
-
1. 使い始める
- 1.1 バージョン管理に関して
- 1.2 Git略史
- 1.3 Gitの基本
- 1.4 コマンドライン
- 1.5 Gitのインストール
- 1.6 最初のGitの構成
- 1.7 ヘルプを見る
- 1.8 まとめ
-
2. Git の基本
- 2.1 Git リポジトリの取得
- 2.2 変更内容のリポジトリへの記録
- 2.3 コミット履歴の閲覧
- 2.4 作業のやり直し
- 2.5 リモートでの作業
- 2.6 タグ
- 2.7 Git エイリアス
- 2.8 まとめ
-
3. Git のブランチ機能
- 3.1 ブランチとは
- 3.2 ブランチとマージの基本
- 3.3 ブランチの管理
- 3.4 ブランチでの作業の流れ
- 3.5 リモートブランチ
- 3.6 リベース
- 3.7 まとめ
-
4. Gitサーバー
- 4.1 プロトコル
- 4.2 サーバー用の Git の取得
- 4.3 SSH 公開鍵の作成
- 4.4 サーバーのセットアップ
- 4.5 Git デーモン
- 4.6 Smart HTTP
- 4.7 GitWeb
- 4.8 GitLab
- 4.9 サードパーティによる Git ホスティング
- 4.10 まとめ
-
5. Git での分散作業
- 5.1 分散作業の流れ
- 5.2 プロジェクトへの貢献
- 5.3 プロジェクトの運営
- 5.4 まとめ
-
6. GitHub
- 6.1 アカウントの準備と設定
- 6.2 プロジェクトへの貢献
- 6.3 プロジェクトのメンテナンス
- 6.4 組織の管理
- 6.5 スクリプトによる GitHub の操作
- 6.6 まとめ
-
7. Git のさまざまなツール
- 7.1 リビジョンの選択
- 7.2 対話的なステージング
- 7.3 作業の隠しかたと消しかた
- 7.4 作業内容への署名
- 7.5 検索
- 7.6 歴史の書き換え
- 7.7 リセットコマンド詳説
- 7.8 高度なマージ手法
- 7.9 Rerere
- 7.10 Git によるデバッグ
- 7.11 サブモジュール
- 7.12 バンドルファイルの作成
- 7.13 Git オブジェクトの置き換え
- 7.14 認証情報の保存
- 7.15 まとめ
-
8. Git のカスタマイズ
- 8.1 Git の設定
- 8.2 Git の属性
- 8.3 Git フック
- 8.4 Git ポリシーの実施例
- 8.5 まとめ
-
9. Gitとその他のシステムの連携
- 9.1 Git をクライアントとして使用する
- 9.2 Git へ移行する
- 9.3 まとめ
-
10. Gitの内側
- 10.1 配管(Plumbing)と磁器(Porcelain)
- 10.2 Gitオブジェクト
- 10.3 Gitの参照
- 10.4 Packfile
- 10.5 Refspec
- 10.6 転送プロトコル
- 10.7 メンテナンスとデータリカバリ
- 10.8 環境変数
- 10.9 まとめ
-
A1. 付録 A: その他の環境でのGit
- A1.1 グラフィカルインタフェース
- A1.2 Visual StudioでGitを使う
- A1.3 EclipseでGitを使う
- A1.4 BashでGitを使う
- A1.5 ZshでGitを使う
- A1.6 PowershellでGitを使う
- A1.7 まとめ
-
A2. 付録 B: Gitをあなたのアプリケーションに組み込む
- A2.1 Gitのコマンドラインツールを使う方法
- A2.2 Libgit2を使う方法
- A2.3 JGit
-
A3. 付録 C: Gitのコマンド
- A3.1 セットアップと設定
- A3.2 プロジェクトの取得と作成
- A3.3 基本的なスナップショット
- A3.4 ブランチとマージ
- A3.5 プロジェクトの共有とアップデート
- A3.6 検査と比較
- A3.7 デバッグ
- A3.8 パッチの適用
- A3.9 メール
- A3.10 外部システム
- A3.11 システム管理
- A3.12 配管コマンド
10.2 Gitの内側 - Gitオブジェクト
Gitオブジェクト
Git は内容アドレスファイルシステムです。
素晴らしい。
…で、それはどういう意味なのでしょう?
