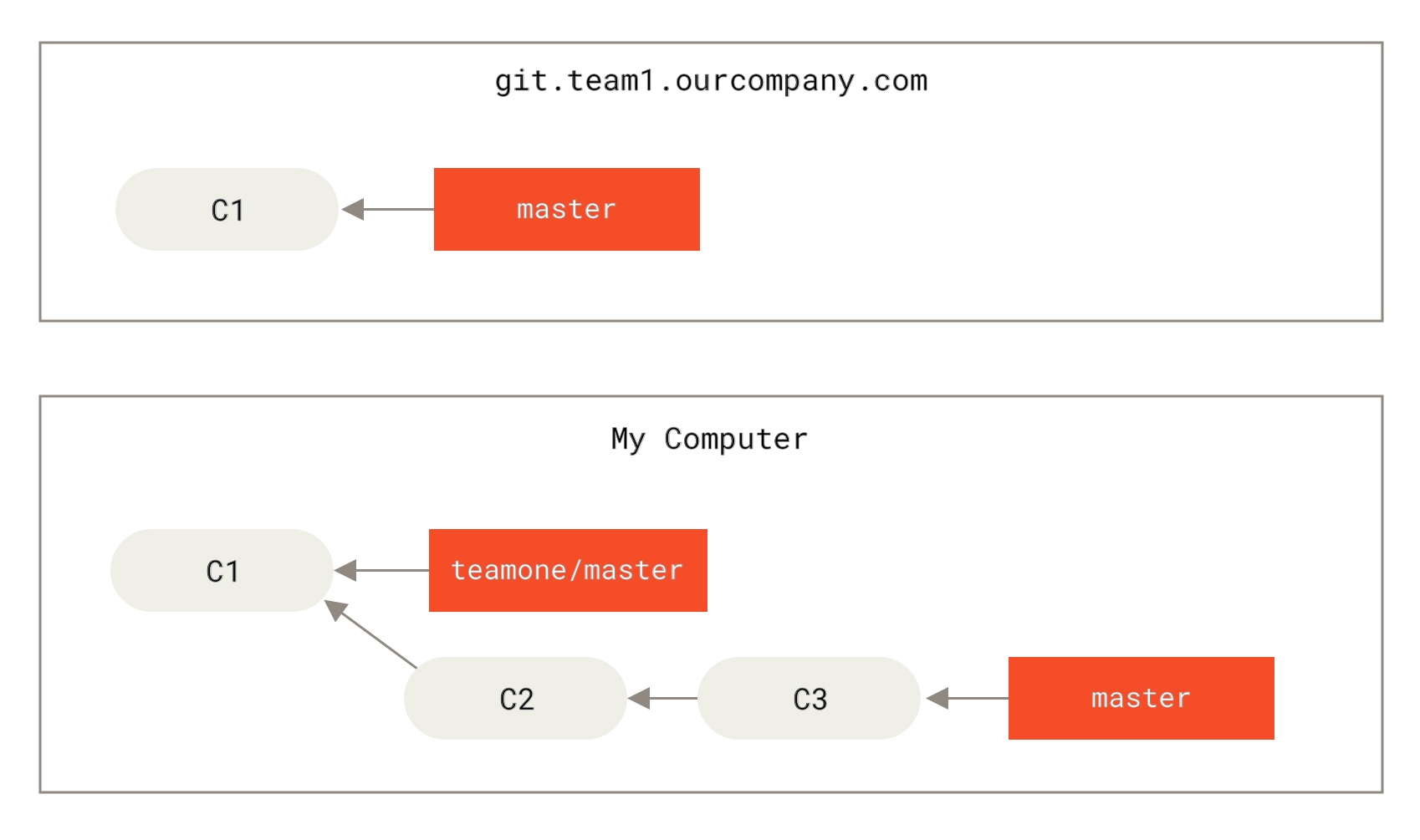
Now, someone else does more work that includes a merge, and pushes that work to the central server. You fetch it and merge the new remote branch into your work, making your history look something like this:
