
-
1. شروع به کار (getting started)
-
2. مقدمات گیت (git basics chapter)
- 2.1 گرفتن یک مخزن گیت (Getting a Git Repository)
- 2.2 ثبت تغییرات در مخزن (Recording Changes to the Repository)
- 2.3 مشاهده تاریخچه کامیتها (Viewing the Commit History)
- 2.4 بازگرداندن تغییرات (Undoing Things)
- 2.5 کار کردن با ریموت ها (Working with Remotes)
- 2.6 تگ کردن (Tagging)
- 2.7 نام مستعار گیت (Git Aliases)
- 2.8 خلاصه (summary)
-
3. انشعابگیری در گیت (Git Branching)
-
4. گیت روی سرور (Git on the server)
- 4.1 پروتکلها (The Protocols)
- 4.2 راهاندازی گیت روی یک سرور (Getting Git on a Server)
- 4.3 ایجاد کلید عمومی SSH شما (Generating Your SSH Public Key)
- 4.4 نصب و راهاندازی سرور (Setting up server)
- 4.5 سرویسدهنده گیت (Git Daemon)
- 4.6 HTTP هوشمند (Smart HTTP)
- 4.7 گیتوب (GitWeb)
- 4.8 گیتلب (GitLab)
- 4.9 گزینههای میزبانی شخص ثالث (Third Party Hosted Options)
- 4.10 خلاصه (Summary)
-
5. گیت توزیعشده (Distributed git)
-
6. GitHub (گیت هاب)
-
7. ابزارهای گیت (Git Tools)
- 7.1 انتخاب بازبینی (Revision Selection)
- 7.2 مرحلهبندی تعاملی (Interactive Staging)
- 7.3 ذخیره موقت و پاکسازی (Stashing and Cleaning)
- 7.4 Signing Your Work (امضای کارهای شما)
- 7.5 جستجو (Searching)
- 7.6 بازنویسی تاریخچه (Rewriting History)
- 7.7 بازنشانی به زبان ساده (Reset Demystified)
- 7.8 ادغام پیشرفته (Advanced Merging)
- 7.9 بازاستفاده خودکار از حل تضادها (Rerere)
- 7.10 اشکالزدایی با گیت (Debugging with Git)
- 7.11 سابماژول ها (Submodules)
- 7.12 بستهبندی (Bundling)
- 7.13 جایگزینی (Replace)
- 7.14 ذخیرهسازی اطلاعات ورود (Credential Storage)
- 7.15 خلاصه (Summary)
-
8. سفارشیسازی Git (Customizing Git)
-
9. گیت و سیستمهای دیگر (Git and Other Systems)
-
10. (Git Internals)
- 10.1 ابزارها و دستورات سطح پایین (Plumbing and Porcelain)
- 10.2 اشیا گیت (Git Objects)
- 10.3 مراجع گیت (Git References)
- 10.4 فایلهای بسته (Packfiles)
- 10.5 نگاشت (The Refspec)
- 10.6 پروتکلهای انتقال (Transfer Protocols)
- 10.7 نگهداری و بازیابی دادهها (Maintenance and Data Recovery)
- 10.8 متغیرهای محیطی (Environment Variables)
- 10.9 (Summary)
-
A1. پیوست A: گیت در محیطهای دیگر (Git in Other Environments)
- A1.1 رابط های گرافیکی (Graphical Interfaces)
- A1.2 Git در ویژوال استودیو (Git in Visual Studio)
- A1.3 Git در Visual Studio Code (Git in Visual Studio Code)
- A1.4 Git در IntelliJ / PyCharm / WebStorm / PhpStorm / RubyMine (Git in IntelliJ / PyCharm / WebStorm / PhpStorm / RubyMine)
- A1.5 Git در Sublime Text (Git in Sublime Text)
- A1.6 گیت در بش (Git in Bash)
- A1.7 Git در Zsh (Git in Zsh)
- A1.8 Git در PowerShell (Git in PowerShell)
- A1.9 خلاصه (Summary)
-
A2. پیوست B: گنجاندن گیت در برنامههای شما (Embedding Git in your Applications)
-
A3. پیوست C: دستورات گیت (Git Commands)
- A3.1 تنظیم و پیکربندی (Setup and Config)
- A3.2 گرفتن و ایجاد پروژهها (Getting and Creating Projects)
- A3.3 نمونهبرداری پایهای (Basic Snapshotting)
- A3.4 انشعابگیری و ادغام (Branching and Merging)
- A3.5 بهاشتراکگذاری و بهروزرسانی پروژهها (Sharing and Updating Projects)
- A3.6 بازرسی و مقایسه (Inspection and Comparison)
- A3.7 عیبیابی (Debugging)
- A3.8 اعمال تغییرات به صورت پچ (Patching)
- A3.9 ایمیل (Email)
- A3.10 سیستمهای خارجی (External Systems)
- A3.11 مدیریت (Administration)
- A3.12 دستورات سطح پایین گیت (Plumbing Commands)
10.2 (Git Internals) - اشیا گیت (Git Objects)
اشیا گیت (Git Objects)
Git یک content-addressable filesystem است. خیلی خوب. این یعنی چی؟ یعنی در هستهی Git یک key-value data store ساده قرار دارد. به این معنا که شما میتوانید هر نوع محتوایی را داخل یک Git repository وارد کنید و Git یک کلید یکتا به شما برمیگرداند که بعداً میتوانید با آن کلید، محتوای خود را بازیابی کنید.
