
-
1. Aan de slag
- 1.1 Over versiebeheer
- 1.2 Een kort historisch overzicht van Git
- 1.3 Wat is Git?
- 1.4 De commando-regel
- 1.5 Git installeren
- 1.6 Git klaarmaken voor eerste gebruik
- 1.7 Hulp krijgen
- 1.8 Samenvatting
-
2. Git Basics
-
3. Branchen in Git
- 3.1 Branches in vogelvlucht
- 3.2 Eenvoudig branchen en mergen
- 3.3 Branch-beheer
- 3.4 Branch workflows
- 3.5 Branches op afstand (Remote branches)
- 3.6 Rebasen
- 3.7 Samenvatting
-
4. Git op de server
- 4.1 De protocollen
- 4.2 Git op een server krijgen
- 4.3 Je publieke SSH sleutel genereren
- 4.4 De server opzetten
- 4.5 Git Daemon
- 4.6 Slimme HTTP
- 4.7 GitWeb
- 4.8 GitLab
- 4.9 Hosting oplossingen van derden
- 4.10 Samenvatting
-
5. Gedistribueerd Git
-
6. GitHub
-
7. Git Tools
- 7.1 Revisie Selectie
- 7.2 Interactief stagen
- 7.3 Stashen en opschonen
- 7.4 Je werk tekenen
- 7.5 Zoeken
- 7.6 Geschiedenis herschrijven
- 7.7 Reset ontrafeld
- 7.8 Mergen voor gevorderden
- 7.9 Rerere
- 7.10 Debuggen met Git
- 7.11 Submodules
- 7.12 Bundelen
- 7.13 Vervangen
- 7.14 Het opslaan van inloggegevens
- 7.15 Samenvatting
-
8. Git aanpassen
- 8.1 Git configuratie
- 8.2 Git attributen
- 8.3 Git Hooks
- 8.4 Een voorbeeld van Git-afgedwongen beleid
- 8.5 Samenvatting
-
9. Git en andere systemen
- 9.1 Git als een client
- 9.2 Migreren naar Git
- 9.3 Samenvatting
-
10. Git Binnenwerk
- 10.1 Binnenwerk en koetswerk (plumbing and porcelain)
- 10.2 Git objecten
- 10.3 Git Referenties
- 10.4 Packfiles
- 10.5 De Refspec
- 10.6 Uitwisseling protocollen
- 10.7 Onderhoud en gegevensherstel
- 10.8 Omgevingsvariabelen
- 10.9 Samenvatting
-
A1. Bijlage A: Git in andere omgevingen
- A1.1 Grafische interfaces
- A1.2 Git in Visual Studio
- A1.3 Git in Visual Studio Code
- A1.4 Git in Eclipse
- A1.5 Git in Sublime Text
- A1.6 Git in Bash
- A1.7 Git in Zsh
- A1.8 Git in PowerShell
- A1.9 Samenvatting
-
A2. Bijlage B: Git in je applicaties inbouwen
- A2.1 Commando-regel Git
- A2.2 Libgit2
- A2.3 JGit
- A2.4 go-git
- A2.5 Dulwich
-
A3. Bijlage C: Git Commando’s
- A3.1 Setup en configuratie
- A3.2 Projecten ophalen en maken
- A3.3 Basic Snapshotten
- A3.4 Branchen en mergen
- A3.5 Projecten delen en bijwerken
- A3.6 Inspectie en vergelijking
- A3.7 Debuggen
- A3.8 Patchen
- A3.9 Email
- A3.10 Externe systemen
- A3.11 Beheer
- A3.12 Binnenwerk commando’s (plumbing commando’s)
5.2 Gedistribueerd Git - Bijdragen aan een project
Bijdragen aan een project
De grote moeilijkheid bij het beschrijven van dit proces is dat er een enorm aantal variaties mogelijk zijn in hoe het gebeurt. Om dat Git erg flexibel is, kunnen en zullen mensen op vele manieren samenwerken, en het is lastig om te beschrijven hoe je zou moeten bijdragen aan een project — ieder project is net weer een beetje anders. Een aantal van de betrokken variabelen zijn het aantal actieve bijdragers, gekozen workflow, je commit toegang, en mogelijk de manier waarop externe bijdragen worden gedaan.
De eerste variabele is het aantal actieve bijdragers. Hoeveel gebruikers dragen actief code bij aan dit project, en hoe vaak? In veel gevallen zal je twee of drie ontwikkelaars met een paar commits per dag hebben, of misschien minder voor wat meer slapende projecten. Voor zeer grote bedrijven of projecten kan het aantal ontwikkelaars in de duizenden lopen, met tientallen of zelfs honderden patches die iedere dag binnenkomen. Dit is belangrijk omdat met meer en meer ontwikkelaars, je meer en meer problemen tegenkomt bij het je verzekeren dat code netjes gepatched of eenvoudig gemerged kan worden. Wijzigingen die je indient kunnen verouderd of zwaar beschadigd raken door werk dat gemerged is terwijl je ermee aan het werken was, of terwijl je wijzigingen in de wacht stonden voor goedkeuring of toepassing. Hoe kun je jouw code consequent up-to-date en je patches geldig houden?
De volgende variabele is de gebruikte workflow in het project. Is het gecentraliseerd, waarbij iedere ontwikkelaar gelijkwaardige schrijftoegang heeft tot de hoofd codebasis? Heeft het project een eigenaar of integrator die alle patches controleert? Worden alle patches ge(peer)reviewed en goedgekeurd? Ben jij betrokken bij dat proces? Is er een luitenanten systeem neergezet, en moet je je werk eerst bij hen inleveren?
De volgende variabele is je commit toegang. De benodigde workflow om bij te dragen aan een project is heel anders als je schrijftoegang hebt tot het project dan wanneer je dat niet hebt. Als je geen schrijftoegang hebt, wat is de voorkeur van het project om bijdragen te ontvangen? Is er überhaupt een beleid? Hoeveel werk draag je per keer bij? Hoe vaak draag je bij?
Al deze vragen kunnen van invloed zijn op hoe je effectief bijdraagt aan een project en welke workflows de voorkeur hebben of beschikbaar zijn. We zullen een aantal van deze aspecten behandelen in een aantal voorbeelden, waarbij we van eenvoudig tot complexzullen gaan. Je zou in staat moeten zijn om de specifieke workflows die je in jouw praktijk nodig hebt te kunnen herleiden naar deze voorbeelden.
Commit richtlijnen
Voordat we gaan kijken naar de specifieke gebruiksscenario’s, volgt hier een kort stukje over commit berichten.
Het hebben van een goede richtlijn voor het maken commits en je daar aan houden maakt het werken met Git en samenwerken met anderen een stuk makkelijker.
Het Git project levert een document waarin een aantal goede tips staan voor het maken van commits waaruit je patches kunt indienen — je kunt het lezen in de Git broncode in het Documentation/SubmittingPatches bestand.
Als eerste wil je geen witruimte-fouten indienen.
