
-
1. Введение
- 1.1 О системе контроля версий
- 1.2 Краткая история Git
- 1.3 Что такое Git?
- 1.4 Командная строка
- 1.5 Установка Git
- 1.6 Первоначальная настройка Git
- 1.7 Как получить помощь?
- 1.8 Заключение
-
2. Основы Git
-
3. Ветвление в Git
- 3.1 О ветвлении в двух словах
- 3.2 Основы ветвления и слияния
- 3.3 Управление ветками
- 3.4 Работа с ветками
- 3.5 Удалённые ветки
- 3.6 Перебазирование
- 3.7 Заключение
-
4. Git на сервере
- 4.1 Протоколы
- 4.2 Установка Git на сервер
- 4.3 Генерация открытого SSH ключа
- 4.4 Настраиваем сервер
- 4.5 Git-демон
- 4.6 Умный HTTP
- 4.7 GitWeb
- 4.8 GitLab
- 4.9 Git-хостинг
- 4.10 Заключение
-
5. Распределённый Git
-
6. GitHub
-
7. Инструменты Git
- 7.1 Выбор ревизии
- 7.2 Интерактивное индексирование
- 7.3 Припрятывание и очистка
- 7.4 Подпись
- 7.5 Поиск
- 7.6 Перезапись истории
- 7.7 Раскрытие тайн reset
- 7.8 Продвинутое слияние
- 7.9 Rerere
- 7.10 Обнаружение ошибок с помощью Git
- 7.11 Подмодули
- 7.12 Создание пакетов
- 7.13 Замена
- 7.14 Хранилище учётных данных
- 7.15 Заключение
-
8. Настройка Git
- 8.1 Конфигурация Git
- 8.2 Атрибуты Git
- 8.3 Хуки в Git
- 8.4 Пример принудительной политики Git
- 8.5 Заключение
-
9. Git и другие системы контроля версий
- 9.1 Git как клиент
- 9.2 Переход на Git
- 9.3 Заключение
-
10. Git изнутри
- 10.1 Сантехника и Фарфор
- 10.2 Объекты Git
- 10.3 Ссылки в Git
- 10.4 Pack-файлы
- 10.5 Спецификации ссылок
- 10.6 Протоколы передачи данных
- 10.7 Обслуживание репозитория и восстановление данных
- 10.8 Переменные окружения
- 10.9 Заключение
-
A1. Приложение A: Git в других окружениях
- A1.1 Графические интерфейсы
- A1.2 Git в Visual Studio
- A1.3 Git в Visual Studio Code
- A1.4 Git в Eclipse
- A1.5 Git в IntelliJ / PyCharm / WebStorm / PhpStorm / RubyMine
- A1.6 Git в Sublime Text
- A1.7 Git в Bash
- A1.8 Git в Zsh
- A1.9 Git в PowerShell
- A1.10 Заключение
-
A2. Приложение B: Встраивание Git в ваши приложения
- A2.1 Git из командной строки
- A2.2 Libgit2
- A2.3 JGit
- A2.4 go-git
- A2.5 Dulwich
-
A3. Приложение C: Команды Git
- A3.1 Настройка и конфигурация
- A3.2 Клонирование и создание репозиториев
- A3.3 Основные команды
- A3.4 Ветвление и слияния
- A3.5 Совместная работа и обновление проектов
- A3.6 Осмотр и сравнение
- A3.7 Отладка
- A3.8 Внесение исправлений
- A3.9 Работа с помощью электронной почты
- A3.10 Внешние системы
- A3.11 Администрирование
- A3.12 Низкоуровневые команды
10.2 Git изнутри - Объекты Git
Объекты Git
Git — контентно-адресуемая файловая система. Здорово. Что это означает? А означает это, по сути, что Git — простое хранилище ключ-значение. Можно добавить туда любые данные, в ответ будет выдан ключ по которому их можно извлечь обратно.