بهعنوان یک نمایش عملی، بیایید به دستور plumbing به نام git hash-object نگاه کنیم؛ این دستور دادهای را دریافت میکند، آن را داخل دایرکتوری .git/objects (یعنی object database) ذخیره میکند، و کلید یکتایی به شما برمیگرداند که به آن object اشاره دارد.
ابتدا یک Git repository جدید initialize کنید و مطمئن شوید که (قابل پیشبینی است) چیزی در دایرکتوری objects وجود ندارد:
$ git init test
Initialized empty Git repository in /tmp/test/.git/
$ cd test
$ find .git/objects
.git/objects
.git/objects/info
.git/objects/pack
$ find .git/objects -type fGit دایرکتوری objects را ساخته و زیرشاخههای pack و info را ایجاد کرده، اما هیچ فایل عادی وجود ندارد.
حالا بیایید با git hash-object یک data object جدید بسازیم و آن را بهصورت دستی در Git database ذخیره کنیم:
$ echo 'test content' | git hash-object -w --stdin
d670460b4b4aece5915caf5c68d12f560a9fe3e4در سادهترین حالت، git hash-object محتوایی که به آن میدهید را میگیرد و صرفاً کلید یکتایی برمیگرداند که میتواند برای ذخیرهی آن محتوا در Git database استفاده شود.
گزینه -w به دستور میگوید که فقط کلید را برنگرداند، بلکه object را واقعاً در database بنویسد.
گزینه --stdin هم به git hash-object میگوید که محتوا را از stdin دریافت کند؛ در غیر این صورت، دستور انتظار دارد نام فایلی در انتهای دستور داده شود که شامل محتوای مورد استفاده است.
خروجی دستور بالا یک hash ۴۰ کاراکتری است. این همان SHA-1 hash است – یک checksum از محتوایی که ذخیره کردهاید بهعلاوهی یک header (که کمی بعد یاد میگیرید). حالا میتوانید ببینید Git چطور دادههای شما را ذخیره کرده است:
$ find .git/objects -type f
.git/objects/d6/70460b4b4aece5915caf5c68d12f560a9fe3e4اگر دوباره دایرکتوری objects را بررسی کنید، میبینید که حالا یک فایل برای آن محتوای جدید وجود دارد.
Git محتوا را در ابتدا به این شکل ذخیره میکند – یک فایل بهازای هر قطعهی محتوا، با نامی که از SHA-1 آن محتوا و header گرفته شده است.
زیرشاخه با دو کاراکتر اول SHA-1 نامگذاری میشود و اسم فایل، ۳۸ کاراکتر باقیمانده است.
وقتی محتوایی در object database دارید، میتوانید با دستور git cat-file آن محتوا را بررسی کنید.
این دستور مثل یک چاقوی سوئیسی برای مشاهدهی Git objectهاست.