Git geeft je een eenvoudige manier om hierop te controleren — voordat je commit, voer git diff --check uit, wat mogelijke witruimte-fouten identificeert en ze voor je afdrukt.
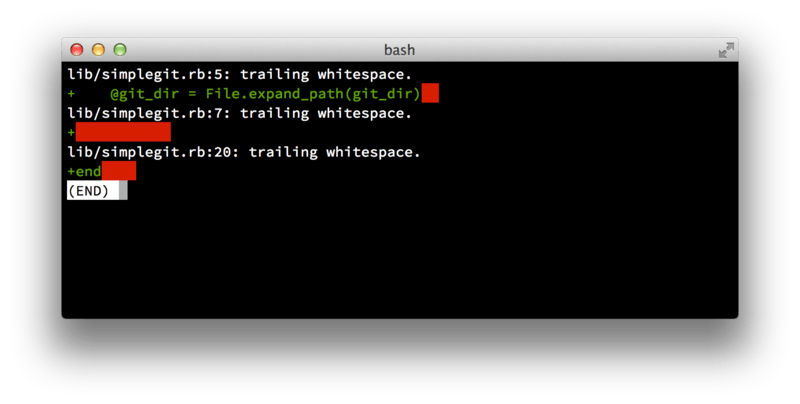
git diff --check.Als je dat commando uitvoert alvorens te committen, kun je al zien of je op het punt staat witruimte problemen te committen waaraan andere ontwikkelaars zich zouden kunnen ergeren.
Probeer vervolgens om van elke commit een logische set wijzigingen te maken.
Probeer, als het je lukt, om je wijzigingen verteerbaar te houden — ga niet het hele weekend zitten coderen op vijf verschillende problemen om dat vervolgens op maandag als één gigantische commit in te dienen.
Zelfs als je gedurende het weekend niet commit, gebruik dan het staging gebied op maandag om je werk in ten minste één commit per probleem op te splitsen, met een bruikbaar bericht per commit.
Als een paar van de wijzigingen hetzelfde bestand betreffen, probeer dan git add --patch te gebruiken om bestanden gedeeltelijk te stagen (in detail behandeld in Interactief stagen).
De snapshot aan de kop van het project is gelijk of je nu één commit doet of vijf, zolang alle wijzigingen op een gegeven moment maar toegevoegd zijn, probeer dus om het je mede-ontwikkelaars makkelijk te maken als ze je wijzigingen moeten beoordelen.
Deze aanpak maakt het ook makkelijker om één wijziging eruit te selecteren of terug te draaien, mocht dat later nodig zijn. Geschiedenis herschrijven beschrijft een aantal handige Git trucs om geschiedenis te herschrijven en bestanden interactief te stagen — gebruik deze instrumenten als hulp om een schone en begrijpelijke historie op te bouwen voordat deze naar iemand anders wordt gestuurd.
Het laatste om in gedachten te houden is het commit bericht. Als je er een gewoonte van maakt om commit berichten van goede kwaliteit aan te maken, dan maakt dat het gebruik van en samenwerken in Git een stuk eenvoudiger. In het algemeen zouden je berichten moeten beginnen met een enkele regel die niet langer is dan 50 karakters en die de wijzigingen beknopt omschrijft, gevolgd door een lege regel en daarna een meer gedetailleerde uitleg. Het Git project vereist dat de meer gedetailleerde omschrijving ook je motivatie voor de verandering bevat, en de nieuwe implementatie tegen het oude gedrag afzet — dit is een goede richtlijn om te volgen. Het is ook een goed idee om de gebiedende wijs te gebruiken in deze berichten. Met andere woorden, schrijf: "Los fout op" en niet "Fout opgelost" of "Dit lost fout op". Hier is een sjabloon dat origineel geschreven is door Tim Pope:
Capitalized, short (50 chars or less) summary
More detailed explanatory text, if necessary. Wrap it to about 72
characters or so. In some contexts, the first line is treated as the
subject of an email and the rest of the text as the body. The blank
line separating the summary from the body is critical (unless you omit
the body entirely); tools like rebase can get confused if you run the
two together.
Write your commit message in the imperative: "Fix bug" and not "Fixed bug"
or "Fixes bug." This convention matches up with commit messages generated
by commands like git merge and git revert.
Further paragraphs come after blank lines.
- Bullet points are okay, too
- Typically a hyphen or asterisk is used for the bullet, followed by a
single space, with blank lines in between, but conventions vary here
- Use a hanging indentAls al je commit berichten er zo uit zien, dan zullen de dingen een stuk eenvoudiger zijn voor jou en de ontwikkelaars waar je mee samenwerkt.
Het Git project heeft goed geformatteerde commit berichten - ik raad je aan om git log --no-merges uit te voeren om te zien hoe een goed geformatteerde project-commit historie eruit ziet.
|
Noot
|
Doe wat wij zeggen, niet wat wij doen.
In de volgende voorbeelden en verder door de rest van dit boek, zijn omwille van bondigheid, de berichten niet zo netjes geformateerd als dit; in plaats daarvan gebruiken we de Kortom: doe wat wij zeggen, niet wat wij doen. |
Besloten klein team
De eenvoudigste opzet die je waarschijnlijk zult tegenkomen is een besloten project met één of twee andere ontwikkelaars. Met “besloten” bedoel ik gesloten broncode — zonder leestoegang voor de buitenwereld. Jij en de andere ontwikkelaars hebben allemaal push toegang op de repository.
In deze omgeving kan je een workflow aanhouden die vergelijkbaar is met wat je zou doen als je Subversion of een andere gecentraliseerd systeem zou gebruiken.
Je hebt nog steeds de voordelen van zaken als offline committen en veel eenvoudiger branchen en mergen, maar de workflow kan erg vergelijkbaar zijn. Het grootste verschil is dat het mergen aan de client-kant gebeurt en niet tijdens het committen aan de server-kant.
Laten we eens kijken hoe het er uit zou kunnen zien als twee ontwikkelaars samen beginnen te werken met een gedeelde repository.
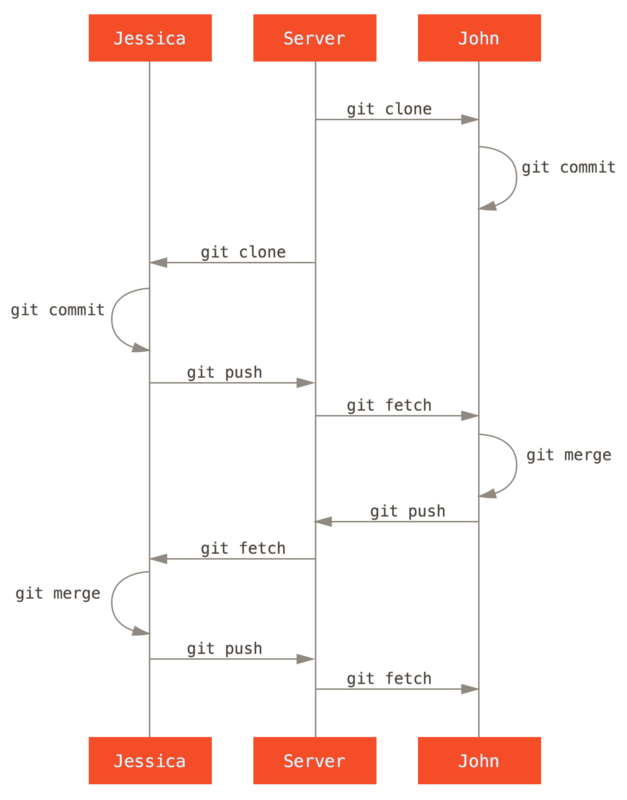
De eerste ontwikkelaar, John, kloont de repository, maakt een wijziging, en commit lokaal.