それは、Gitのコアの部分はシンプルなキー・バリュー型データストアである、という意味です。
ここにはどんな種類のコンテンツでも格納でき、それに対応するキーが返されます。キーを使えば格納したコンテンツをいつでも取り出せます。
これは hash-object という配管コマンドを使えば実際に確認できます。このコマンドはデータを受け取り、それを .git ディレクトリに格納し、そのデータを格納しているキーを返します。
まずは、新しいGitリポジトリを初期化し、 objects ディレクトリ配下に何もないことを確認してみましょう。
$ git init test
Initialized empty Git repository in /tmp/test/.git/
$ cd test
$ find .git/objects
.git/objects
.git/objects/info
.git/objects/pack
$ find .git/objects -type fGitは objects ディレクトリを初期化して、その中に pack と info というサブディレクトリを作ります。しかし、ファイルはひとつも作られません。
今からGitデータベースにテキストを幾つか格納してみます。
$ echo 'test content' | git hash-object -w --stdin
d670460b4b4aece5915caf5c68d12f560a9fe3e4-w オプションは、 hash-object にオブジェクトを格納するよう指示しています。-w オプションを付けない場合、コマンドはただオブジェクトのキーとなる文字列を返します。
--stdin オプションは、標準入力からコンテンツを読み込むよう指示しています。これを指定しない場合、hash-object はコマンドラインオプションの最後にファイルパスが指定されることを期待して動作します。
コマンドを実行すると、40文字から成るチェックサムのハッシュ値が出力されます。
これは、SHA-1ハッシュです。すぐ後で説明しますが、これは格納するコンテンツにヘッダーを加えたデータに対するチェックサムです。
これで、Gitがデータをどのようにして格納するか見ることができるようになりました。
$ find .git/objects -type f
.git/objects/d6/70460b4b4aece5915caf5c68d12f560a9fe3e4objects ディレクトリの中にファイルがひとつあります。
Gitはまずこのようにしてコンテンツを格納します。コンテンツ1つごとに1ファイルで、ファイル名はコンテンツとそのヘッダーに対するSHA-1チェックサムで決まります。
SHA-1ハッシュのはじめの2文字がサブディレクトリの名前になり、残りの38文字がファイル名になります。
cat-file コマンドを使うと、コンテンツをGitから取り出すことができます。
このコマンドは、Gitオブジェクトを調べるための万能ナイフのようなものです。
-p オプションを付けると、cat-file コマンドはコンテンツのタイプを判別し、わかりやすく表示してくれます。
$ git cat-file -p d670460b4b4aece5915caf5c68d12f560a9fe3e4
test contentこれで、Gitにコンテンツを追加したり、取り出したりできるようになりました。 ファイルの内容に対しても、これと同様のことを行えます。 例えば、あるファイルに対して簡単なバージョン管理を行うことができます。 まず、新規にファイルを作成し、データベースにその内容を保存します。
$ echo 'version 1' > test.txt
$ git hash-object -w test.txt
83baae61804e65cc73a7201a7252750c76066a30それから、新しい内容をそのファイルに書き込んで、再び保存します。
$ echo 'version 2' > test.txt
$ git hash-object -w test.txt
1f7a7a472abf3dd9643fd615f6da379c4acb3e3aデータベースには、最初に格納したコンテンツに加えて、上記のファイルのバージョン2つが新規に追加されています。