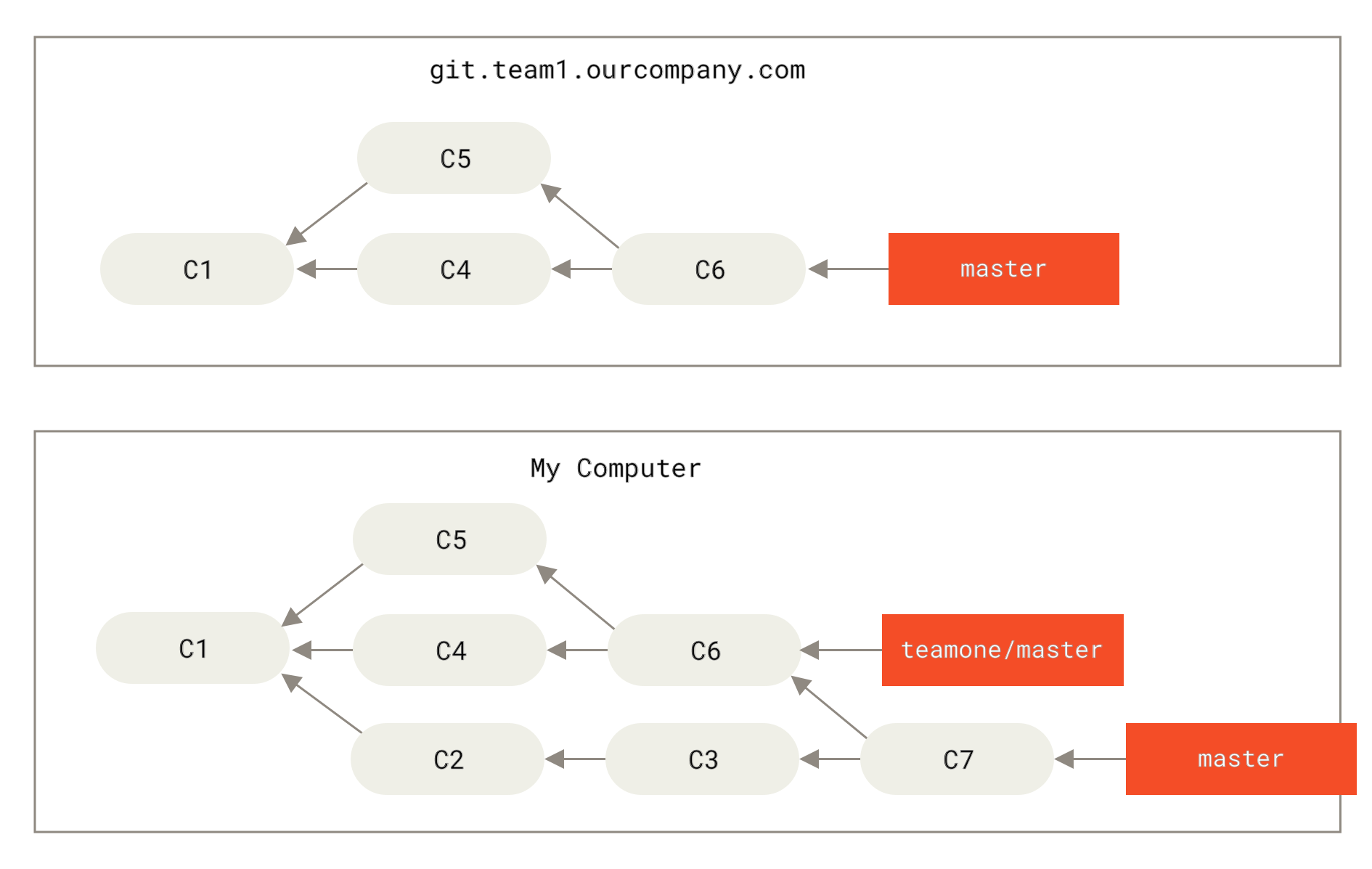
Next, the person who pushed the merged work decides to go back and rebase their work instead; they do a git push --force to overwrite the history on the server.