(De protocol berichten zijn met ... vervangen in deze voorbeelden om ze iets in te korten.)
# John's Machine
$ git clone john@githost:simplegit.git
Cloning into 'simplegit'...
...
$ cd simplegit/
$ vim lib/simplegit.rb
$ git commit -am 'remove invalid default value'
[master 738ee87] remove invalid default value
1 files changed, 1 insertions(+), 1 deletions(-)De tweede ontwikkelaar, Jessica, doet hetzelfde — kloont de repository en commit een wijziging:
# Jessica's Machine
$ git clone jessica@githost:simplegit.git
Cloning into 'simplegit'...
...
$ cd simplegit/
$ vim TODO
$ git commit -am 'add reset task'
[master fbff5bc] add reset task
1 files changed, 1 insertions(+), 0 deletions(-)Nu pusht Jessica haar werk naar de server, en dat werkt prima:
# Jessica's Machine
$ git push origin master
...
To jessica@githost:simplegit.git
1edee6b..fbff5bc master -> masterDe laatste regel van de uitvoer hierboven laat een bruikbaar bericht zien van de push-operatie.
Het basis-formaat is <oldref>..<newref> fromref -> toref, waar oldref de oude reference inhoudt, newref betekent de nieuwe referentie, fromref is de naam van de lokale referentie die gepusht wordt, en toref is de naam van de remote referentie die wordt geupdate.
Je zult een vergelijkbare uitvoer zien in de behandeling hieronder, dus een basis inzicht hebben in de betekenins zal helpen met het begrijpen van de verschillende stadia van de repositories.
Meer details zijn beschikbaar in de documentie van git-push.
We gaan door met het voorbeeld, John maakt wat wijzigingen, commit deze naar zijn lokale repository en probeert ze naar dezelfde server te pushen:
# John's Machine
$ git push origin master
To john@githost:simplegit.git
! [rejected] master -> master (non-fast forward)
error: failed to push some refs to 'john@githost:simplegit.git'In dit geval zal de push van John falen, vanwege de eerdere push van Jessica met haar wijzigingen. Dit is belangrijk om te begrijpen als je gewend bent aan Subversion, omdat het je zal opvallen dat de twee ontwikkelaars niet hetzelfde bestand hebben aangepast. Waar Subversion automatisch zo’n merge op de server doet als verschillende bestanden zijn aangepast, moet je in Git de commits eerst lokaal mergen. Met andere wooren: John moet eerst Jessica’s wijzigingen ophalen en ze in zijn lokale repository mergen voor hij mag pushen:
Als eerste stap, gaat John Jessica’s werk eerst fetchen (dit zal alleen Jessica’s werk fetchen, het zal het nog niet in John’s werk mergen):
$ git fetch origin
...
From john@githost:simplegit
+ 049d078...fbff5bc master -> origin/masterHierna ziet de lokale repository van John er ongeveer zo uit:
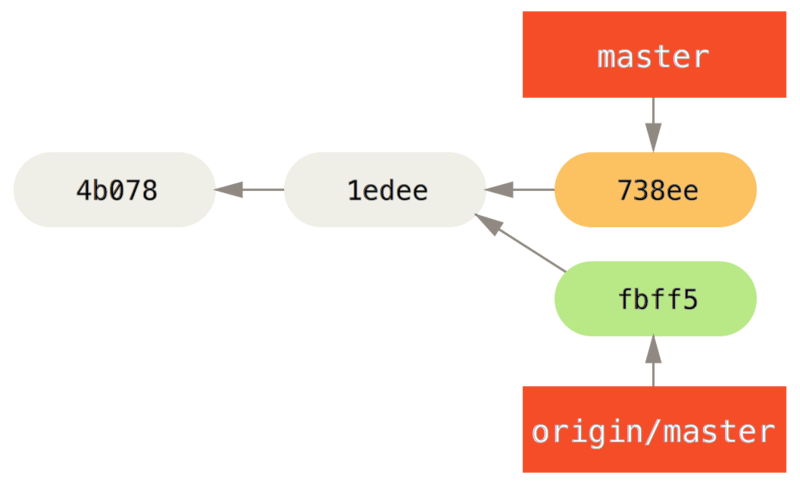
Nu kan John het werk van Jessica dat hij heeft gefetcht gaan mergen in zijn lokale werk.
$ git merge origin/master
Merge made by the 'recursive' strategy.
TODO | 1 +
1 files changed, 1 insertions(+), 0 deletions(-)Zo lang als de lokale merge gladjes verloopt, zal John’s geupdate history er zo uit zien:
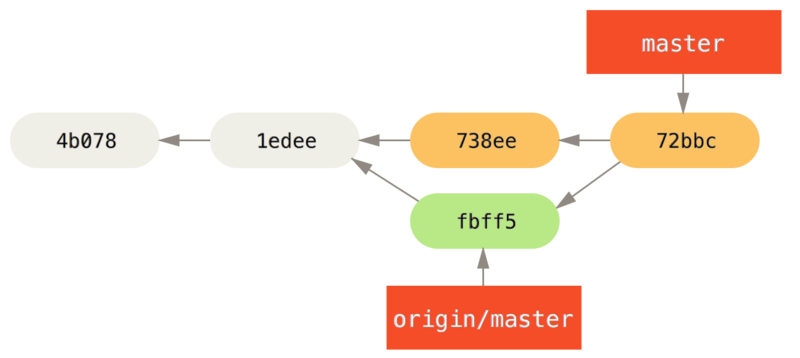
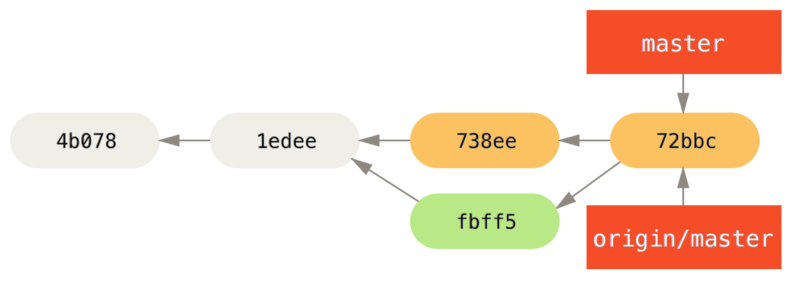
origin/master te hebben gemerged.Nu zou John zijn code moeten testen om er zeker van te zijn dat alles nog steeds goed werkt, en dan kan hij zijn nieuwe gemergede werk pushen naar de server:
$ git push origin master
...
