
-
1. Aan de slag
- 1.1 Over versiebeheer
- 1.2 Een kort historisch overzicht van Git
- 1.3 Wat is Git?
- 1.4 De commando-regel
- 1.5 Git installeren
- 1.6 Git klaarmaken voor eerste gebruik
- 1.7 Hulp krijgen
- 1.8 Samenvatting
-
2. Git Basics
-
3. Branchen in Git
- 3.1 Branches in vogelvlucht
- 3.2 Eenvoudig branchen en mergen
- 3.3 Branch-beheer
- 3.4 Branch workflows
- 3.5 Branches op afstand (Remote branches)
- 3.6 Rebasen
- 3.7 Samenvatting
-
4. Git op de server
- 4.1 De protocollen
- 4.2 Git op een server krijgen
- 4.3 Je publieke SSH sleutel genereren
- 4.4 De server opzetten
- 4.5 Git Daemon
- 4.6 Slimme HTTP
- 4.7 GitWeb
- 4.8 GitLab
- 4.9 Hosting oplossingen van derden
- 4.10 Samenvatting
-
5. Gedistribueerd Git
-
6. GitHub
-
7. Git Tools
- 7.1 Revisie Selectie
- 7.2 Interactief stagen
- 7.3 Stashen en opschonen
- 7.4 Je werk tekenen
- 7.5 Zoeken
- 7.6 Geschiedenis herschrijven
- 7.7 Reset ontrafeld
- 7.8 Mergen voor gevorderden
- 7.9 Rerere
- 7.10 Debuggen met Git
- 7.11 Submodules
- 7.12 Bundelen
- 7.13 Vervangen
- 7.14 Het opslaan van inloggegevens
- 7.15 Samenvatting
-
8. Git aanpassen
- 8.1 Git configuratie
- 8.2 Git attributen
- 8.3 Git Hooks
- 8.4 Een voorbeeld van Git-afgedwongen beleid
- 8.5 Samenvatting
-
9. Git en andere systemen
- 9.1 Git als een client
- 9.2 Migreren naar Git
- 9.3 Samenvatting
-
10. Git Binnenwerk
- 10.1 Binnenwerk en koetswerk (plumbing and porcelain)
- 10.2 Git objecten
- 10.3 Git Referenties
- 10.4 Packfiles
- 10.5 De Refspec
- 10.6 Uitwisseling protocollen
- 10.7 Onderhoud en gegevensherstel
- 10.8 Omgevingsvariabelen
- 10.9 Samenvatting
-
A1. Bijlage A: Git in andere omgevingen
- A1.1 Grafische interfaces
- A1.2 Git in Visual Studio
- A1.3 Git in Visual Studio Code
- A1.4 Git in Eclipse
- A1.5 Git in Sublime Text
- A1.6 Git in Bash
- A1.7 Git in Zsh
- A1.8 Git in PowerShell
- A1.9 Samenvatting
-
A2. Bijlage B: Git in je applicaties inbouwen
- A2.1 Commando-regel Git
- A2.2 Libgit2
- A2.3 JGit
- A2.4 go-git
- A2.5 Dulwich
-
A3. Bijlage C: Git Commando’s
- A3.1 Setup en configuratie
- A3.2 Projecten ophalen en maken
- A3.3 Basic Snapshotten
- A3.4 Branchen en mergen
- A3.5 Projecten delen en bijwerken
- A3.6 Inspectie en vergelijking
- A3.7 Debuggen
- A3.8 Patchen
- A3.9 Email
- A3.10 Externe systemen
- A3.11 Beheer
- A3.12 Binnenwerk commando’s (plumbing commando’s)
10.2 Git Binnenwerk - Git objecten
Git objecten
Git is een op inhoud-adresseerbaar bestandssysteem. Mooi. Wat betekent dat nu eigenlijk? Het betekent dat in het hart van Git een eenvoudig sleutel-waarde gegevens opslag zit. Je kunt elke vorm van inhoud erin stoppen, en het zal je een sleutel teruggeven die je kunt gebruiken om de inhoud op elk gewenst moment weer op te halen.
Om dit te laten zien, zal je het plumbing commando hash-object gebruiken, die gegevens aanneemt, dit opslaat in je .git directory en je de sleutel teruggeeft waarmee de gegevens zijn opgeslagen.