اگر به آن -p بدهید، اول نوع object را تشخیص میدهد و سپس آن را بهدرستی نمایش میدهد:
$ git cat-file -p d670460b4b4aece5915caf5c68d12f560a9fe3e4
test contentحالا میتوانید محتوایی به Git اضافه کنید و دوباره آن را بیرون بکشید. همچنین میتوانید همین کار را با فایلها انجام دهید. برای مثال، میتوانید روی یک فایل ساده، نسخهسازی انجام دهید. ابتدا یک فایل جدید بسازید و محتوای آن را در database ذخیره کنید:
$ echo 'version 1' > test.txt
$ git hash-object -w test.txt
83baae61804e65cc73a7201a7252750c76066a30سپس محتوای جدیدی در فایل بنویسید و دوباره آن را ذخیره کنید:
$ echo 'version 2' > test.txt
$ git hash-object -w test.txt
1f7a7a472abf3dd9643fd615f6da379c4acb3e3aDatabase شما حالا هر دو نسخهی این فایل جدید (بهعلاوهی اولین محتوایی که ذخیره کردهاید) را دارد:
$ find .git/objects -type f
.git/objects/1f/7a7a472abf3dd9643fd615f6da379c4acb3e3a
.git/objects/83/baae61804e65cc73a7201a7252750c76066a30
.git/objects/d6/70460b4b4aece5915caf5c68d12f560a9fe3e4در این مرحله، میتوانید نسخهی محلی فایل test.txt را پاک کنید، سپس با Git آن را از database بازیابی کنید؛
یا نسخهی اولی را:
$ git cat-file -p 83baae61804e65cc73a7201a7252750c76066a30 > test.txt
$ cat test.txt
version 1یا نسخهی دومی را:
$ git cat-file -p 1f7a7a472abf3dd9643fd615f6da379c4acb3e3a > test.txt
$ cat test.txt
version 2اما به خاطر سپردن کلید SHA-1 هر نسخه از فایل عملی نیست؛ بهعلاوه، شما نام فایل را در سیستم ذخیره نمیکنید – فقط محتوا ذخیره میشود.
این نوع object را یک blob مینامند.
میتوانید با دستور git cat-file -t و داشتن کلید SHA-1، نوع هر object را در Git ببینید:
$ git cat-file -t 1f7a7a472abf3dd9643fd615f6da379c4acb3e3a
blobدرخت اشیاء (Tree Objects)
نوع بعدی Git object که بررسی میکنیم tree است؛ این مشکل را حل میکند که نام فایل هم ذخیره شود و علاوه بر آن امکان ذخیرهی گروهی از فایلها را هم فراهم میکند. Git دادهها را به شکلی شبیه به فایلسیستم UNIX ذخیره میکند، اما کمی سادهتر. همهی محتوا بهصورت tree و blob ذخیره میشود؛ treeها مشابه ورودیهای دایرکتوری در UNIX هستند و blobها تقریباً متناظر با inodeها یا محتوای فایلها. یک tree object شامل یک یا چند ورودی است؛ هرکدام یک SHA-1 hash از یک blob یا subtree همراه با mode، نوع (type) و نام فایل هستند. مثلاً فرض کنید پروژهای دارید که آخرین tree آن چیزی شبیه این است:
$ git cat-file -p master^{tree}
100644 blob a906cb2a4a904a152e80877d4088654daad0c859 README
100644 blob 8f94139338f9404f26296befa88755fc2598c289 Rakefile
040000 tree 99f1a6d12cb4b6f19c8655fca46c3ecf317074e0 libسینتکس master^{tree} مشخص میکند که کدام tree object توسط آخرین commit روی شاخهی master اشاره میشود.
دقت کنید که زیرشاخهی lib یک blob نیست، بلکه یک اشارهگر به یک tree دیگر است:
$ git cat-file -p 99f1a6d12cb4b6f19c8655fca46c3ecf317074e0
100644 blob 47c6340d6459e05787f644c2447d2595f5d3a54b simplegit.rb|