To john@githost:simplegit.git
fbff5bc..72bbc59 master -> masterUiteindelijk ziet de commit historie van John er zo uit:
origin server.In de tussentijd heeft Jessica een topic branch genaamd issue54 aangemaakt en daar drie commits op gedaan.
Ze heeft John’s wijzigingen nog niet opgehaald, dus haar commit historie ziet er zo uit:
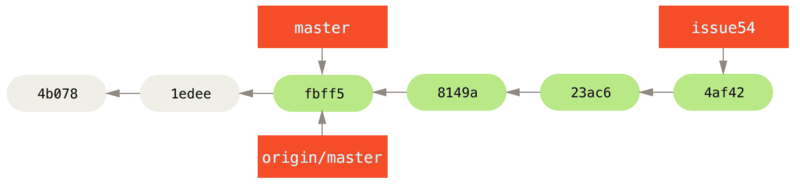
Ineens hoort Jessica dat John nieuw werk heeft gepusht op de server en ze wil dit even gaan bekijken, zodat ze alle inhoud van de server kan ophalen dat ze nog niet heeft met:
# Jessica's Machine
$ git fetch origin
...
From jessica@githost:simplegit
fbff5bc..72bbc59 master -> origin/masterDit haalt het werk op dat John in de tussentijd gepusht heeft. De historie van Jessica ziet er nu zo uit:
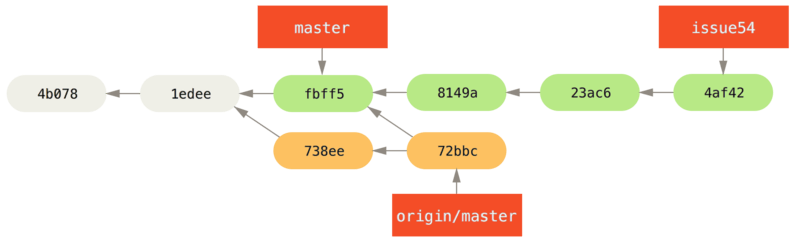
Jessica denkt dat haar topic branch nu klaar is, maar ze wil weten wat ze in haar werk moet mergen zodat ze kan pushen.
Ze voert git log uit om dat uit te zoeken:
$ git log --no-merges issue54..origin/master
commit 738ee872852dfaa9d6634e0dea7a324040193016
Author: John Smith <jsmith@example.com>
Date: Fri May 29 16:01:27 2009 -0700
removed invalid default valueDe issue54..origin/master syntax is een log filter dat Git vraagt om alleen de lijst van commits te tonen die op de laatstgenoemde branch (in dit geval origin/master) staan die niet in de eerstegenoemde (in dit geval issue54) staan.
We zullen deze syntax in detail bespreken in Commit reeksen.
Nu zien we in de uitvoer dat er een commit is die John gemaakt heeft die Jessica nog niet gemerged heeft.
Als ze origin/master merged, is dat de enige commit die haar lokale werk zal wijzigen.
Nu kan Jessica het werk van haar topic branch mergen in haar master branch, het werk van John (origin/master) in haar master-branch mergen, en dan naar de server pushen.
Eerst (nadat ze al haar werk op de issue54 topic branch heeft gecommit) schakelt Jessica terug naar haar master branch als voorbereiding op het integreren van al dit werk:
$ git checkout master
Switched to branch 'master'
Your branch is behind 'origin/master' by 2 commits, and can be fast-forwarded.Ze kan origin/master of issue54 als eerste mergen — ze zijn beide stroomopwaarts dus de volgorde maakt niet uit.
Uiteindelijk zou de snapshot gelijk moeten zijn ongeacht welke volgorde ze kiest; alleen de geschiedenis zal iets verschillen.
Ze kiest ervoor om issue54 eerst te mergen:
$ git merge issue54
Updating fbff5bc..4af4298
Fast forward
README | 1 +
lib/simplegit.rb | 6 +++++-
2 files changed, 6 insertions(+), 1 deletions(-)Er doen zich geen problemen voor, zoals je kunt zien was het een eenvoudige fast-forward.
Jessica voltooit het lokale merge proces met het mergen van John’s eerder opgehaalde werk die in de origin/master-branch zit:
$ git merge origin/master
Auto-merging lib/simplegit.rb
Merge made by the 'recursive' strategy.
lib/simplegit.rb | 2 +-
1 files changed, 1 insertions(+), 1 deletions(-)Alles merget netjes, en de historie van Jessica ziet er nu zo uit:
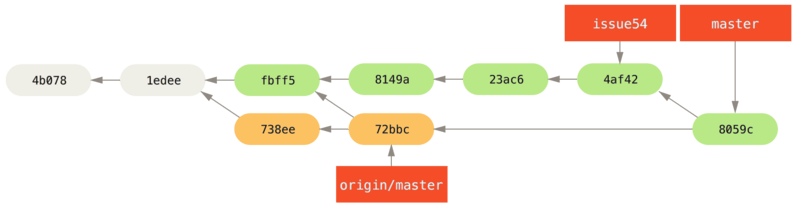
Nu is origin/master bereikbaar vanuit Jessica’s master-branch, dus ze zou in staat moeten zijn om succesvol te pushen (even aangenomen dat John in de tussentijd niet weer iets gepusht heeft):
$ git push origin master
...
To jessica@githost:simplegit.git
72bbc59..8059c15 master -> masterIedere ontwikkelaar heeft een paar keer gecommit en elkaars werk succesvol gemerged.
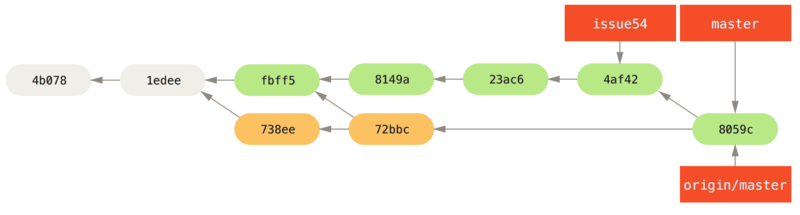
Dit is één van de eenvoudigste workflows.
Je werkt een tijdje (over het algemeen in een topic branch) en merget dit in je master-branch als het klaar is om te worden geïntegreerd.
Als je dat werk wilt delen, dan fetch merge je je eigen master-branch met de origin/master als die is gewijzigd, en als laatste push je naar de master-branch op de server.
De algemene volgorde is als volgt:
Besloten aangestuurd team
In het volgende scenario zul je kijken naar de rol van de bijdragers in een grotere besloten groep. Je zult leren hoe te werken in een omgeving waar kleine groepen samenwerken aan functies, waarna die team-gebaseerde bijdragen worden geïntegreerd door een andere partij.