Eerst, moet je een nieuwe Git repository initialiseren en vaststellen dat er niets in de objects directory zit:
$ git init test
Initialized empty Git repository in /tmp/test/.git/
$ cd test
$ find .git/objects
.git/objects
.git/objects/info
.git/objects/pack
$ find .git/objects -type fGit heeft nu de objects directory geinitialiseerd en daarin pack en info subdirectories aangemaakt, maar er zijn geen reguliere bestanden.
Nu sla je wat tekst op in je Git database:
$ echo 'test content' | git hash-object -w --stdin
d670460b4b4aece5915caf5c68d12f560a9fe3e4In het eenvoudigste vorm neemt het git hash-object de inhoud die je hem hebt gegeven en alleen maar de unieke sleutel teruggeven die zou worden gebuikt als je het zou opslaan in de Git database.
De -w vertelt hash-object om niet simpelweg de sleutel terug te geven maar om het object op te slaan in de database.
Tot slot vertelt de --stdin optie het commando om de te verwerken inhoud van stdin te lezen; als je dit niet aangeeft, verwacht het commando een bestands-argument aan het eind van het commando met daarin de inhoud die moet worden verwerkt.
De uitvoer van het commando is een 40-karakter checksum hash. Dit is de SHA-1 hash — een controlegetal van de inhoud die je opslaat plus een header, waar je iets later meer over gaat lezen. Nu kan je zien hoe Git je gegevens heeft opgeslagen:
$ find .git/objects -type f
.git/objects/d6/70460b4b4aece5915caf5c68d12f560a9fe3e4Als je weer je objects directoy gaat bekijken, kan je zien dat het nu een bestand bevat voor die nieuwe inhoud.
Dit is hoe Git de inhoud initieel opslaat — als een enkel bestand per stuk inhoud, met het SHA-1 controlegetal als naam die is berekend over de inhoud en de header.
De subdirectory heeft de eerste 2 karakters van de SHA-1 als naam, en de bestandsnaam is de overige 38 karakters.
Als je inhoud in je object database hebt, kan je de inhoud bekijken met het git cat-file commando.
Dit commando is een soort Zwitsers zakmes voor het inspecteren van Git objecten.
Met het doorgeven van -p vertel je het cat-file commando om het type inhoud uit te zoeken en het netjes aan je te laten zien:
$ git cat-file -p d670460b4b4aece5915caf5c68d12f560a9fe3e4
test contentNu ben je in staat om inhoud aan Git toe te voegen en om het er weer uit te halen. Je kunt dit ook met de inhoud van bestanden doen. Bijvoorbeeld, je kunt een eenvoudig versiebeheer op een bestand doen. Eerst, maak een nieuw bestand aan en bewaar de inhoud in je database:
$ echo 'version 1' > test.txt
$ git hash-object -w test.txt
83baae61804e65cc73a7201a7252750c76066a30Daarna schrijf je wat nieuwe inhoud naar het bestand, en bewaart het opnieuw:
$ echo 'version 2' > test.txt
$ git hash-object -w test.txt
1f7a7a472abf3dd9643fd615f6da379c4acb3e3aJe object database bevat beide versies van dit nieuwe bestand (zowel als de eerste inhoud die je daar bewaard hebt):
$ find .git/objects -type f
.git/objects/1f/7a7a472abf3dd9643fd615f6da379c4acb3e3a
.git/objects/83/baae61804e65cc73a7201a7252750c76066a30
.git/objects/d6/70460b4b4aece5915caf5c68d12f560a9fe3e4Op dit moment kan je je lokale kopie van dat test.txt bestand verwijderen, en dan Git gebruiken om uit de object database de eerste versie die je bewaard hebt:
$ git cat-file -p 83baae61804e65cc73a7201a7252750c76066a30 > test.txt
$ cat test.txt
version 1of de tweede versie op te halen:
$ git cat-file -p 1f7a7a472abf3dd9643fd615f6da379c4acb3e3a > test.txt
$ cat test.txt
version 2Maar de SHA-1 sleutel onthouden voor elke versie van je bestand is niet praktisch; plus je bewaart niet de bestandsnaam in je systeem — alleen de inhoud.