یادداشت
|
بسته به اینکه از چه shellی استفاده میکنید، ممکن است هنگام استفاده از سینتکس
|
از نظر مفهومی، دادهای که Git ذخیره میکند چیزی شبیه این است:
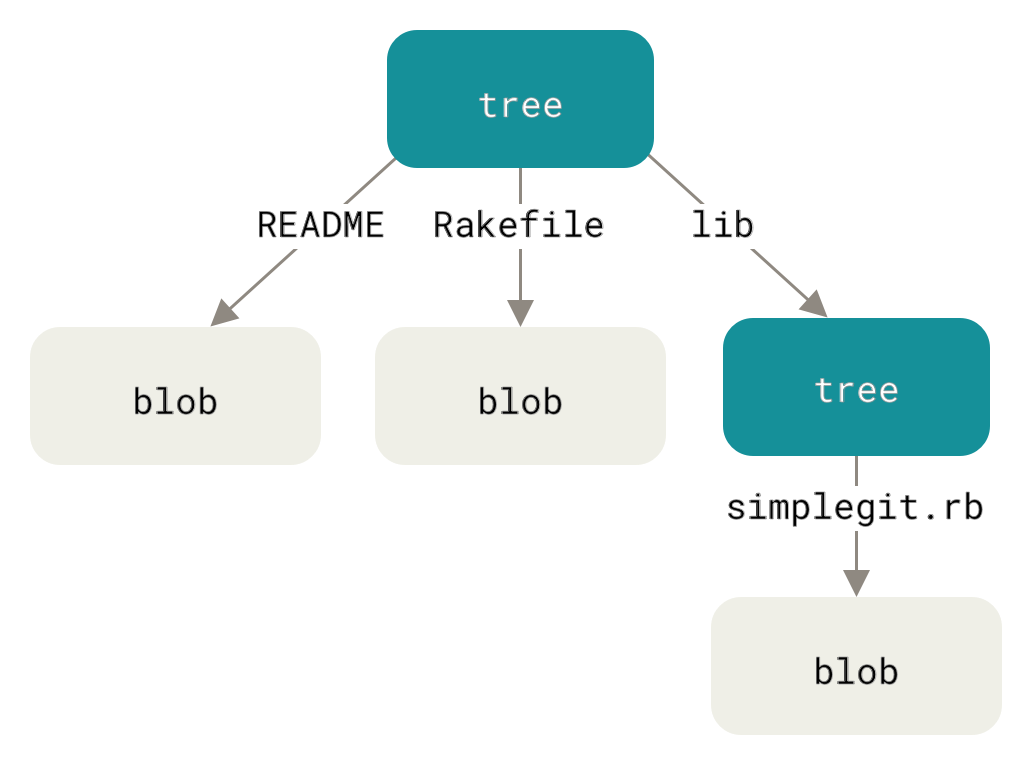
شما میتوانید بهراحتی tree خودتان را بسازید.
معمولاً Git با گرفتن وضعیت staging area یا index شما و نوشتن مجموعهای از tree objectها از آن، یک tree میسازد.
پس برای ایجاد یک tree object، ابتدا باید یک index با staging بعضی فایلها بسازید.
برای ساخت یک index با یک ورودی – اولین نسخهی فایل test.txt – میتوانید از دستور plumbing به نام git update-index استفاده کنید.
این دستور را برای اضافه کردن نسخهی قبلی test.txt به یک staging area جدید استفاده میکنید.
باید گزینهی --add را بدهید چون فایل هنوز در staging area وجود ندارد (حتی staging area هم هنوز ساخته نشده) و --cacheinfo چون فایلی که اضافه میکنید روی دایرکتوری نیست بلکه در database است.
سپس mode، SHA-1 و نام فایل را مشخص میکنید:
$ git update-index --add --cacheinfo 100644 \
83baae61804e65cc73a7201a7252750c76066a30 test.txtدر اینجا، شما یک mode با مقدار 100644 مشخص میکنید که به معنی یک فایل عادی است.
گزینههای دیگر عبارتند از: 100755 برای فایل اجرایی (executable) و 120000 برای لینک نمادین (symbolic link).
Mode از حالتهای استاندارد UNIX گرفته شده اما بسیار سادهتر است – این سه حالت تنها مقادیر معتبر برای فایلها (blobها) در Git هستند (البته modeهای دیگری برای دایرکتوریها و submoduleها استفاده میشوند).
حالا میتوانید با دستور git write-tree محتوای staging area را به یک tree object بنویسید.
نیازی به گزینه -w نیست – اجرای این دستور بهطور خودکار یک tree object از وضعیت index ایجاد میکند اگر هنوز وجود نداشته باشد:
$ git write-tree
d8329fc1cc938780ffdd9f94e0d364e0ea74f579
$ git cat-file -p d8329fc1cc938780ffdd9f94e0d364e0ea74f579
100644 blob 83baae61804e65cc73a7201a7252750c76066a30 test.txtمیتوانید با همان دستور git cat-file که قبلاً دیدید، بررسی کنید که این یک tree object است:
$ git cat-file -t d8329fc1cc938780ffdd9f94e0d364e0ea74f579
treeحالا یک tree جدید با نسخه دوم فایل test.txt و همچنین یک فایل جدید ایجاد میکنید:
$ echo 'new file' > new.txt
$ git update-index --cacheinfo 100644 \
1f7a7a472abf3dd9643fd615f6da379c4acb3e3a test.txt
$ git update-index --add new.txtstaging area شما حالا شامل نسخه جدید test.txt و همچنین فایل new.txt است.
tree جدید را بنویسید (ثبت وضعیت staging area یا index بهعنوان یک tree object) و ببینید چه شکلی است:
$ git write-tree
0155eb4229851634a0f03eb265b69f5a2d56f341
$ git cat-file -p 0155eb4229851634a0f03eb265b69f5a2d56f341
100644 blob fa49b077972391ad58037050f2a75f74e3671e92 new.txt
100644 blob 1f7a7a472abf3dd9643fd615f6da379c4acb3e3a test.txtدقت کنید که این tree هم فایلهای مختلف دارد و هم اینکه SHA-1 مربوط به test.txt همان SHA-1 نسخه دوم از قبل (1f7a7a) است.