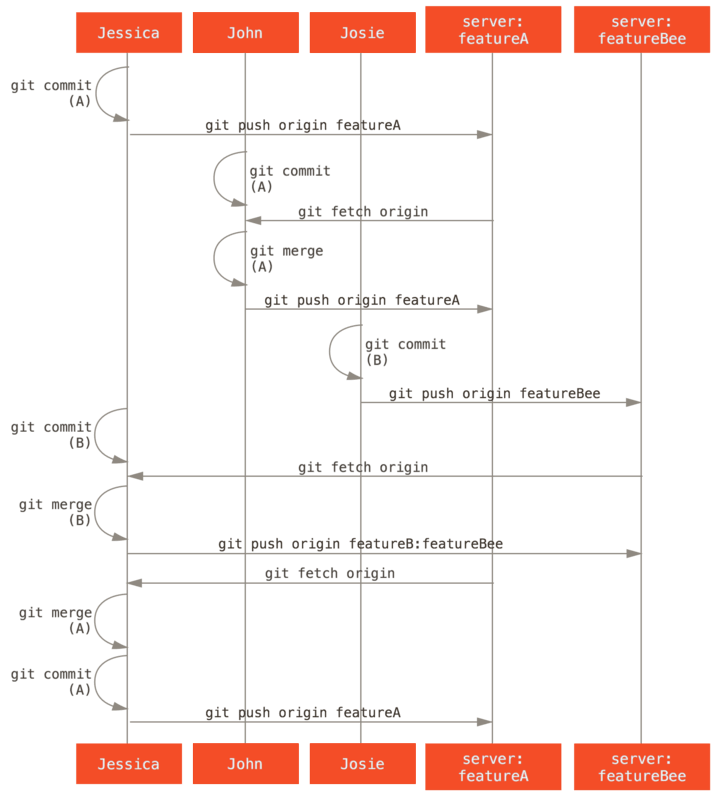
Stel dat John en Jessica samen werken aan een functie (laten we zeggen “featureA”), terwijl Jessica en een derde ontwikkelaar, Josie, aan een tweede (zeg, “featureB”) aan het werken zijn.
In dit geval gebruikt het bedrijf een integratie-manager achtige workflow, waarbij het werk van de individuele groepen alleen wordt geïntegreerd door bepaalde ontwikkelaars, en de master-branch van het hoofd repo alleen kan worden vernieuwd door die ontwikkelaars.
In dit scenario wordt al het werk gedaan in team-gebaseerde branches en later door de integrators samengevoegd.
Laten we Jessica’s workflow volgen terwijl ze aan haar twee features werkt, in parallel met twee verschillende ontwikkelaars in deze omgeving.
We nemen even aan dat ze haar repository al gekloond heeft, en dat ze besloten heeft als eerste te werken aan featureA.
Ze maakt een nieuwe branch aan voor de functie en doet daar wat werk:
# Jessica's Machine
$ git checkout -b featureA
Switched to a new branch 'featureA'
$ vim lib/simplegit.rb
$ git commit -am 'add limit to log function'
[featureA 3300904] add limit to log function
1 files changed, 1 insertions(+), 1 deletions(-)Op dit punt, moet ze haar werk delen met John, dus ze pusht haar commits naar de featureA-branch op de server.
Jessica heeft geen push toegang op de master-branch — alleen de integratoren hebben dat — dus ze moet naar een andere branch pushen om samen te kunnen werken met John:
$ git push -u origin featureA
...
To jessica@githost:simplegit.git
* [new branch] featureA -> featureAJessica mailt John om hem te zeggen dat ze wat werk gepusht heeft in een branch genaamd featureA en dat hij er nu naar kan kijken.
Terwijl ze op terugkoppeling van John wacht, besluit Jessica te beginnen met het werken aan featureB met Josie.
Om te beginnen start ze een nieuwe feature branch, gebaseerd op de master-branch van de server:
# Jessica's Machine
$ git fetch origin
$ git checkout -b featureB origin/master
Switched to a new branch 'featureB'Nu doet Jessica een paar commits op de featureB-branch:
$ vim lib/simplegit.rb
$ git commit -am 'made the ls-tree function recursive'
[featureB e5b0fdc] made the ls-tree function recursive
1 files changed, 1 insertions(+), 1 deletions(-)
$ vim lib/simplegit.rb
$ git commit -am 'add ls-files'
[featureB 8512791] add ls-files
1 files changed, 5 insertions(+), 0 deletions(-)Jessica’s repository ziet eruit als volgt:
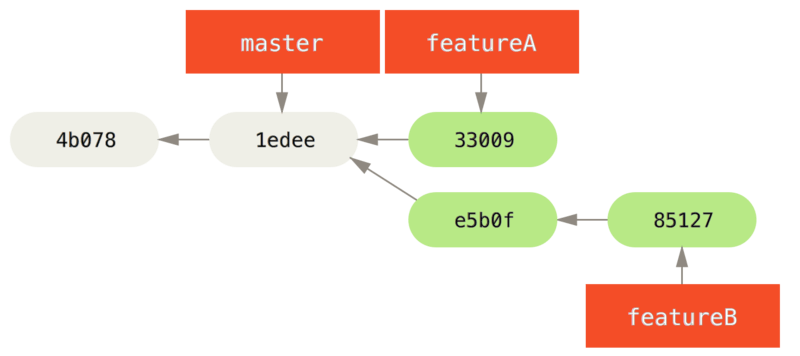
Ze is klaar om haar werk te pushen, maar ze krijgt een mail van Josie dat een branch met wat initieel werk voor featureB erin al gepusht is naar de server in de featureBee-branch.
Jessica moet die wijzigingen eerst mergen met die van haar voordat ze kan pushen naar de server.
Ze kan dan Josie’s wijzigingen ophalen met git fetch:
$ git fetch origin
...
From jessica@githost:simplegit
* [new branch] featureBee -> origin/featureBeeAangenomen dat Jessica nog op haar uitgecheckte featureB-branch zit, kan Jessica kan dit nu mergen in het werk wat zij gedaan heeft met git merge:
$ git merge origin/featureBee
Auto-merging lib/simplegit.rb
Merge made by the 'recursive' strategy.
lib/simplegit.rb | 4 ++++
1 files changed, 4 insertions(+), 0 deletions(-)Nu wil Jessica al dit gemergede “featureB” werk terug pushen naar de server, maar ze wil niet eenvoudigweg haar eigen featureB-branch pushen.
Omdat Josie al een featureBee-branch gemaakt heeft, zou Jessica op die branch willen pushen en dat doet ze met:
$ git push -u origin featureB:featureBee
...
To jessica@githost:simplegit.git
fba9af8..cd685d1 featureB -> featureBeeDit wordt een refspec genoemd.
Zie De Refspec voor een meer gedetailleerde behandeling van Git refspecs en de verschillende dingen die je daarmee kan doen.
Merk ook de -u vlag op; dit is een verkorte notatie voor -set-upstream, wat de branches voor eenvoudigere pushen en pullen op een later moment inricht.