В качестве примера, воспользуемся служебной командой git hash-object, которая берёт некоторые данные, сохраняет их в виде объекта в каталоге .git/objects (база данных объектов) и возвращает уникальный ключ, который является ссылкой на созданный объект.
Для начала создадим новый Git-репозиторий и убедимся, что каталог objects пуст:
$ git init test
Initialized empty Git repository in /tmp/test/.git/
$ cd test
$ find .git/objects
.git/objects
.git/objects/info
.git/objects/pack
$ find .git/objects -type fGit проинициализировал каталог objects и создал в нём пустые подкаталоги pack и info.
Теперь с помощью git hash-object создадим объект и вручную добавим его в базу Git:
$ echo 'test content' | git hash-object -w --stdin
d670460b4b4aece5915caf5c68d12f560a9fe3e4В простейшем случае git hash-object берёт переданный контент и возвращает уникальный ключ, который будет использоваться для хранения данных в базе Git.
Параметр -w указывает команде git hash-object не просто вернуть ключ, а ещё и сохранить объект в базе данных.
Последний параметр --stdin указывает, что git hash-object должна использовать данные, переданные на стандартный потока ввода; в противном случае команда ожидает путь к файлу в качестве аргумента.
Результат выполнения команды — 40-символьная контрольная сумма. Это SHA-1 хеш — контрольная сумма содержимого и заголовка, который будет рассмотрен позднее. Теперь можно посмотреть как Git хранит ваши данные:
$ find .git/objects -type f
.git/objects/d6/70460b4b4aece5915caf5c68d12f560a9fe3e4Мы видим новый файл в каталоге objects.
Это и есть начальное внутреннее представление данных в Git — один файл на единицу хранения с именем, являющимся контрольной суммой содержимого и заголовка.
Первые два символа SHA-1 определяют подкаталог файла внутри objects, остальные 38 — его имя.
Извлечь содержимое объекта можно при помощи команды cat-file.
Она подобна швейцарскому ножу для анализа объектов Git.
Ключ -p указывает команде cat-file автоматически определять тип объекта и выводить результат в соответствующем виде:
$ git cat-file -p d670460b4b4aece5915caf5c68d12f560a9fe3e4
test contentТеперь вы умеете добавлять данные в Git и извлекать их обратно. То же самое можно делать и с файлами. Например, можно проверсионировать один файл. Для начала, создадим новый файл и сохраним его в базе данных Git:
$ echo 'version 1' > test.txt
$ git hash-object -w test.txt
83baae61804e65cc73a7201a7252750c76066a30Теперь изменим файл и сохраним его в базе ещё раз:
$ echo 'version 2' > test.txt
$ git hash-object -w test.txt
1f7a7a472abf3dd9643fd615f6da379c4acb3e3aТеперь в базе содержатся две версии файла, а также самый первый сохранённый объект:
$ find .git/objects -type f
.git/objects/1f/7a7a472abf3dd9643fd615f6da379c4acb3e3a
.git/objects/83/baae61804e65cc73a7201a7252750c76066a30
.git/objects/d6/70460b4b4aece5915caf5c68d12f560a9fe3e4Теперь можно откатить файл к его первой версии:
$ git cat-file -p 83baae61804e65cc73a7201a7252750c76066a30 > test.txt
$ cat test.txt
version 1или ко второй:
$ git cat-file -p 1f7a7a472abf3dd9643fd615f6da379c4acb3e3a > test.txt
$ cat test.txt
version 2Однако запоминать хеш для каждой версии неудобно, к тому же теряется имя файла, сохраняется лишь содержимое.
Объекты такого типа называют блобами (англ. blob — binary large object).