$ find .git/objects -type f
.git/objects/1f/7a7a472abf3dd9643fd615f6da379c4acb3e3a
.git/objects/83/baae61804e65cc73a7201a7252750c76066a30
.git/objects/d6/70460b4b4aece5915caf5c68d12f560a9fe3e4これで、上記のファイルの変更を取り消して最初のバージョンに戻せるようになりました。
$ git cat-file -p 83baae61804e65cc73a7201a7252750c76066a30 > test.txt
$ cat test.txt
version 1また、2つ目のバージョンにもできます。
$ git cat-file -p 1f7a7a472abf3dd9643fd615f6da379c4acb3e3a > test.txt
$ cat test.txt
version 2しかし、それぞれのファイルのバージョンのSHA-1キーを覚えておくのは実用的ではありません。加えて、システムにはファイル名は格納されておらず、ファイルの内容のみが格納されています。
このオブジェクトタイプはブロブ(blob)と呼ばれます。
cat-file -t コマンドに SHA-1キーを渡すことで、あなたは Git 内にあるあらゆるオブジェクトのタイプを問い合わせることができます。
$ git cat-file -t 1f7a7a472abf3dd9643fd615f6da379c4acb3e3a
blobツリーオブジェクト
次のタイプはツリーです。これにより、ファイル名の格納の問題を解決して、さらに、複数のファイルをまとめて格納できるようになります。 Git がコンテンツを格納する方法は、UNIXのファイルシステムに似ていますが少し簡略化されています。 すべてのコンテンツはツリーオブジェクトまたはブロブオブジェクトとして格納されます。ツリーは UNIXのディレクトリエントリーと対応しており、ブロブはiノードやファイルコンテンツとほぼ対応しています。 1つのツリーオブジェクトには1つ以上のツリーエントリーが含まれています。このツリーエントリーには、ブロブか、サブツリーとそれに関連するモード、タイプ、ファイル名へのSHA-1ポインターが含まれています。 例えば、あるプロジェクトの最新のツリーはこのように見えるかもしれません。
$ git cat-file -p master^{tree}
100644 blob a906cb2a4a904a152e80877d4088654daad0c859 README
100644 blob 8f94139338f9404f26296befa88755fc2598c289 Rakefile
040000 tree 99f1a6d12cb4b6f19c8655fca46c3ecf317074e0 libmaster^{tree} のシンタックスは、master ブランチ上での最後のコミットが指しているツリーオブジェクトを示します。
lib サブディレクトリはブロブではなく、別のツリーへのポインタであることに注意してください。
$ git cat-file -p 99f1a6d12cb4b6f19c8655fca46c3ecf317074e0
100644 blob 47c6340d6459e05787f644c2447d2595f5d3a54b simplegit.rb概念的には、Gitが格納するデータは次のようなものです。
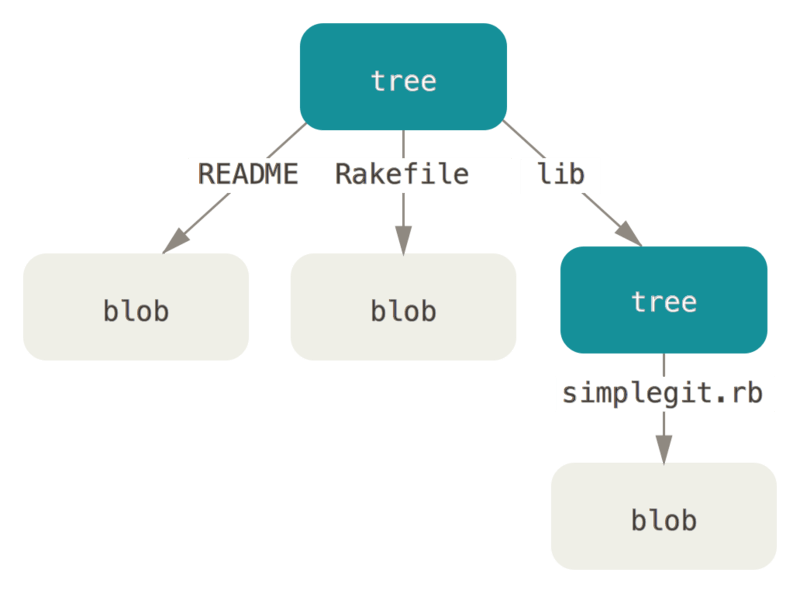
自前でツリーを作るのも非常に簡単です。
Gitは通常、ステージングエリアやインデックスの状態を取得してツリーを作成し、そのツリーをもとに一連のツリーオブジェクトを書き込みます。
そのため、ツリーオブジェクトを作るには、まずファイルをステージングしてインデックスを作成しなければなりません。
単一のエントリー – ここでは test.txt ファイルの最初のバージョン – からインデックスを作るには、update-index という配管コマンドを使います。