برای سرگرمی، شما tree اول را بهعنوان یک زیرشاخه به این tree اضافه میکنید.
میتوانید treeها را با دستور git read-tree به staging area بخوانید.
در اینجا، با استفاده از گزینهی --prefix یک tree موجود را بهعنوان subtree وارد staging area میکنید:
$ git read-tree --prefix=bak d8329fc1cc938780ffdd9f94e0d364e0ea74f579
$ git write-tree
3c4e9cd789d88d8d89c1073707c3585e41b0e614
$ git cat-file -p 3c4e9cd789d88d8d89c1073707c3585e41b0e614
040000 tree d8329fc1cc938780ffdd9f94e0d364e0ea74f579 bak
100644 blob fa49b077972391ad58037050f2a75f74e3671e92 new.txt
100644 blob 1f7a7a472abf3dd9643fd615f6da379c4acb3e3a test.txtاگر از tree جدیدی که نوشتید یک working directory بسازید، دو فایل در سطح اصلی working directory خواهید داشت و یک زیرشاخه به نام bak که شامل نسخه اول فایل test.txt است.
میتوانید دادهای که Git برای این ساختارها ذخیره میکند را اینگونه تصور کنید:
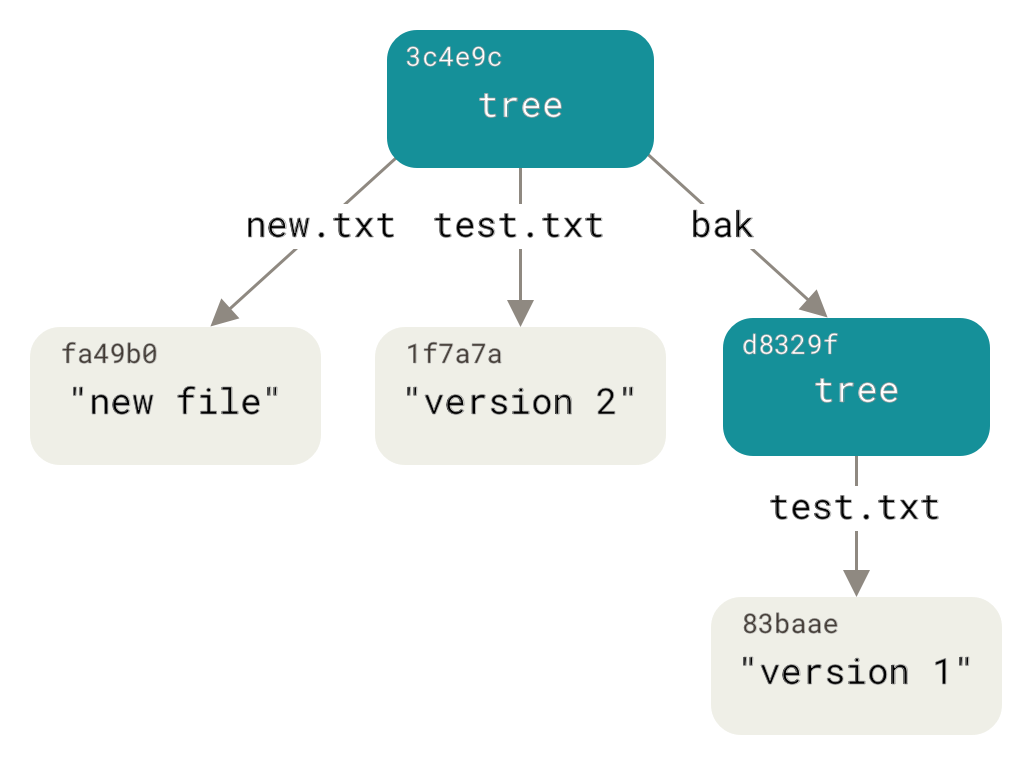
کامیت اشیاء (Commit Objects)
اگر همهی مراحل بالا را انجام داده باشید، اکنون سه tree دارید که snapshotهای مختلف پروژه شما را نمایش میدهند؛ اما مشکل قبلی باقیست: باید هر سه SHA-1 را به خاطر بسپارید تا بتوانید snapshotها را بازیابی کنید. همچنین هیچ اطلاعاتی درباره اینکه چه کسی snapshotها را ذخیره کرده، چه زمانی و چرا ذخیره شدهاند، ندارید. این همان اطلاعات پایهای است که یک commit object برای شما ذخیره میکند.
