
-
1. Aan de slag
- 1.1 Over versiebeheer
- 1.2 Een kort historisch overzicht van Git
- 1.3 Wat is Git?
- 1.4 De commando-regel
- 1.5 Git installeren
- 1.6 Git klaarmaken voor eerste gebruik
- 1.7 Hulp krijgen
- 1.8 Samenvatting
-
2. Git Basics
-
3. Branchen in Git
- 3.1 Branches in vogelvlucht
- 3.2 Eenvoudig branchen en mergen
- 3.3 Branch-beheer
- 3.4 Branch workflows
- 3.5 Branches op afstand (Remote branches)
- 3.6 Rebasen
- 3.7 Samenvatting
-
4. Git op de server
- 4.1 De protocollen
- 4.2 Git op een server krijgen
- 4.3 Je publieke SSH sleutel genereren
- 4.4 De server opzetten
- 4.5 Git Daemon
- 4.6 Slimme HTTP
- 4.7 GitWeb
- 4.8 GitLab
- 4.9 Hosting oplossingen van derden
- 4.10 Samenvatting
-
5. Gedistribueerd Git
-
6. GitHub
-
7. Git Tools
- 7.1 Revisie Selectie
- 7.2 Interactief stagen
- 7.3 Stashen en opschonen
- 7.4 Je werk tekenen
- 7.5 Zoeken
- 7.6 Geschiedenis herschrijven
- 7.7 Reset ontrafeld
- 7.8 Mergen voor gevorderden
- 7.9 Rerere
- 7.10 Debuggen met Git
- 7.11 Submodules
- 7.12 Bundelen
- 7.13 Vervangen
- 7.14 Het opslaan van inloggegevens
- 7.15 Samenvatting
-
8. Git aanpassen
- 8.1 Git configuratie
- 8.2 Git attributen
- 8.3 Git Hooks
- 8.4 Een voorbeeld van Git-afgedwongen beleid
- 8.5 Samenvatting
-
9. Git en andere systemen
- 9.1 Git als een client
- 9.2 Migreren naar Git
- 9.3 Samenvatting
-
10. Git Binnenwerk
- 10.1 Binnenwerk en koetswerk (plumbing and porcelain)
- 10.2 Git objecten
- 10.3 Git Referenties
- 10.4 Packfiles
- 10.5 De Refspec
- 10.6 Uitwisseling protocollen
- 10.7 Onderhoud en gegevensherstel
- 10.8 Omgevingsvariabelen
- 10.9 Samenvatting
-
A1. Bijlage A: Git in andere omgevingen
- A1.1 Grafische interfaces
- A1.2 Git in Visual Studio
- A1.3 Git in Visual Studio Code
- A1.4 Git in Eclipse
- A1.5 Git in Sublime Text
- A1.6 Git in Bash
- A1.7 Git in Zsh
- A1.8 Git in PowerShell
- A1.9 Samenvatting
-
A2. Bijlage B: Git in je applicaties inbouwen
- A2.1 Commando-regel Git
- A2.2 Libgit2
- A2.3 JGit
- A2.4 go-git
- A2.5 Dulwich
-
A3. Bijlage C: Git Commando’s
- A3.1 Setup en configuratie
- A3.2 Projecten ophalen en maken
- A3.3 Basic Snapshotten
- A3.4 Branchen en mergen
- A3.5 Projecten delen en bijwerken
- A3.6 Inspectie en vergelijking
- A3.7 Debuggen
- A3.8 Patchen
- A3.9 Email
- A3.10 Externe systemen
- A3.11 Beheer
- A3.12 Binnenwerk commando’s (plumbing commando’s)
1.3 Aan de slag - Wat is Git?
Wat is Git?