Plotseling mailt John naar Jessica om te zeggen dat hij wat wijzigingen naar de featureA-branch waar ze op samenwerken gepusht heeft, om haar te vragen die te bekijken.
Wederom voert Jessica een eenvoudige git fetch uit om alle nieuwe wijzigingen van de server op te halen, inclusief (uiteraard) het werk van John:
$ git fetch origin
...
From jessica@githost:simplegit
3300904..aad881d featureA -> origin/featureAJessica kan de log bekijken van John’s nieuwe werk door de inhoud van de zojuist opgehaalde featureA-branch met haar lokale kopie van dezelfde branch:
$ git log featureA..origin/featureA
commit aad881d154acdaeb2b6b18ea0e827ed8a6d671e6
Author: John Smith <jsmith@example.com>
Date: Fri May 29 19:57:33 2009 -0700
changed log output to 30 from 25Als wat Jessica ziet haar bevalt, kan ze het nieuwe werk van John in haar lokale featureA-branch mergen met:
$ git checkout featureA
Switched to branch 'featureA'
$ git merge origin/featureA
Updating 3300904..aad881d
Fast forward
lib/simplegit.rb | 10 +++++++++-
1 files changed, 9 insertions(+), 1 deletions(-)Jessica kan tot slot nog wat kleine wijzigingen aanbrengen in de gemergede inhoud, dus ze het staat haar vrij om dat te doen, deze wijzigingen committen in haar lokale featureA-branch en dan het eindresultaat terug pushen op de server.
$ git commit -am 'small tweak'
[featureA 774b3ed] small tweak
1 files changed, 1 insertions(+), 1 deletions(-)
$ git push
...
To jessica@githost:simplegit.git
3300904..774b3ed featureA -> featureADe commit historie van Jessica ziet er nu zo uit:
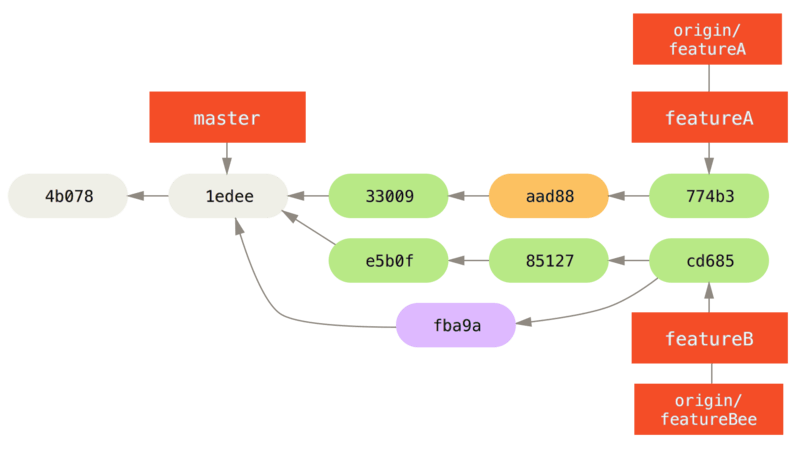
Jessica, Josie en John informeren de integrators nu dat de featureA en featureBee-branches op de server klaar zijn voor integratie in de hoofdlijn.
Nadat zij die branches in de hoofdlijn geïntegreerd hebben, zal een fetch de nieuwe merge commits ophalen, waardoor de commit historie er zo uit ziet:
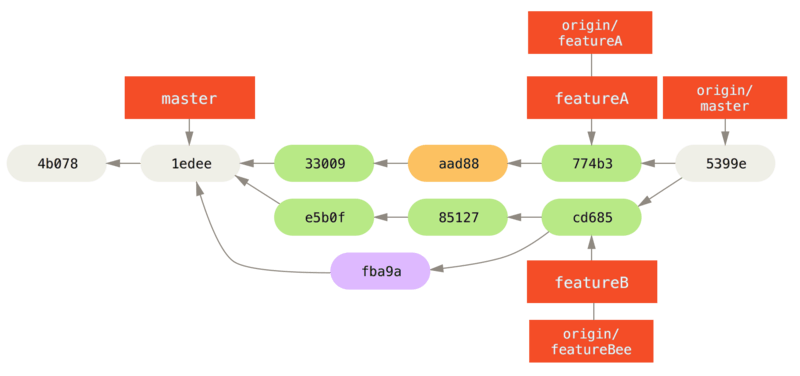
Veel groepen schakelen om naar Git juist vanwege de mogelijkheid om meerdere teams in parallel te kunnen laten werken, waarbij de verschillende lijnen van werk laat in het proces gemerged worden. De mogelijkheid van kleinere subgroepen of een team om samen te werken via remote branches zonder het hele team erin te betrekken of te hinderen is een enorm voordeel van Git. De volgorde van de workflow die je hier zag is ongeveer dit:
Gevorkt openbaar project
Het bijdragen aan openbare, of publieke, projecten gaat op een iets andere manier. Omdat je niet de toestemming hebt om de branches van het project rechtstreeks te updaten, moet je het werk op een andere manier naar de beheerders krijgen. Dit eerste voorbeeld beschrijft het bijdragen via afsplitsen (forken) op Git hosts die het eenvoudig aanmaken van forks ondersteunen. Vele hosting sites ondersteunen dit (waaronder GitHub, BitBucket, Google Code, repo.or.cz, en andere), en veel project beheerders verwachten deze manier van bijdragen. De volgende paragraaf behandelt projecten die de voorkeur hebben om bijdragen in de vorm van patches via e-mail te ontvangen.
Eerst zal je waarschijnlijk de hoofdrepository klonen, een topic branch maken voor de patch of reeks patches die je van plan bent bij te dragen, en je werk daarop doen. De te volgen stappen zien er in principe zo uit:
$ git clone <url>
$ cd project
$ git checkout -b featureA
... work ...
$ git commit
... work ...
$ git commit|
Noot
|
Je kunt eventueel besluiten |
Als je werk op de branch af is, en je klaar bent om het over te dragen aan de beheerders, ga je naar de originele project pagina en klik op de “Fork” knop.
Hiermee maak je een eigen overschrijfbare fork van het project.
Je moet de URL van deze nieuwe repository URL toevoegen als een tweede remote, en laten we deze myfork noemen:
$ git remote add myfork <url>Dan moet je je werk daar naartoe pushen.
Het is het makkelijkst om de topic branch waar je op zit te werken te pushen naar je repository, in plaats van het te mergen in je master branch en die te pushen.
De reden hiervan is, dat als het werk niet wordt geaccepteerd of alleen ge-cherry picked (deels overgenomen), je jouw master branch niet hoeft terug te draaien (de Git cherry-pick operatie wordt meer gedetailleerd behandeld in Rebasende en cherry pick workflows).
Als de beheerders je werk mergen, rebasen of cherry picken, dan krijg je het uiteindelijk toch binnen door hun repository te pullen.
Hoe dan ook, je kunt je werk pushen met:
$ git push -u myfork featureA
Als jouw werk gepusht is naar jouw fork van de repository, dan moet je de beheerder van het oorspronkelijke project inlichten dat je werk hebt dat je ze wil laten mergen.