You then fetch from that server, bringing down the new commits.
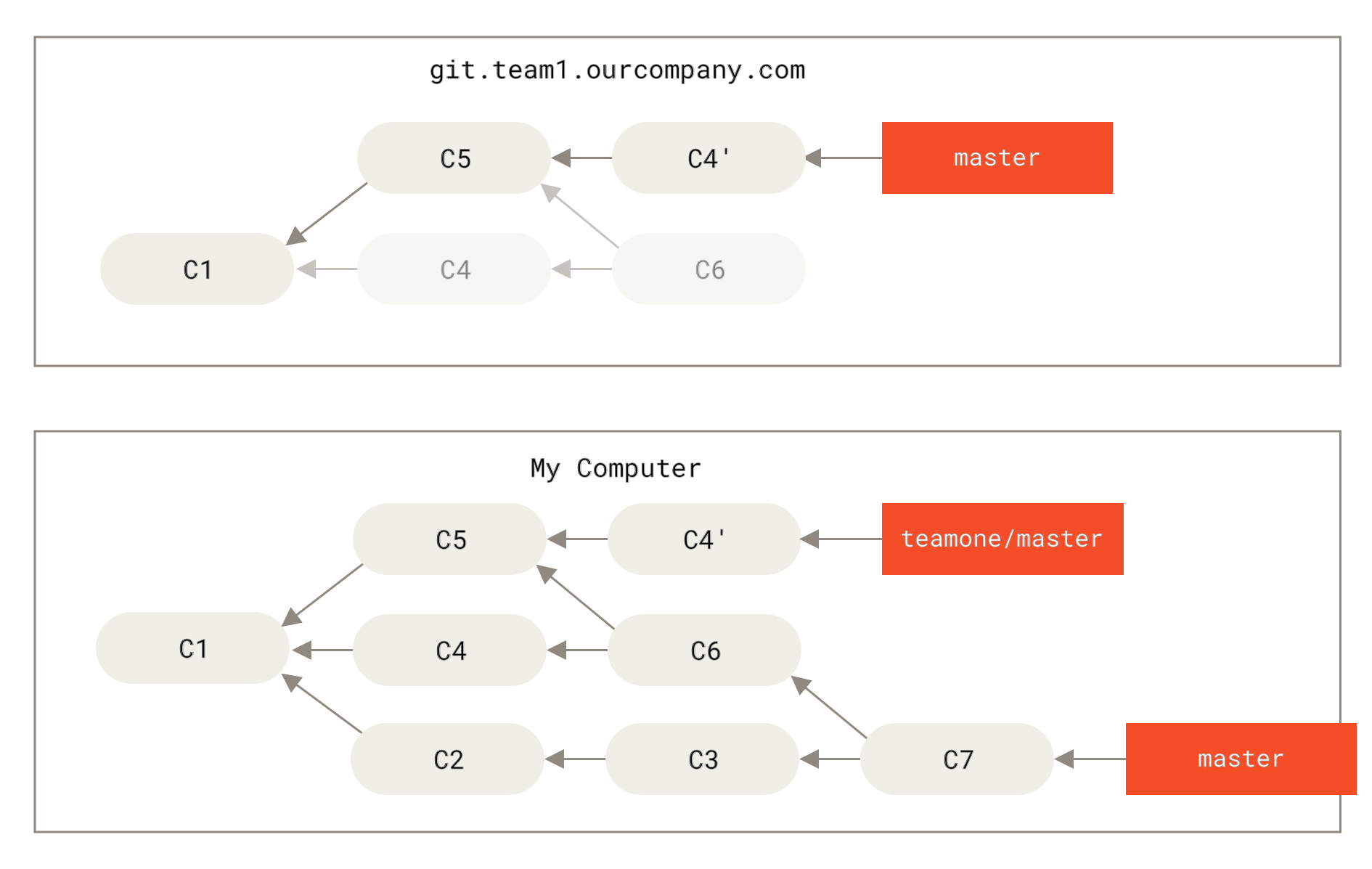
Now you’re both in a pickle.