このコマンドは、前のバージョンの test.txt ファイルをあえて新しいステージングエリアに追加する際に使用します。
ファイルはまだステージングエリアには存在しない(まだステージングエリアをセットアップさえしていない)ので、--add オプションを付けなければなりません。
また、追加しようとしているファイルはディレクトリには無くデータベースにあるので、--cacheinfo オプションを付ける必要があります。
その次に、モード、SHA-1、ファイル名を指定します。
$ git update-index --add --cacheinfo 100644 \
83baae61804e65cc73a7201a7252750c76066a30 test.txtこの例では、100644 のモードを指定しています。これは、それが通常のファイルであることを意味します。
他に指定できるモードとしては、実行可能ファイルであることを意味する 100755 や、シンボリックリンクであることを示す 120000 があります。
このモードは通常の UNIX モードから取り入れた概念ですが、それほどの柔軟性はありません。Git中のファイル(ブロブ)に対しては、上記3つのモードのみが有効です(ディレクトリとサブモジュールに対しては他のモードも使用できます)。
これで、 write-tree コマンドを使って、ステージングエリアをツリーオブジェクトに書き出せるようになりました。
-w オプションは不要です。write-tree コマンドを呼ぶと、ツリーがまだ存在しない場合には、インデックスの状態をもとに自動的にツリーオブジェクトが作られます。
$ git write-tree
d8329fc1cc938780ffdd9f94e0d364e0ea74f579
$ git cat-file -p d8329fc1cc938780ffdd9f94e0d364e0ea74f579
100644 blob 83baae61804e65cc73a7201a7252750c76066a30 test.txtまた、これがツリーオブジェクトであることを検証できるようになりました。
$ git cat-file -t d8329fc1cc938780ffdd9f94e0d364e0ea74f579
tree今度は、2つめのバージョンの test.txt と、新規作成したファイルから、新しくツリーを作ります。
$ echo 'new file' > new.txt
$ git update-index test.txt
$ git update-index --add new.txtこれでステージングエリアには、 new.txt という新しいファイルに加えて、新しいバージョンの test.txt も登録されました。
このツリーを書き出して(ステージングエリアまたはインデックスの状態をツリーオブジェクトとして記録して)、どのようになったか見てみましょう。
$ git write-tree
0155eb4229851634a0f03eb265b69f5a2d56f341
$ git cat-file -p 0155eb4229851634a0f03eb265b69f5a2d56f341
100644 blob fa49b077972391ad58037050f2a75f74e3671e92 new.txt
100644 blob 1f7a7a472abf3dd9643fd615f6da379c4acb3e3a test.txtこのツリーに両方のファイルエントリがあること、また、test.txt のSHA-1が先ほどの "version 2" のSHA-1( 1f7a7a )であることに注意してください。
ちょっと試しに、最初のツリーをサブディレクトリとしてこの中に追加してみましょう。
read-tree を呼ぶことで、ステージングエリアの中にツリーを読み込むことができます。
このケースでは、--prefix オプションを付けて read-tree コマンドを使用することで、ステージングエリアの中に、既存のツリーをサブツリーとして読み込むことができます。
$ git read-tree --prefix=bak d8329fc1cc938780ffdd9f94e0d364e0ea74f579