Dit type object noemen we een blob.
Je kunt Git je het objecttype laten vertellen van elk object in Git, gegeven de SHA-1 sleutel, met git cat-file -t:
$ git cat-file -t 1f7a7a472abf3dd9643fd615f6da379c4acb3e3a
blobBoom objecten (tree objects)
Het volgende type waar we naar gaan kijken is de tree, wat het probleem oplost van het opslaan van bestandsnamen en je ook in staat stelt om een groep van bestanden bij elkaar op te slaan. Git slaat de inhoud op een manier die vergelijkbaar is met een UNIX bestandssysteem, maar wat versimpeld. Alle inhoud wordt opgeslagen als tree en blob objecten, waarbij trees overeenkomen met UNIX directory entries en blobs min of meer overeenkomen met inodes of bestandsinhoud. Een enkele tree object bevat een of meer entries, elk daarvan is de SHA-1 hash van een blob of subtree met de bijbehorende mode, type en bestandsnaam. Bijvoorbeeld, de meest recente tree in een project kan er ongeveer zo uitzien:
$ git cat-file -p master^{tree}
100644 blob a906cb2a4a904a152e80877d4088654daad0c859 README
100644 blob 8f94139338f9404f26296befa88755fc2598c289 Rakefile
040000 tree 99f1a6d12cb4b6f19c8655fca46c3ecf317074e0 libDe master^{tree} syntax geeft het tree object aan waarnaar wordt verwezen door de laatste commit op je master-branch.
Merk op dat de lib subdirectory geen blob is, maar een verwijzing naar een andere tree:
$ git cat-file -p 99f1a6d12cb4b6f19c8655fca46c3ecf317074e0
100644 blob 47c6340d6459e05787f644c2447d2595f5d3a54b simplegit.rb|
Noot
|
Afhankelijk van de shell die je gebruikt, kan je fouten krijgen als je de In CMD op Windows is het Als je ZSH gebruikt, wordt het |
Conceptueel zijn de gegevens die Git opslaat ongeveer dit:

Je kunt redelijk eenvoudig je eigen boom maken.
Git maakt normaalgesproken een tree door de staat van je staging gebied of index te nemen en daarvan een reeks tree objects te maken.
Dus, om een tree object te maken, moet je eerst een index opzetten door wat bestanden te stagen.
Om een index te maken met een enkele ingang — de eerste versie van je test.txt bestand — kan je het plumbing commando git update-index gebruiken.
Je gebruikt dit commando om kunstmatig de eerdere versie van het bestand test.txt aan een nieuwe staging gebied toe te voegen.
Je moet het de optie --add doorgeven omdat het bestand nog niet bestaat in je staging gebied (je hebt nog niet eens een staging gebied ingericht) en --cacheinfo omdat het bestand dat je toevoegt in in je directory zit maar in je database.
Daarna geef je de mode, SHA-1 en bestandsnaam op:
$ git update-index --add --cacheinfo 100644 \
83baae61804e65cc73a7201a7252750c76066a30 test.txtIn dit geval geef je een mode 100644 op, wat aangeeft dat het een normaal bestand is.
Andere opties zijn 100755, wat aangeeft dat het een uitvoerbaar bestand is; en 120000, wat een symbolische link aangeeft.
De modus is afgeleid van normale UNIX modi maar het is minder flexibel — deze drie modi zijn de enige die geldig zijn voor bestanden (blobs) in Git (alhoewel andere modi worden gebruikt voor directories en submodules).
Nu kan je het git write-tree commando gebruiken om het staging gebied te schrijven naar een tree object.
Hier is geen -w optie nodig — het aanroepen van write-tree maakt automatisch een tree object aan van de staat van de index als die tree nog niet bestaat:
$ git write-tree
d8329fc1cc938780ffdd9f94e0d364e0ea74f579
$ git cat-file -p d8329fc1cc938780ffdd9f94e0d364e0ea74f579
100644 blob 83baae61804e65cc73a7201a7252750c76066a30 test.txtJe kunt ook verifiëren dat dit een tree object is met hetzelfde git cat-file commando die je eerder gezien hebt:
$ git cat-file -t d8329fc1cc938780ffdd9f94e0d364e0ea74f579
treeJe gaat nu een nieuwe tree maken met de tweede versie van test.txt en ook nog een nieuw bestand:
$ echo 'new file' > new.txt
$ git update-index test.txt
$ git update-index --add new.txtJe staging gebied heeft nu de nieuwe versie van test.txt alsook het nieuwe bestand new.txt.