If you do a git pull, you’ll create a merge commit which includes both lines of history, and your repository will look like this:
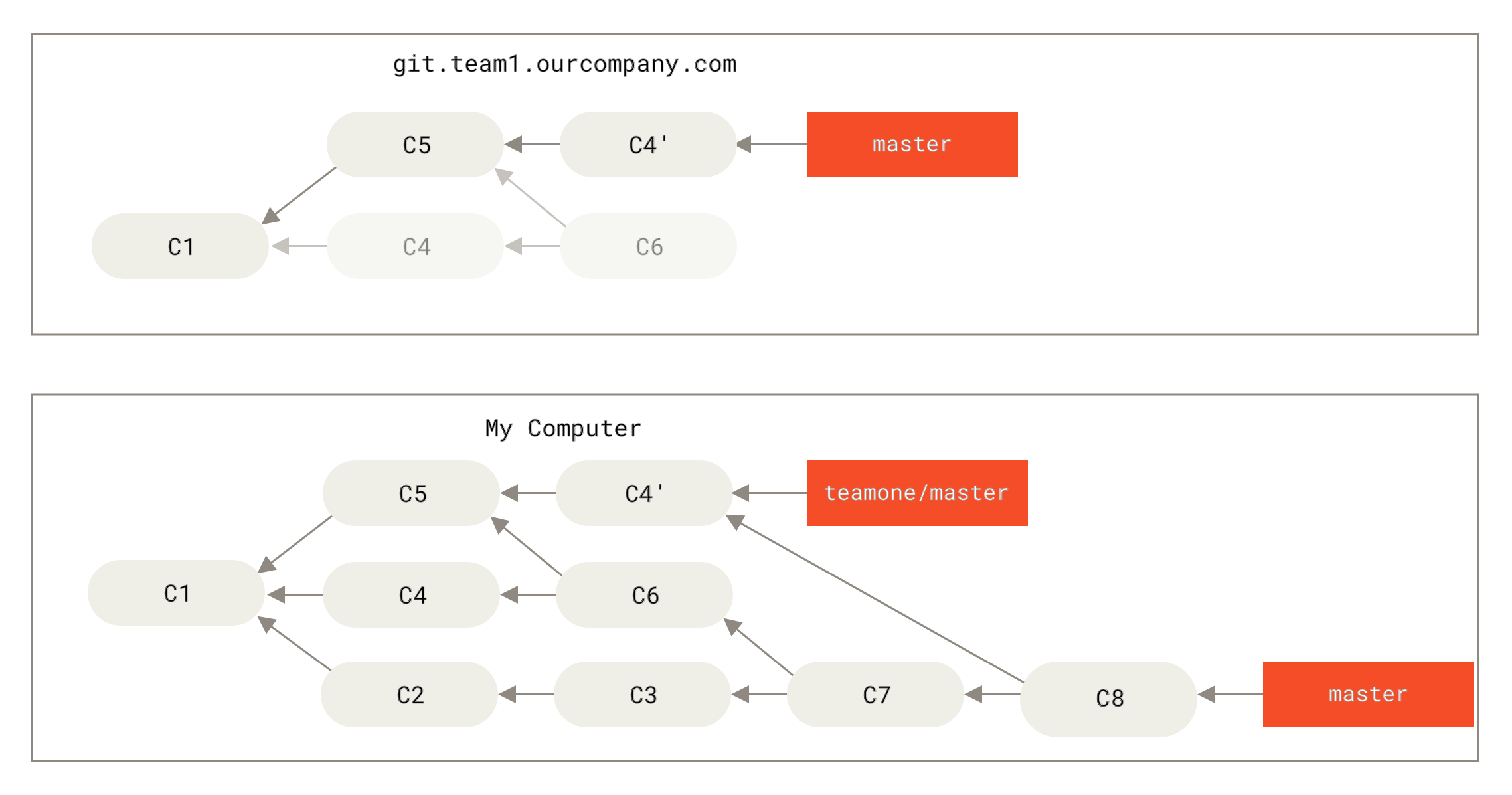
If you run a git log when your history looks like this, you’ll see two commits that have the same author, date, and message, which will be confusing.