Dit wordt een pull request (haal-binnen-verzoek) genoemd, en je kunt deze via de website genereren - GitHub heeft een eigen “Pull Request” mechanisme die we verder zullen behandelen in GitHub of je roept het git request-pull commando aan en stuurt een mail met de uitvoer handmatig naar de projectbeheerder.
Het request-pull commando neemt de basis branch waarin je de topic branch gepulld wil krijgen, en de URL van de Git repository waar je ze uit wil laten pullen, en maakt een samenvatting van alle wijzigingen die je gepulld wenst te hebben.
Bijvoorbeeld, als Jessica John een pull request wil sturen, en ze heeft twee commits gedaan op de topic branch die ze zojuist gepusht heeft, dan kan ze dit uitvoeren:
$ git request-pull origin/master myfork
The following changes since commit 1edee6b1d61823a2de3b09c160d7080b8d1b3a40:
Jessica Smith (1):
added a new function
are available in the git repository at:
git://githost/simplegit.git featureA
Jessica Smith (2):
add limit to log function
change log output to 30 from 25
lib/simplegit.rb | 10 +++++++++-
1 files changed, 9 insertions(+), 1 deletions(-)De uitvoer kan naar de beheerders gestuurd worden — het vertelt ze waar het werk vanaf gebrancht is, vat de commits samen en vertelt waar vandaan ze dit werk kunnen pullen.
Bij een project waarvan je niet de beheerder bent, is het over het algemeen eenvoudiger om een branch zoals master altijd de origin/master te laten tracken, en je werk te doen in topic branches die je eenvoudig weg kunt gooien als ze geweigerd worden.
Als je je werkthema’s gescheiden houdt in topic branches maakt dat het ook eenvoudiger voor jou om je werk te rebasen als de punt van de hoofd-repository in de tussentijd verschoven is en je commits niet langer netjes toegepast kunnen worden.
Bijvoorbeeld, als je een tweede onderwerp wilt bijdragen aan een project, ga dan niet verder werken op de topic
branch die je zojuist gepusht hebt — begin opnieuw vanaf de master-branch van de hoofd repository:
$ git checkout -b featureB origin/master
... work ...
$ git commit
$ git push myfork featureB
$ git request-pull origin/master myfork
... email generated request pull to maintainer ...
$ git fetch originNu zijn al je onderwerpen opgeslagen in een silo — vergelijkbaar met een patch reeks (queue) — die je kunt herschrijven, rebasen en wijzigen zonder dat de onderwerpen elkaar beïnvloeden of van elkaar afhankelijk, hier is hoe je het kunt doen:
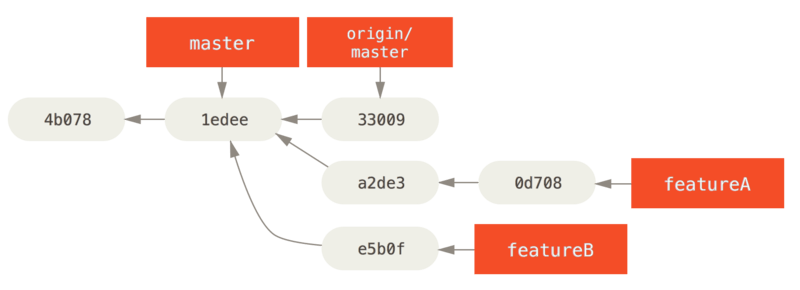
featureB.Stel dat de project-beheerder een verzameling andere patches binnengehaald heeft en jouw eerste branch geprobeerd heeft, maar dat die niet meer netjes merged.
In dat geval kun je proberen die branch te rebasen op origin/master, de conflicten op te lossen voor de beheerder, en dan je wijzigingen opnieuw aanbieden:
$ git checkout featureA
$ git rebase origin/master
$ git push -f myfork featureADit herschrijft je historie zodat die eruit ziet als in Commit historie na werk van featureA..
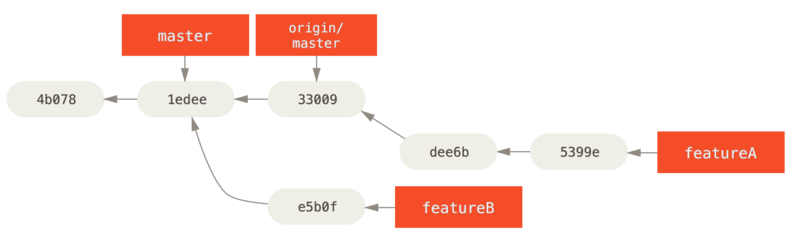
featureA.Omdat je de branch gerebased hebt, moet je de -f specificeren met je push commando om in staat te zijn de featureA-branch op de server te vervangen met een commit die er geen afstammeling van is.
Een alternatief zou zijn dit nieuwe werk naar een andere branch op de server te pushen (misschien featureAv2 genaamd).
Laten we eens kijken naar nog een mogelijk scenario: de beheerder heeft je werk bekeken in je tweede branch en vindt het concept goed, maar zou willen dat je een implementatie detail verandert.
Je gebruikt deze gelegenheid meteen om het werk te baseren op de huidige master-branch van het project.
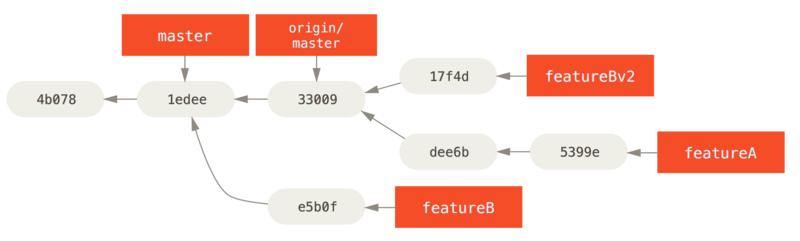
Je begint een nieuwe branch gebaseerd op de huidige origin/master-branch, squasht de featureB wijzigingen er naartoe, lost eventuele conflicten op, doet de implementatie wijziging en pusht deze terug als een nieuwe branch:
$ git checkout -b featureBv2 origin/master
$ git merge --squash featureB
... change implementation ...
$ git commit
$ git push myfork featureBv2De --squash optie pakt al het werk op de gemergde branch en perst dat samen in één wijzigingsset (changeset) die de staat van de repository geeft alsof er een echte merge zou hebben plaatsgevonden, zonder feitelijk een merge commit te doen.
Dit betekent dat je toekomstige commit maar één ouder heeft en geeft je de ruimte om alle wijzigingen te introduceren uit een andere branch en daarna meer wijzigingen te maken voordat de nieuwe commit wordt vastgelegd.
Daarnaast kan de --no-commit handig zijn door de merge commit uit te stellen in plaats van het standaard merge proces.