Schrijf dat deze tree weg (sla de staat van het staging gebied of index op in een tree object) en kijk hoe dit eruit ziet:
$ git write-tree
0155eb4229851634a0f03eb265b69f5a2d56f341
$ git cat-file -p 0155eb4229851634a0f03eb265b69f5a2d56f341
100644 blob fa49b077972391ad58037050f2a75f74e3671e92 new.txt
100644 blob 1f7a7a472abf3dd9643fd615f6da379c4acb3e3a test.txtMerk op dat deze tree beide bestands entries bevat en ook dat de test.txt SHA-1 gelijk aan de “versie 2” SHA-1 van eerder is (1f7a7a).
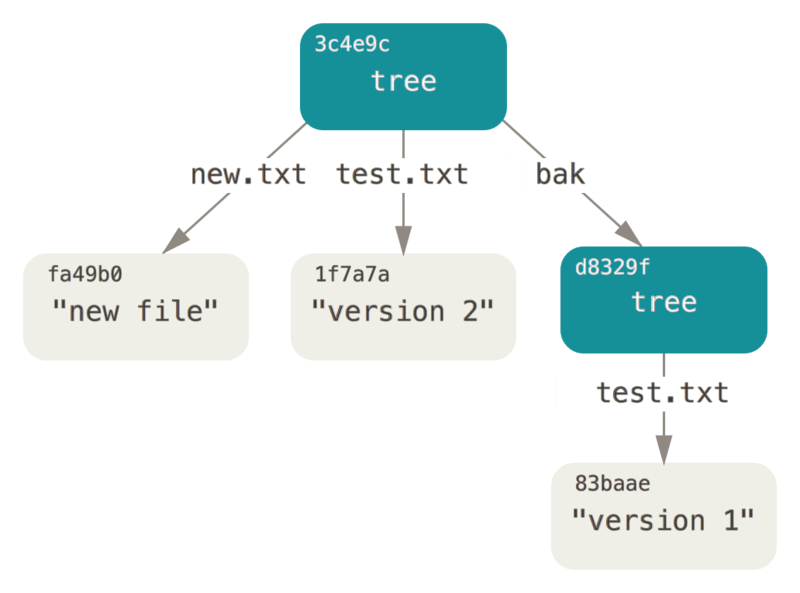
Puur voor de lol, ga je de eerste tree als een subdirectory toevoegen in deze.
Je kunt trees in je staging area lezen door git read-tree aan te roepen.
In dit geval, kan je een bestaande tree als een subtree in je staging gebied lezen door de --prefix optie te gebruiken bij dit commando:
$ git read-tree --prefix=bak d8329fc1cc938780ffdd9f94e0d364e0ea74f579
$ git write-tree
3c4e9cd789d88d8d89c1073707c3585e41b0e614
$ git cat-file -p 3c4e9cd789d88d8d89c1073707c3585e41b0e614
040000 tree d8329fc1cc938780ffdd9f94e0d364e0ea74f579 bak
100644 blob fa49b077972391ad58037050f2a75f74e3671e92 new.txt
100644 blob 1f7a7a472abf3dd9643fd615f6da379c4acb3e3a test.txtAls je een werk directory van de nieuwe tree maakt die je zojuist geschreven hebt, zou je de twee bestanden op het
hoogste niveau van de werk directory krijgen en een subdirectory met de naam bak die de eerste versie van het
test.txt bestand zou bevatten.
Je kunt de gegevens die Git bevat voor deze structuren als volgt weergeven:
Commit objecten
Je hebt drie trees die de verschillende snapshots weergeven van je project die je wilt volgen, maar het eerdere probleem blijft: je moet alle drie SHA-1 waarden onthouden om de snapshots te kunnen terughalen. Je hebt ook geen informatie over wie de snapshots heeft opgeslagen, wanneer ze zijn opgeslagen of waarom ze waren opgeslagen. Dit is de basis informatie die het commit object voor je opslaat.