برای ایجاد یک commit object، دستور commit-tree را فراخوانی کرده و یک tree SHA-1 و commitهای قبلی (در صورت وجود) را مشخص میکنید.
با اولین tree که نوشتید شروع کنید:
$ echo 'First commit' | git commit-tree d8329f
fdf4fc3344e67ab068f836878b6c4951e3b15f3d|
یادداشت
|
شما یک hash متفاوت دریافت خواهید کرد، چون زمان ایجاد و دادههای نویسنده متفاوت است. در اصل، هر commit object با داشتن آن دادهها میتواند بهطور دقیق بازتولید شود، اما جزئیات تاریخیِ تهیه این کتاب باعث میشود commit hashهای چاپشده الزاماً با commitهای دادهشده یکی نباشند. در ادامه، commit و tag hashها را با checksumهای خودتان جایگزین کنید. |
حالا میتوانید commit object جدید خود را با دستور git cat-file بررسی کنید:
$ git cat-file -p fdf4fc3
tree d8329fc1cc938780ffdd9f94e0d364e0ea74f579
author Scott Chacon <schacon@gmail.com> 1243040974 -0700
committer Scott Chacon <schacon@gmail.com> 1243040974 -0700
First commitفرمت یک commit object ساده است: مشخص میکند که tree سطح بالا برای snapshot پروژه در آن نقطه چیست؛ commitهای والد در صورت وجود (commit بالا هیچ والدی ندارد)؛ اطلاعات author/committer (که از تنظیمات user.name و user.email شما و یک timestamp استفاده میکند)؛ یک خط خالی و سپس پیام commit.
سپس، دو commit object دیگر را مینویسید که هرکدام به commit قبلی خود اشاره دارند:
$ echo 'Second commit' | git commit-tree 0155eb -p fdf4fc3
cac0cab538b970a37ea1e769cbbde608743bc96d
$ echo 'Third commit' | git commit-tree 3c4e9c -p cac0cab
1a410efbd13591db07496601ebc7a059dd55cfe9هر سه commit object به یکی از سه snapshot treeای که ساختهاید اشاره میکنند.
جالب است که حالا یک Git history واقعی دارید که میتوانید با اجرای git log روی آخرین commit SHA-1 آن را ببینید:
$ git log --stat 1a410e
commit 1a410efbd13591db07496601ebc7a059dd55cfe9
Author: Scott Chacon <schacon@gmail.com>
Date: Fri May 22 18:15:24 2009 -0700
Third commit
bak/test.txt | 1 +
1 file changed, 1 insertion(+)
commit cac0cab538b970a37ea1e769cbbde608743bc96d
Author: Scott Chacon <schacon@gmail.com>
Date: Fri May 22 18:14:29 2009 -0700
Second commit
new.txt | 1 +
test.txt | 2 +-
2 files changed, 2 insertions(+), 1 deletion(-)
commit fdf4fc3344e67ab068f836878b6c4951e3b15f3d
Author: Scott Chacon <schacon@gmail.com>
Date: Fri May 22 18:09:34 2009 -0700
First commit
test.txt | 1 +
1 file changed, 1 insertion(+)شگفتانگیز است.
شما بهتازگی عملیات سطح پایین برای ساختن یک Git history را بدون استفاده از دستورات front-end انجام دادید.
این دقیقاً همان کاری است که Git هنگام اجرای git add و git commit انجام میدهد – blobهایی برای فایلهای تغییر یافته ذخیره میکند، index را بهروزرسانی میکند، treeها را مینویسد و commit objectهایی که به treeهای سطح بالا و commitهای قبلی اشاره دارند ایجاد میکند.
این سه Git object اصلی – blob، tree و commit – در ابتدا بهعنوان فایلهای جداگانه در دایرکتوری .git/objects ذخیره میشوند.