Furthermore, if you push this history back up to the server, you’ll reintroduce all those rebased commits to the central server, which can further confuse people.
It’s pretty safe to assume that the other developer doesn’t want C4 and C6 to be in the history; that’s why they rebased in the first place.
Rebase When You Rebase
If you do find yourself in a situation like this, Git has some further magic that might help you out. If someone on your team force pushes changes that overwrite work that you’ve based work on, your challenge is to figure out what is yours and what they’ve rewritten.
It turns out that in addition to the commit SHA-1 checksum, Git also calculates a checksum that is based just on the patch introduced with the commit. This is called a “patch-id”.
If you pull down work that was rewritten and rebase it on top of the new commits from your partner, Git can often successfully figure out what is uniquely yours and apply them back on top of the new branch.
For instance, in the previous scenario, if instead of doing a merge when we’re at Someone pushes rebased commits, abandoning commits you’ve based your work on we run git rebase teamone/master, Git will:
-
Determine what work is unique to our branch (
C2,C3,C4,C6,C7) -
Determine which are not merge commits (
C2,C3,C4) -
Determine which have not been rewritten into the target branch (just
C2andC3, sinceC4is the same patch asC4') -
Apply those commits to the top of
teamone/master
So instead of the result we see in You merge in the same work again into a new merge commit, we would end up with something more like Rebase on top of force-pushed rebase work.
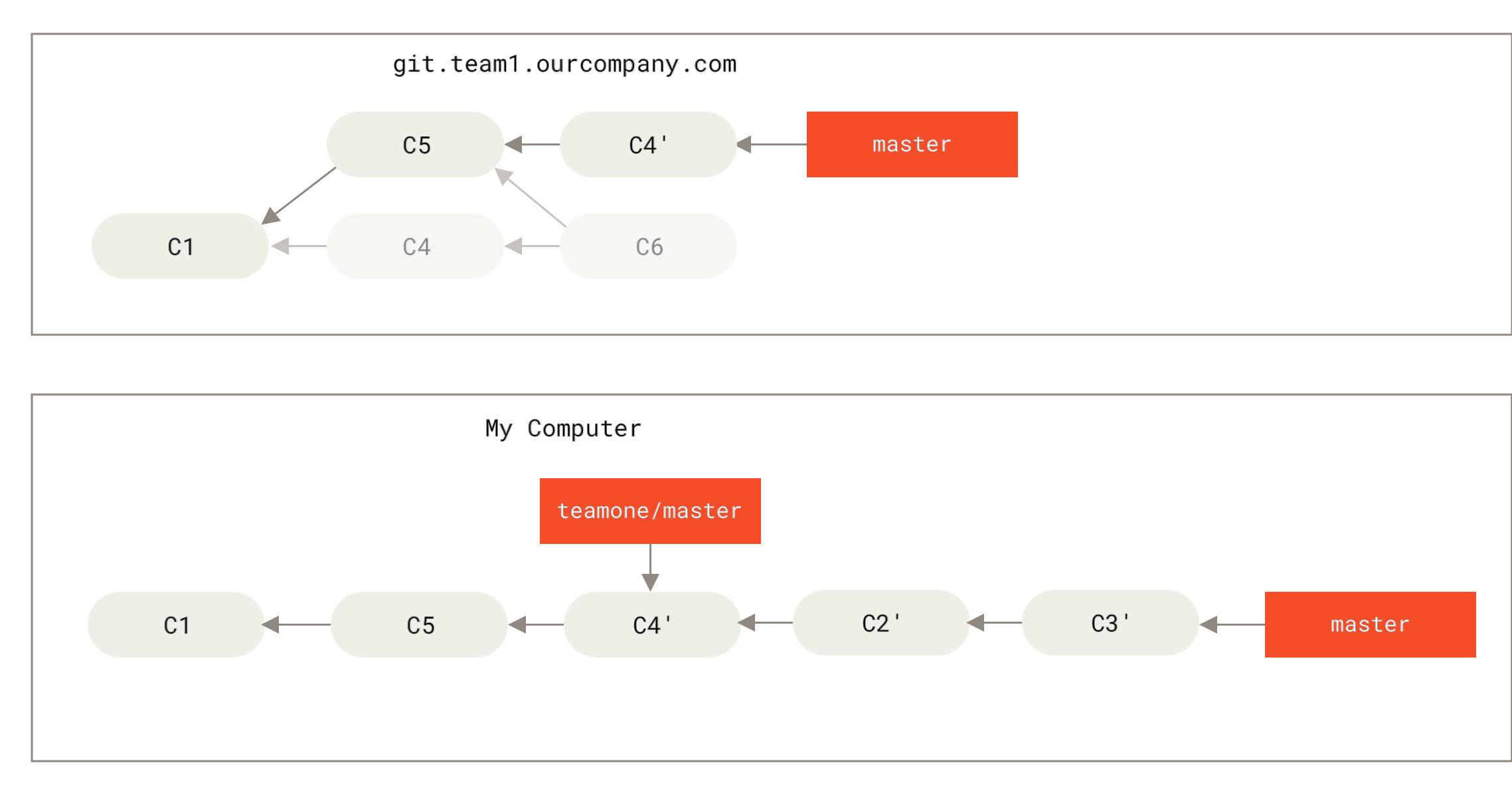
This only works if C4 and C4' that your partner made are almost exactly the same patch.
Otherwise the rebase won’t be able to tell that it’s a duplicate and will add another C4-like patch (which will probably fail to apply cleanly, since the changes would already be at least somewhat there).
You can also simplify this by running a git pull --rebase instead of a normal git pull.
Or you could do it manually with a git fetch followed by a git rebase teamone/master in this case.
If you are using git pull and want to make --rebase the default, you can set the pull.rebase config value with something like git config --global pull.rebase true.