Om een commit object te maken, roep je commit-tree aan en geef je een de SHA-1 van een enkele tree op en welke commit objecten, indien van toepassing, er direct aan vooraf gaan.
Begin met de eerste tree die je geschreven hebt:
$ echo 'first commit' | git commit-tree d8329f
fdf4fc3344e67ab068f836878b6c4951e3b15f3dJe zult verschillende hash-waarden krijgen omdat er verschillen zijn in aanmaak tijd en auteur-gegevens.
Vervang de commit en tag-hashwaarden verderop in dit hoofdstuk met je eigen checksums.
Nu kan je naar je nieuwe commit object kijken met git cat-file:
$ git cat-file -p fdf4fc3
tree d8329fc1cc938780ffdd9f94e0d364e0ea74f579
author Scott Chacon <schacon@gmail.com> 1243040974 -0700
committer Scott Chacon <schacon@gmail.com> 1243040974 -0700
first commitHet formaat voor een commit object is eenvoudig: het geeft de tree op het hoogste niveau weer voor de snapshot van het project op dat punt; de commits van de ouder (het commit object beschreven hierboven heeft geen enkele ouder); de auteur/committer informatie (welke je user.name en user.email configuratie instellingen gebruikt en een timestamp); een blanko regel en dan het commit bericht.
Vervolgens ga je de andere twee commit objects schrijven, die elk naar de commit refereren die er direct aan vooraf ging:
$ echo 'second commit' | git commit-tree 0155eb -p fdf4fc3
cac0cab538b970a37ea1e769cbbde608743bc96d
$ echo 'third commit' | git commit-tree 3c4e9c -p cac0cab
1a410efbd13591db07496601ebc7a059dd55cfe9Elk van de drie commit objecten verwijzen naar een van de drie snapshot trees die je gemaakt hebt.
Gek genoeg, heb je nu een echte Git historie die je kunt bekijken met het git log commando, als je dit aanroept op de laatste SHA-1 commit:
$ git log --stat 1a410e
commit 1a410efbd13591db07496601ebc7a059dd55cfe9
Author: Scott Chacon <schacon@gmail.com>
Date: Fri May 22 18:15:24 2009 -0700
third commit
bak/test.txt | 1 +
1 file changed, 1 insertion(+)
commit cac0cab538b970a37ea1e769cbbde608743bc96d
Author: Scott Chacon <schacon@gmail.com>
Date: Fri May 22 18:14:29 2009 -0700
second commit
new.txt | 1 +
test.txt | 2 +-
2 files changed, 2 insertions(+), 1 deletion(-)
commit fdf4fc3344e67ab068f836878b6c4951e3b15f3d
Author: Scott Chacon <schacon@gmail.com>
Date: Fri May 22 18:09:34 2009 -0700
first commit
test.txt | 1 +
1 file changed, 1 insertion(+)Verbluffend.
Je hebt zojuist de diepere niveau operaties uitgevoerd die een Git historie hebben opgebouwd, zonder gebruik te maken van een van de hogere commando’s.
In essentie is dit wat Git doet als je de git add en git commit commando’s gebuikt — het slaat blobs op voor de bestanden die zijn gewijzigd, werkt de index bij, schrijft de trees weg en schrijft commit objecten weg die verwijzen naar de trees op het hoogste niveau en de commits die er direct aan vooraf zijn gegaan.
Deze drie hoofd Git objecten — de blob, de tree en de commit worden initieel opgeslagen als aparte bestanden in je .git/objects directory.