در اینجا همه objectهای موجود در دایرکتوری مثال را میبینید که هرکدام با توضیح آنچه ذخیره میکنند، مشخص شدهاند:
$ find .git/objects -type f
.git/objects/01/55eb4229851634a0f03eb265b69f5a2d56f341 # tree 2
.git/objects/1a/410efbd13591db07496601ebc7a059dd55cfe9 # commit 3
.git/objects/1f/7a7a472abf3dd9643fd615f6da379c4acb3e3a # test.txt v2
.git/objects/3c/4e9cd789d88d8d89c1073707c3585e41b0e614 # tree 3
.git/objects/83/baae61804e65cc73a7201a7252750c76066a30 # test.txt v1
.git/objects/ca/c0cab538b970a37ea1e769cbbde608743bc96d # commit 2
.git/objects/d6/70460b4b4aece5915caf5c68d12f560a9fe3e4 # 'test content'
.git/objects/d8/329fc1cc938780ffdd9f94e0d364e0ea74f579 # tree 1
.git/objects/fa/49b077972391ad58037050f2a75f74e3671e92 # new.txt
.git/objects/fd/f4fc3344e67ab068f836878b6c4951e3b15f3d # commit 1اگر تمام اشارهگرهای داخلی را دنبال کنید، یک object graph شبیه این خواهید داشت:
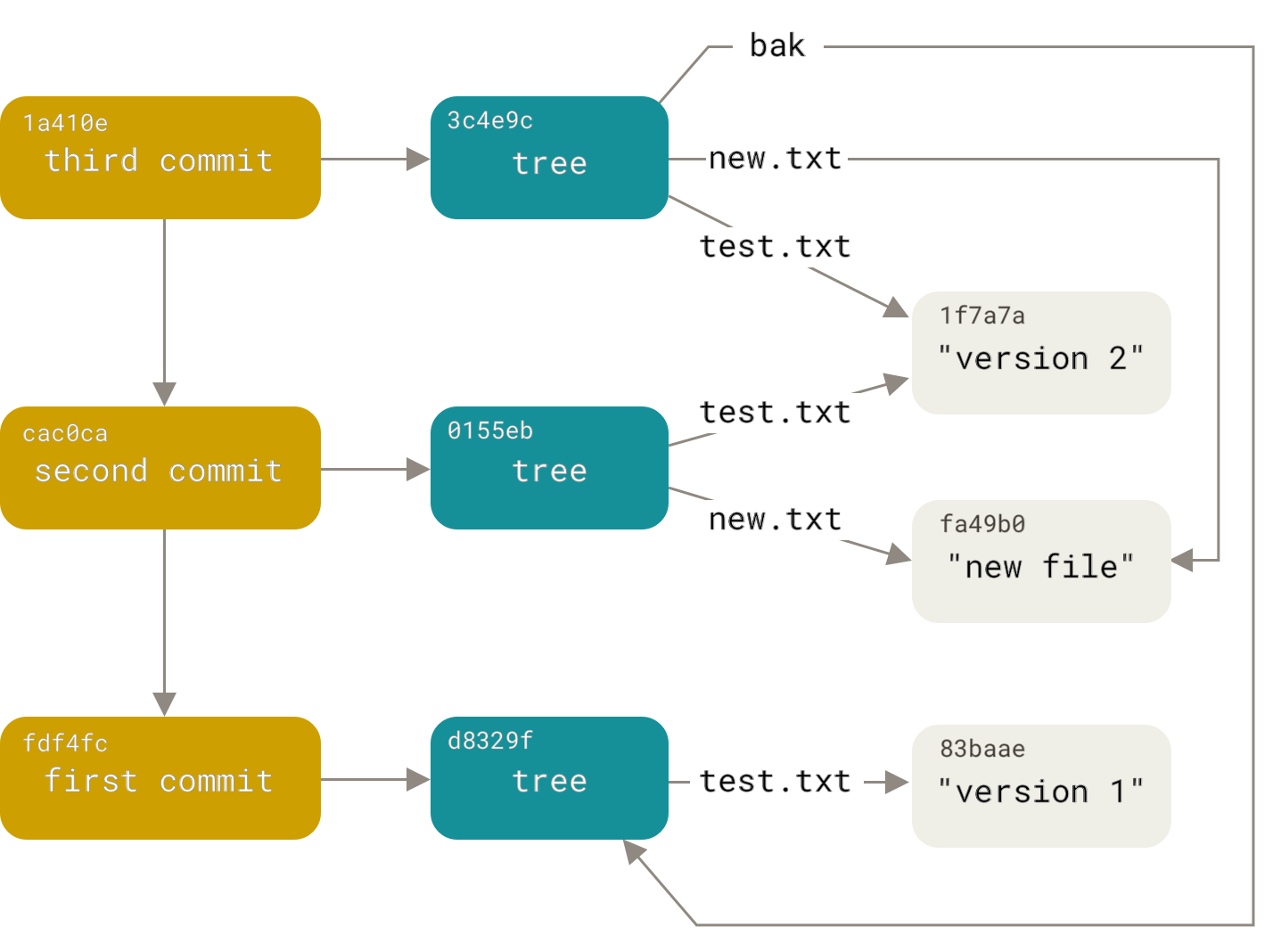
ذخیره سازی اشیاء (Object Storage)
پیشتر اشاره کردیم که همراه هر object که در Git database ذخیره میکنید، یک header هم وجود دارد. بیایید ببینیم Git چطور objectها را ذخیره میکند. شما میبینید که چگونه میتوان یک blob object – در این مثال رشتهی “what is up, doc?” – را بهصورت تعاملی در زبان Ruby ذخیره کرد.