If you only ever rebase commits that have never left your own computer, you’ll be just fine. If you rebase commits that have been pushed, but that no one else has based commits from, you’ll also be fine. If you rebase commits that have already been pushed publicly, and people may have based work on those commits, then you may be in for some frustrating trouble, and the scorn of your teammates.
If you or a partner does find it necessary at some point, make sure everyone knows to run git pull --rebase to try to make the pain after it happens a little bit simpler.
Rebase vs. Merge
Now that you’ve seen rebasing and merging in action, you may be wondering which one is better. Before we can answer this, let’s step back a bit and talk about what history means.
One point of view on this is that your repository’s commit history is a record of what actually happened. It’s a historical document, valuable in its own right, and shouldn’t be tampered with. From this angle, changing the commit history is almost blasphemous; you’re lying about what actually transpired. So what if there was a messy series of merge commits? That’s how it happened, and the repository should preserve that for posterity.
The opposing point of view is that the commit history is the story of how your project was made.
You wouldn’t publish the first draft of a book, so why show your messy work?
When you’re working on a project, you may need a record of all your missteps and dead-end paths, but when it’s time to show your work to the world, you may want to tell a more coherent story of how to get from A to B.
People in this camp use tools like rebase and filter-branch to rewrite their commits before they’re merged into the mainline branch.
They use tools like rebase and filter-branch, to tell the story in the way that’s best for future readers.
Now, to the question of whether merging or rebasing is better: hopefully you’ll see that it’s not that simple. Git is a powerful tool, and allows you to do many things to and with your history, but every team and every project is different. Now that you know how both of these things work, it’s up to you to decide which one is best for your particular situation.
You can get the best of both worlds: rebase local changes before pushing to clean up your work, but never rebase anything that you’ve pushed somewhere.