Hier zijn alle huidige objecten in de voorbeeld directory, met als commentaar wat ze opslaan:
$ find .git/objects -type f
.git/objects/01/55eb4229851634a0f03eb265b69f5a2d56f341 # tree 2
.git/objects/1a/410efbd13591db07496601ebc7a059dd55cfe9 # commit 3
.git/objects/1f/7a7a472abf3dd9643fd615f6da379c4acb3e3a # test.txt v2
.git/objects/3c/4e9cd789d88d8d89c1073707c3585e41b0e614 # tree 3
.git/objects/83/baae61804e65cc73a7201a7252750c76066a30 # test.txt v1
.git/objects/ca/c0cab538b970a37ea1e769cbbde608743bc96d # commit 2
.git/objects/d6/70460b4b4aece5915caf5c68d12f560a9fe3e4 # 'test content'
.git/objects/d8/329fc1cc938780ffdd9f94e0d364e0ea74f579 # tree 1
.git/objects/fa/49b077972391ad58037050f2a75f74e3671e92 # new.txt
.git/objects/fd/f4fc3344e67ab068f836878b6c4951e3b15f3d # commit 1Als je al de interne verwijzingen volgt, zal je een objectgraaf krijgen die er ongeveer zo uitziet:

Object opslag
We hebben eerder gezegd dat er een header wordt opgeslagen bij de inhoud. Laten we nu de tijd nemen om een kijkje te nemen hoe Git haar objecten opslaat. Je gaat zien hoe een blob object interactief wordt opgeslagen — in dit geval, de zin “what is up, doc?” — in de Ruby scripttaal.
Je kunt de interactieve Ruby modus starten met het irb commando:
$ irb
>> content = "what is up, doc?"
=> "what is up, doc?"Git stelt een header samen die begint met het type van het object, in dit geval een blob. Aan dat eerste gedeelte van de header voegt Git een spatie toe gevolgd door de lengte in bytes van de inhoud en tot slot een null byte:
>> header = "blob #{content.length}\0"
=> "blob 16\u0000"Git plakt de header en de oorspronkelijke inhoud samen en berekent het SHA-1 controlegetal van die nieuwe inhoud.
Je kunt de SHA-1 waarde van een tekenreeks in Ruby berekenen door de SHA1 digest library te includen met het require commando en daarna Digest::SHA1.hexdigest() aan te roepen met de tekenreeks:
>> store = header + content
=> "blob 16\u0000what is up, doc?"
>> require 'digest/sha1'
=> true
>> sha1 = Digest::SHA1.hexdigest(store)
=> "bd9dbf5aae1a3862dd1526723246b20206e5fc37"Laten we dit vergelijken met de uitvoer van git hash-object.
Hier gebruiken we echo -n om te voorkomen dat er een newline aan de invoer wordt toegevoegd.
$ echo -n "what is up, doc?" | git hash-object --stdin
bd9dbf5aae1a3862dd1526723246b20206e5fc37Git comprimeert de nieuwe inhoud met zlib, wat je in Ruby kunt doen met de zlib library.
Eerst moet je de library requiren en daarna Zlib::Deflate.deflate() aanroepen op de inhoud:
>> require 'zlib'
=> true
>> zlib_content = Zlib::Deflate.deflate(store)
=> "x\x9CK\xCA\xC9OR04c(\xCFH,Q\xC8,V(-\xD0QH\xC9O\xB6\a\x00_\x1C\a\x9D"Als laatste schrijf je je zlib-deflated inhoud naar een object op schijf.
Je bepaalt het pad van het object die je wilt schrijven (de eerste twee karakters van de SHA-1 waarde als de naam van de subdirectory, en de overige 38 karakters zijnde de bestandsnaam binnen die directory).
In Ruby kan je de FileUtils.mkdir_p() functie gebruiken om de subdirectory aan te maken als die nog niet bestaat.
Daarna open je het bestand met File.open() en schrijf je de eerder zlib-gecomprimeerde inhoud naar het bestand met een write() aanroep op de filehandle die je krijgt:
>> path = '.git/objects/' + sha1[0,2] + '/' + sha1[2,38]
=> ".git/objects/bd/9dbf5aae1a3862dd1526723246b20206e5fc37"
>> require 'fileutils'
=> true
>> FileUtils.mkdir_p(File.dirname(path))
=> ".git/objects/bd"
>> File.open(path, 'w') { |f| f.write zlib_content }
=> 32Laten we de inhoud van het object controleren met git cat-file:
---
$ git cat-file -p bd9dbf5aae1a3862dd1526723246b20206e5fc37
what is up, doc?
---Dat is alles - je hebt een valide Git blob object gemaakt.
Alle Git objecten worden op dezelfde manier opgeslagen, alleen met andere types - in plaats van de tekenreeks blob, begint de header met commit of tree. Daarnaast, alhoewel de inhoud van een blob zo ongeveer alles kan zijn, is de inhoud van een commit en tree zeer specifiek geformatteerd.