میتوانید حالت تعاملی Ruby را با دستور irb اجرا کنید:
$ irb
>> content = "what is up, doc?"
=> "what is up, doc?"Git ابتدا یک header میسازد که نوع object (در اینجا blob) را مشخص میکند. به این بخش اول header، یک فاصله و سپس اندازه محتوای برحسب بایت اضافه میشود و در انتها یک null byte قرار میگیرد:
>> header = "blob #{content.bytesize}\0"
=> "blob 16\u0000"سپس Git این header و محتوای اصلی را به هم متصل کرده و checksum آن را با الگوریتم SHA-1 محاسبه میکند.
در Ruby میتوانید مقدار SHA-1 یک رشته را با include کردن کتابخانهی SHA1 digest با دستور require و سپس فراخوانی Digest::SHA1.hexdigest() محاسبه کنید:
>> store = header + content
=> "blob 16\u0000what is up, doc?"
>> require 'digest/sha1'
=> true
>> sha1 = Digest::SHA1.hexdigest(store)
=> "bd9dbf5aae1a3862dd1526723246b20206e5fc37"بیایید این را با خروجی دستور git hash-object مقایسه کنیم.
اینجا از echo -n استفاده میکنیم تا یک newline به ورودی اضافه نشود:
$ echo -n "what is up, doc?" | git hash-object --stdin
bd9dbf5aae1a3862dd1526723246b20206e5fc37Git محتوای جدید را با zlib فشرده میکند؛ در Ruby هم میتوانید با کتابخانهی zlib این کار را انجام دهید.
ابتدا باید کتابخانه را require کنید و سپس Zlib::Deflate.deflate() را روی محتوا اجرا کنید:
>> require 'zlib'
=> true
>> zlib_content = Zlib::Deflate.deflate(store)
=> "x\x9CK\xCA\xC9OR04c(\xCFH,Q\xC8,V(-\xD0QH\xC9O\xB6\a\x00_\x1C\a\x9D"در نهایت، محتوای فشردهشده با zlib را روی دیسک بهعنوان یک object مینویسید.
مسیر object را بر اساس SHA-1 تعیین میکنید (دو کاراکتر اول بهعنوان نام زیرشاخه و ۳۸ کاراکتر باقیمانده بهعنوان نام فایل درون آن دایرکتوری).
در Ruby میتوانید از تابع FileUtils.mkdir_p() برای ایجاد زیرشاخه در صورت عدم وجود آن استفاده کنید.
سپس فایل را با File.open() باز کرده و محتوای فشردهشده را با یک فراخوانی write() روی file handle ایجادشده بنویسید:
>> path = '.git/objects/' + sha1[0,2] + '/' + sha1[2,38]
=> ".git/objects/bd/9dbf5aae1a3862dd1526723246b20206e5fc37"
>> require 'fileutils'
=> true
>> FileUtils.mkdir_p(File.dirname(path))
=> ".git/objects/bd"
>> File.open(path, 'w') { |f| f.write zlib_content }
=> 32حالا محتوای object را با دستور git cat-file بررسی کنید:
---
$ git cat-file -p bd9dbf5aae1a3862dd1526723246b20206e5fc37
what is up, doc?
---همین! شما یک Git blob object معتبر ساختهاید.
تمام Git objectها به همین شیوه ذخیره میشوند، فقط نوع آنها متفاوت است – بهجای رشتهی blob، header با commit یا tree شروع میشود. همچنین، در حالی که محتوای blob میتواند تقریباً هر چیزی باشد، محتوای commit و tree ساختار بسیار مشخصی دارند.