Dus, wat is Git in een notendop? Dit is een belangrijke paragraaf om in je op te nemen omdat, als je goed begrijpt wat Git is en de fundamenten van de interne werking begrijpt, het een stuk makkelijker wordt om Git effectief te gebruiken. Probeer, als je Git aan het leren bent, te vergeten wat je al weet over andere VCSen zoals CVS, Subversion of Perforce; zo kan je verwarring bij gebruik van Git door de subtiele verschillen voorkomen. Zelfs wanneer de gebruikers interface van Git redelijk gelijk is aan die van andere VCSen, slaat Git de gegevens anders op en kijkt heel anders naar de informatie, en deze verschillen begrijpen zal je helpen bij het voorkomen van verwarring tijdens het gebruik.
Momentopnames, geen verschillen
Het grootste verschil tussen Git en elke andere VCS (inclusief Subversion en consorten) is de manier waarop Git denkt over haar gegevens. Conceptueel bewaren de meeste andere systemen informatie als een lijst van veranderingen per bestand. Deze systemen (CVS, Subversion, Perforce, Bazaar, enzovoort) zien de informatie die ze bewaren als een groep bestanden en de veranderingen die aan die bestanden zijn aangebracht in de loop der tijd (dit wordt gewoonlijk beschreven als versiebeheer d.m.v. deltas).
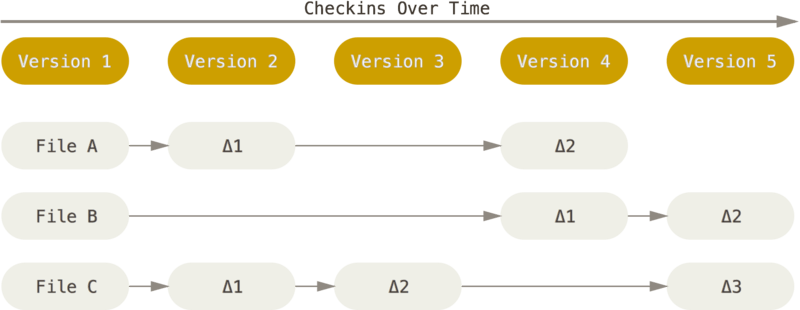
Git ziet en bewaart data heel anders. De kijk van Git op data kan worden uitgelegd als een reeks momentopnames (snapshots) van een miniatuur-bestandssysteem. Elke keer dat je commit (de status van je project in Git opslaat) wordt er als het ware foto van de toestand van al je bestanden op dat moment genomen en wordt er een verwijzing naar die foto opgeslagen. Uit oogpunt van efficiëntie slaat Git ongewijzigde bestanden niet elke keer opnieuw op, alleen een verwijzing naar het eerdere identieke bestand dat het eerder al opgeslagen had. Git beschouwt gegevens meer als een reeks van snapshots.
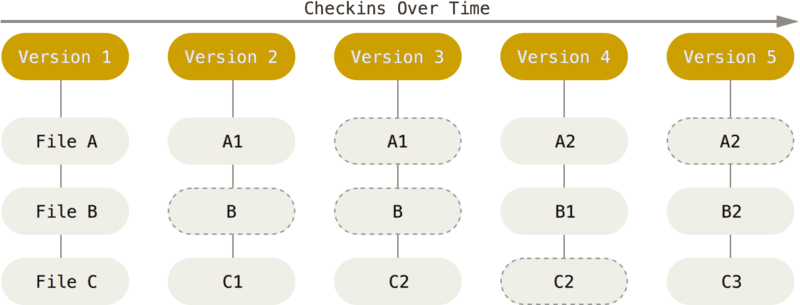
Dat is een belangrijk onderscheid tussen Git en bijna alle overige VCSen. Hierdoor moest Git bijna elk aspect van versiebeheer heroverwegen, terwijl de meeste andere systemen het hebben overgenomen van voorgaande generaties. Dit maakt Git meer een soort mini-bestandssysteem met een paar ongelooflijk krachtige gereedschappen, in plaats van niets meer een VCS. We zullen een paar van de voordelen die je krijgt als je op die manier over data denkt gaan onderzoeken, als we branchen (gesplitste ontwikkeling) toelichten in Branchen in Git.