Je kunt de beheerder nu een bericht sturen dat je de gevraagde wijzigingen gemaakt hebt en dat ze die wijzigingen kunnen vinden in je featureBv2-branch.
featureBv2 werk.Openbaar project per e-mail
Veel projecten hebben vastgestelde procedures voor het accepteren van patches — je zult de specifieke regels voor elk project moeten controleren, ze zullen namelijk verschillen. Omdat er verscheidene oudere, grotere projecten zijn die patches accepteren via ontwikkelaar-maillijsten, zullen we nu een voorbeeld hiervan behandelen.
De workflow is vergelijkbaar met het vorige geval — je maakt topic branches voor iedere patch waar je aan werkt. Het verschil is hoe je die aanlevert bij het project. In plaats van het project te forken en naar je eigen schrijfbare versie te pushen, genereer je e-mail versies van iedere reeks commits en mailt die naar de ontwikkelaar-maillijst:
$ git checkout -b topicA
... work ...
$ git commit
... work ...
$ git commit
Nu heb je twee commits die je naar de maillijst wilt sturen.
Je gebruikt git format-patch om de mbox-geformatteerde bestanden te genereren die je kunt mailen naar de lijst.
Dit maakt van iedere commit een e-mail bericht met de eerste regel van het commit bericht als het onderwerp, en de rest van het bericht plus de patch die door de commit wordt geïntroduceerd als de inhoud.
Het prettige hieraan is dat met het toepassen van een patch uit een mail die gegenereerd is met format-patch alle commit informatie blijft behouden.
$ git format-patch -M origin/master
0001-add-limit-to-log-function.patch
0002-changed-log-output-to-30-from-25.patchHet format-patch commando drukt de namen af van de patch bestanden die het maakt.
De -M optie vertelt Git te letten op naamswijzigingen.
De bestanden komen er uiteindelijk zo uit te zien:
$ cat 0001-add-limit-to-log-function.patch
From 330090432754092d704da8e76ca5c05c198e71a8 Mon Sep 17 00:00:00 2001
From: Jessica Smith <jessica@example.com>
Date: Sun, 6 Apr 2008 10:17:23 -0700
Subject: [PATCH 1/2] add limit to log function
Limit log functionality to the first 20
---
lib/simplegit.rb | 2 +-
1 files changed, 1 insertions(+), 1 deletions(-)
diff --git a/lib/simplegit.rb b/lib/simplegit.rb
index 76f47bc..f9815f1 100644
--- a/lib/simplegit.rb
+++ b/lib/simplegit.rb
@@ -14,7 +14,7 @@ class SimpleGit
end
def log(treeish = 'master')
- command("git log #{treeish}")
+ command("git log -n 20 #{treeish}")
end
def ls_tree(treeish = 'master')
--
2.1.0Je kunt deze patch bestanden ook aanpassen om meer informatie, die je niet in het commit bericht wilt laten verschijnen, voor de maillijst toe te voegen.
Als je tekst toevoegt tussen de --- regel en het begin van de patch (de diff --git regel), dan kunnen ontwikkelaars dit lezen, maar tijdens het toepassen van de patch wordt dit genegeerd.
Om dit te mailen naar een maillijst, kan je het bestand in je mail-applicatie plakken of het sturen via een commandoregel programma.
Het plakken van de tekst veroorzaakt vaak formaterings problemen, in het bijzonder bij “slimmere” clients die de newlines en andere witruimte niet juist behouden.
Gelukkig levert Git een gereedschap die je helpt om juist geformatteerde patches via IMAP te versturen, wat het alweer een stuk makkelijker voor je kan maken.
We zullen je laten zien hoe je een patch via Gmail stuurt, wat de mail-applicatie is waar we het meest bekend mee zijn.
Je kunt gedetailleerde instructies voor een aantal mail programma’s vinden aan het eind van het eerder genoemde Documentation/SubmittingPatches bestand in de Git broncode.
Eerst moet je de imap sectie in je ~/.gitconfig bestand instellen.
Je kunt iedere waarde apart instellen met een serie git config commando’s, of je kunt ze handmatig toevoegen, maar uiteindelijk moet je config bestand er ongeveer zo uitzien:
[imap]
folder = "[Gmail]/Drafts"
host = imaps://imap.gmail.com
user = user@gmail.com
pass = YX]8g76G_2^sFbd
port = 993
sslverify = falseAls je IMAP server geen SSL gebruikt, zijn de laatste twee regels waarschijnlijk niet nodig, en de waarde voor host zal imap:// zijn in plaats van imaps://.
Als dat ingesteld is, kun je git imap-send gebruiken om de patch reeks in de Drafts map van de gespecificeerde IMAP server te zetten:
$ cat *.patch |git imap-send
Resolving imap.gmail.com... ok
Connecting to [74.125.142.109]:993... ok
Logging in...
sending 2 messages
100% (2/2) doneNu zou je in staat moeten zijn om naar je Drafts folder te gaan, het To veld te veranderen in het adres van de mail lijst waar je de patch naar toe stuurt, en mogelijk de onderhouder of de persoon verantwoordelijk voor dat deel te CC-en, en het te versturen.
Je kunt de patches ook via een SMTP server sturen.
Net als hierboven, kan je elke waarde apart zetten met een reeks van git config commando’s, of je kunt ze handmatig in de sendemail sectie in je ~/.gitconfig bestand toevoegen:
[sendemail]
smtpencryption = tls
smtpserver = smtp.gmail.com
smtpuser = user@gmail.com
smtpserverport = 587Als dit gedaan is, kan je git send-email gebruiken om je patches te sturen:
$ git send-email *.patch
0001-added-limit-to-log-function.patch
0002-changed-log-output-to-30-from-25.patch
Who should the emails appear to be from? [Jessica Smith <jessica@example.com>]
Emails will be sent from: Jessica Smith <jessica@example.com>
Who should the emails be sent to? jessica@example.com
Message-ID to be used as In-Reply-To for the first email? yDan zal Git een berg log-informatie oplepelen die er ongeveer zo uitziet voor elke patch die je aan het versturen bent:
(mbox) Adding cc: Jessica Smith <jessica@example.com> from
\line 'From: Jessica Smith <jessica@example.com>'
OK. Log says:
Sendmail: /usr/sbin/sendmail -i jessica@example.com
From: Jessica Smith <jessica@example.com>
To: jessica@example.com
Subject: [PATCH 1/2] added limit to log function
Date: Sat, 30 May 2009 13:29:15 -0700
Message-Id: <1243715356-61726-1-git-send-email-jessica@example.com>
X-Mailer: git-send-email 1.6.2.rc1.20.g8c5b.dirty
In-Reply-To: <y>
References: <y>
Result: OKSamenvatting
In dit hoofdstuk is een aantal veel voorkomende workflows behandeld, die je kunt gebruiken om te kunnen werken in een aantal zeer verschillende typen Git projecten die je kunt tegenkomen. En er zijn een aantal nieuwe gereedschappen geïntroduceerd die je helpen om dit proces te beheren. Wat hierna volgt zal je laten zien hoe je aan de andere kant van de tafel werkt: een Git project beheren. Je zult leren hoe een welwillende dictator of integratie manager te zijn.