$ git write-tree
3c4e9cd789d88d8d89c1073707c3585e41b0e614
$ git cat-file -p 3c4e9cd789d88d8d89c1073707c3585e41b0e614
040000 tree d8329fc1cc938780ffdd9f94e0d364e0ea74f579 bak
100644 blob fa49b077972391ad58037050f2a75f74e3671e92 new.txt
100644 blob 1f7a7a472abf3dd9643fd615f6da379c4acb3e3a test.txt先ほど書き込んだ新しいツリーから作業ディレクトリを作っていれば、作業ディレクトリの直下にファイルが2つと、最初のバージョンの test.txt ファイルが含まれている bak という名前のサブディレクトリが入ります。
このような構成に対し、Gitが格納するデータのイメージは次のようになります。
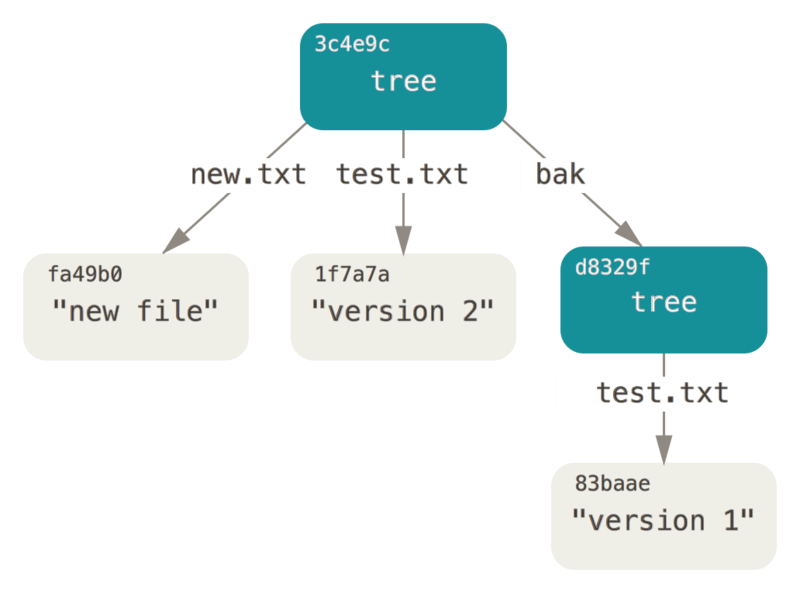
コミットオブジェクト
追跡したいプロジェクトに対し、それぞれ異なる内容のスナップショットを示すツリー3つができました。ですが、各スナップショットを呼び戻すには3つのSHA-1の値すべてを覚えておかなければならない、という以前からの問題は残ったままです。 さらに、そのスナップショットを誰が、いつ、どのような理由で保存したのかについての情報が一切ありません。 これはコミットオブジェクトに保存される基本的な情報です。
コミットオブジェクトを作成するには、ツリーのSHA-1を1つと、もしそれの直前に来るコミットオブジェクトがあれば、それらを指定して commit-tree を呼びます。
最初に書き込んだツリーから始めましょう。
$ echo 'first commit' | git commit-tree d8329f
fdf4fc3344e67ab068f836878b6c4951e3b15f3dこれで、cat-file コマンドを使って、新しいコミットオブジェクトを見られるようになりました。
$ git cat-file -p fdf4fc3
tree d8329fc1cc938780ffdd9f94e0d364e0ea74f579
author Scott Chacon <schacon@gmail.com> 1243040974 -0700
committer Scott Chacon <schacon@gmail.com> 1243040974 -0700
first commitコミットオブジェクトの形式はシンプルです。その内容は、コミットが作成された時点のスナップショットのトップレベルのツリー、作者とコミッターの情報(user.name および user.email の設定と現在のタイムスタンプを使用します)、空行、そしてコミットメッセージとなっています。
次に、コミットオブジェクトを新たに2つ書き込みます。各コミットオブジェクトはその直前のコミットを参照しています。
$ echo 'second commit' | git commit-tree 0155eb -p fdf4fc3
cac0cab538b970a37ea1e769cbbde608743bc96d
$ echo 'third commit' | git commit-tree 3c4e9c -p cac0cab
1a410efbd13591db07496601ebc7a059dd55cfe93つのコミットオブジェクトは、それぞれ、これまでに作成した3つのスナップショットのツリーのひとつを指しています。
奇妙なことに、これで本物のGitヒストリーができており、git log コマンドによってログを表示できます。最後のコミットのSHA-1ハッシュを指定して実行すると……
$ git log --stat 1a410e
commit 1a410efbd13591db07496601ebc7a059dd55cfe9
Author: Scott Chacon <schacon@gmail.com>
Date: Fri May 22 18:15:24 2009 -0700