Bijna alle handelingen zijn lokaal
Voor de meeste handelingen in Git zijn alleen lokale bestanden en hulpmiddelen nodig. Normaalgesproken is geen informatie nodig van een andere computer uit je netwerk. Als je gewend bent aan een CVCS, waar de meeste handelingen vertraagd worden door het netwerk, lijkt Git door de goden van snelheid begenadigd met bovennatuurlijke krachten. Omdat je de hele geschiedenis van het project op je lokale harde schijf hebt staan, lijken de meeste acties geen tijd in beslag te nemen.
Een voorbeeld: om de geschiedenis van je project te doorlopen hoeft Git niet bij een andere server de geschiedenis van je project op te vragen; het leest simpelweg jouw lokale database. Dat betekent dat je de geschiedenis van het project bijna direct te zien krijgt. Als je de veranderingen wilt zien tussen de huidige versie van een bestand en de versie van een maand geleden kan Git het bestand van een maand geleden opzoeken en lokaal de verschillen berekenen, in plaats van aan een niet-lokale server te moeten vragen om het te doen, of de oudere versie van het bestand ophalen van een server om het vervolgens lokaal te doen.
Dit betekent ook dat er maar heel weinig is dat je niet kunt doen als je offline bent of zonder VPN zit. Als je in een vliegtuig of trein zit en je wilt nog even wat werken, kan je vrolijk doorgaan met commits maken (naar je lokale kopie, weet je nog?) tot je een netwerkverbinding hebt en je dat werk kunt uploaden. Als je naar huis gaat en je VPN client niet aan de praat krijgt kan je nog steeds doorwerken. Bij veel andere systemen is dat onmogelijk of zeer onaangenaam. Als je bijvoorbeeld Perforce gebruikt kan je niet zo veel doen als je niet verbonden bent met de server. Met Subversion en CVS kun je bestanden bewerken maar je kunt geen commits maken naar je database (omdat die offline is). Dat lijkt misschien niet zo belangrijk maar je zult nog versteld staan wat voor een verschil het kan maken.
Git heeft integriteit
Alles in Git krijgt een controlegetal (checksum) voordat het wordt opgeslagen en er wordt later met dat controlegetal naar gerefereerd. Dat betekent dat het onmogelijk is om de inhoud van een bestand of directory te veranderen zonder dat Git er weet van heeft. Deze functionaliteit is in het diepste niveau van Git ingebouwd en staat centraal in zijn filosofie. Je kunt geen informatie kwijtraken tijdens transport en bestanden kunnen niet corrupt raken zonder dat Git het kan opmerken.
Het mechanisme dat Git gebruikt voor deze controlegetallen heet een SHA-1-hash. Dat is een tekenreeks van 40 karakters lang, bestaande uit hexadecimale tekens (0-9 en a-f) en wordt berekend uit de inhoud van een bestand of directory-structuur in Git. Een SHA-1-hash ziet er als volgt zo uit:
24b9da6552252987aa493b52f8696cd6d3b00373Je zult deze hashwaarden overal tegenkomen omdat Git er zoveel gebruik van maakt. Sterker nog, Git bewaart alles in haar database niet onder een bestandsnaam maar met de hash van de inhoud als sleutel.
Git voegt normaal gesproken alleen data toe
Bijna alles wat je in Git doet, leidt tot toevoeging van data in de Git database. Het is erg moeilijk om het systeem iets te laten doen wat je niet ongedaan kan maken of het de gegevens te laten wissen op wat voor manier dan ook. Zoals met elke VCS kun je wijzigingen verliezen of verhaspelen als je deze nog niet hebt gecommit; maar als je een snapshot hebt gecommit, is het erg moeilijk om die data te verliezen, zeker als je de lokale database regelmatig uploadt (met push) naar een andere repository.
Dit maakt het gebruik van Git zo plezierig omdat je weet dat je kunt experimenteren zonder het gevaar te lopen jezelf behoorlijk in de nesten te werken. Zie Dingen ongedaan maken voor een iets diepgaandere uitleg over hoe Git gegevens bewaart en hoe je de gegevens die verloren lijken kunt terughalen.
De drie toestanden
Let nu even goed op, dit is het belangrijkste wat je over Git moet weten als je wilt dat de rest van het leerproces gladjes verloopt. Git heeft drie hoofdtoestanden waarin bestanden zich kunnen bevinden: opgeslagen (commited), gewijzigd (modified) en voorbereid voor een commit (staged):
-
Committed houdt in dat alle data veilig opgeslagen is in je lokale database.
-
Modified betekent dat je het bestand hebt gewijzigd maar dat je nog niet naar je database gecommit hebt.
-
Staged betekent dat je al hebt aangegeven dat de huidige versie van het aangepaste bestand in je volgende commit meegenomen moet worden.
Dit brengt ons tot de drie hoofdonderdelen van een Git-project: de Git directory, de werk directory (working tree), en de wachtrij voor een commit (staging area).
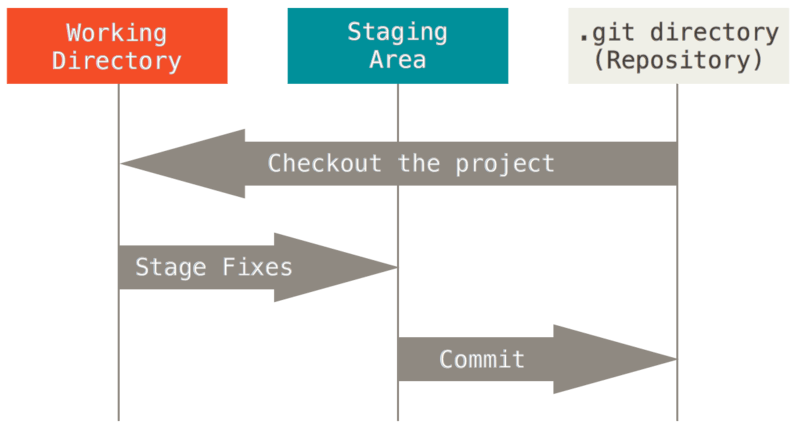
De Git directory is waar Git de metadata en objectdatabase van je project opslaat. Dit is het belangrijkste deel van Git, deze directory wordt gekopiëerd wanneer je een repository kloont (clone) vanaf een andere computer.
De working tree is een checkout van een bepaalde versie van het project. Deze bestanden worden uit de gecomprimeerde database in de Git directory gehaald en op de harde schijf geplaatst waar jij ze kunt gebruiken of bewerken.
De staging area is een bestand, dat zich normaalgesproken in je Git directory bevindt, waar informatie opgeslagen wordt over wat in de volgende commit meegaat. In Git vaktaal wordt dit de “index” genoemd, maar de zin “staging area” werkt net zo goed.
De algemene workflow met Git gaat ongeveer zo:
-
Je bewerkt bestanden in je working tree.
-
Je staged een selectie van die wijzigingen die je in de volgende commit wilt hebben, dit voegt alleen die wijzigingen in de staging area toe.
-
Je maakt een commit, hierbij worden snapshots gemaakt van alle bestanden in de staging area en verzameld en deze worden voorgoed in je Git directory bewaard.
Als een bepaalde versie van een bestand in de Git directory staat, wordt het beschouwd als commited. Als het is aangepast, maar wel al aan de staging area is toegevoegd, is het staged. En als het veranderd is sinds het was uitgechecked maar niet gestaged is, is het modified. In Git Basics leer je meer over deze toestanden en hoe je er je voordeel mee kunt doen, maar ook hoe je het stagen helemaal over kunt slaan.