third commit
bak/test.txt | 1 +
1 file changed, 1 insertion(+)
commit cac0cab538b970a37ea1e769cbbde608743bc96d
Author: Scott Chacon <schacon@gmail.com>
Date: Fri May 22 18:14:29 2009 -0700
second commit
new.txt | 1 +
test.txt | 2 +-
2 files changed, 2 insertions(+), 1 deletion(-)
commit fdf4fc3344e67ab068f836878b6c4951e3b15f3d
Author: Scott Chacon <schacon@gmail.com>
Date: Fri May 22 18:09:34 2009 -0700
first commit
test.txt | 1 +
1 file changed, 1 insertion(+)素晴らしい。
フロントエンドのコマンドを利用せずに、低レベルのオペレーションだけでGitの歴史を作り上げたのです。
これは、本質的に git add コマンドと git commit コマンドを実行するときにGitが行っていることと同じです。変更されたファイルに対応するブロブを格納し、インデックスを更新し、ツリーを書き出し、トップレベルのツリーと、その直前のコミットを参照するコミットオブジェクトとを書き出しています。
これらの3つの主要な Git オブジェクト – ブロブとツリーとコミット – は、まずは個別のファイルとして .git/object ディレクトリに格納されます。
現在、サンプルのディレクトリにあるすべてのオブジェクトを以下に示します。コメントは、それぞれ何を格納しているのかを示します。
$ find .git/objects -type f
.git/objects/01/55eb4229851634a0f03eb265b69f5a2d56f341 # tree 2
.git/objects/1a/410efbd13591db07496601ebc7a059dd55cfe9 # commit 3
.git/objects/1f/7a7a472abf3dd9643fd615f6da379c4acb3e3a # test.txt v2
.git/objects/3c/4e9cd789d88d8d89c1073707c3585e41b0e614 # tree 3
.git/objects/83/baae61804e65cc73a7201a7252750c76066a30 # test.txt v1
.git/objects/ca/c0cab538b970a37ea1e769cbbde608743bc96d # commit 2
.git/objects/d6/70460b4b4aece5915caf5c68d12f560a9fe3e4 # 'test content'
.git/objects/d8/329fc1cc938780ffdd9f94e0d364e0ea74f579 # tree 1
.git/objects/fa/49b077972391ad58037050f2a75f74e3671e92 # new.txt
.git/objects/fd/f4fc3344e67ab068f836878b6c4951e3b15f3d # commit 1すべての内部のポインタを辿ってゆけば、次のようなオブジェクトグラフが得られます。
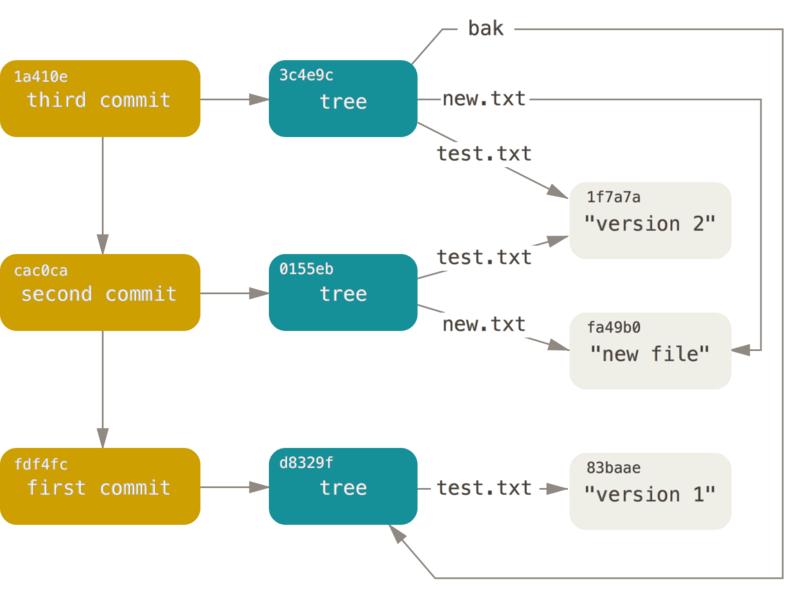
オブジェクトストレージ
ヘッダはコンテンツと一緒に格納されることを、以前に述べました。 ここでは少し時間を割いて、Gitがどのようにオブジェクトを格納するのかを見ていきましょう。 以降では、ブロブオブジェクト – ここでは “what is up, doc?” という文字列 – をRuby言語を使って対話的に格納する方法を説明します。
irb コマンドで、対話モードでRubyを起動します。
$ irb
>> content = "what is up, doc?"
=> "what is up, doc?"Gitがヘッダを構築する際には、まず初めにオブジェクトのタイプを表す文字列が来ます。この場合はblobです。 次に、スペースに続いてコンテンツのサイズ、最後にヌルバイトが追加されます。
>> header = "blob #{content.length}\0"
=> "blob 16\u0000"Gitはこのヘッダと元々のコンテンツとを結合して、その新しいコンテンツのSHA-1チェックサムを計算します。
Rubyでは、文字列のSHA-1のハッシュ値は、require を使用してSHA1ダイジェストライブラリをインクルードし、文字列を引数にして Digest::SHA1.hexdigest() 関数を呼ぶことで求められます。
>> store = header + content
=> "blob 16\u0000what is up, doc?"
>> require 'digest/sha1'
=> true
>> sha1 = Digest::SHA1.hexdigest(store)
=> "bd9dbf5aae1a3862dd1526723246b20206e5fc37"Gitはzlibを用いてこの新しいコンテンツを圧縮します。Rubyではzlibライブラリをインクルードすれば同じことが行えます。
まず、requireを使用してzlibライブラリをインクルードし、コンテンツに対して Zlib::Deflate.deflate() を実行します。
>> require 'zlib'
=> true
>> zlib_content = Zlib::Deflate.deflate(store)
=> "x\x9CK\xCA\xC9OR04c(\xCFH,Q\xC8,V(-\xD0QH\xC9O\xB6\a\x00_\x1C\a\x9D"最後に、zlibでdeflate圧縮されたコンテンツをディスク上のオブジェクトに書き込みます。
まず、オブジェクトを書き出す先のパスを決定します(SHA-1ハッシュ値の最初の2文字はサブディレクトリの名前で、残りの38文字はそのディレクトリ内のファイル名になります)。
Rubyでは、サブディレクトリが存在しない場合、 FileUtils.mkdir_p() 関数で作成できます。
そして、File.open() によってファイルを開いて、前にzlibで圧縮したコンテンツをファイルに書き出します。ファイルへの書き出しは、開いたファイルのハンドルに対して write() を呼ぶことで行います。
>> path = '.git/objects/' + sha1[0,2] + '/' + sha1[2,38]
=> ".git/objects/bd/9dbf5aae1a3862dd1526723246b20206e5fc37"
>> require 'fileutils'
=> true
>> FileUtils.mkdir_p(File.dirname(path))
=> ".git/objects/bd"
>> File.open(path, 'w') { |f| f.write zlib_content }
=> 32これだけです。これで、正当なGitブロブオブジェクトが出来上がりました。 Gitオブジェクトはすべて同じ方法で格納されますが、オブジェクトのタイプだけは様々で、ヘッダーが blobという文字列ではなく、commitやtreeという文字列で始まることもあります。 また、オブジェクトタイプがブロブの場合、コンテンツはほぼ何でもよいですが、コミットとツリーの場合、コンテンツは非常に厳密に形式が定められています。