Имея SHA-1 объекта, можно попросить Git показать нам его тип с помощью команды cat-file -t:
$ git cat-file -t 1f7a7a472abf3dd9643fd615f6da379c4acb3e3a
blobДеревья
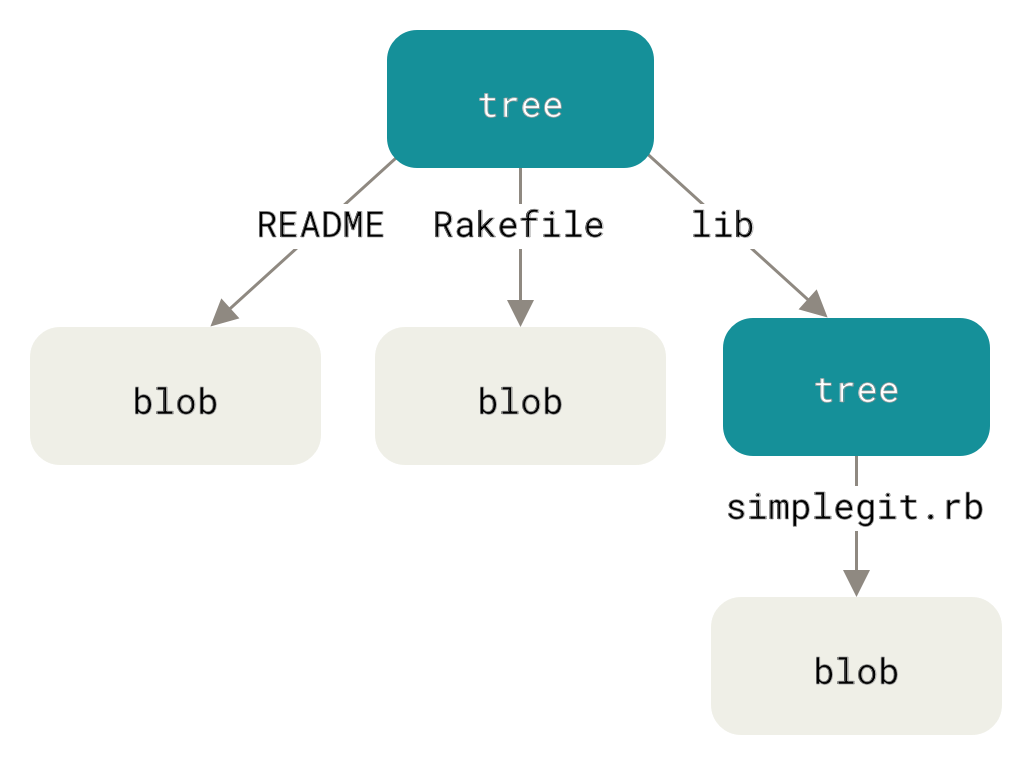
Следующий тип объектов, который мы рассмотрим, — деревья — решают проблему хранения имён файлов, а также позволяют хранить группы файлов вместе. Git хранит данные сходным с файловыми системами UNIX способом, но в немного упрощённом виде. Содержимое хранится в деревьях и блобах, где дерево соответствует каталогу на файловой системе, а блоб более или менее соответствует индексу узла (inode) или содержимому файла. Дерево может содержать одну или более записей, содержащих SHA-1 хеш, соответствующий блобу или поддереву, права доступа к файлу, тип и имя файла. Например, дерево последнего коммита в проекте может выглядеть следующим образом:
$ git cat-file -p master^{tree}
100644 blob a906cb2a4a904a152e80877d4088654daad0c859 README
100644 blob 8f94139338f9404f26296befa88755fc2598c289 Rakefile
040000 tree 99f1a6d12cb4b6f19c8655fca46c3ecf317074e0 libЗапись master^{tree} указывает на дерево, соответствующее последнему коммиту ветки master.
Обратите внимание, что подкаталог lib — не блоб, а указатель на другое дерево:
$ git cat-file -p 99f1a6d12cb4b6f19c8655fca46c3ecf317074e0
100644 blob 47c6340d6459e05787f644c2447d2595f5d3a54b simplegit.rb|
Примечание
|
Вы можете столкнуться с различными ошибками при использовании синтаксиса В Windows CMD символ В ZSH символ |
Концептуально, данные хранятся в Git примерно так:
Можно создать дерево самому.
Обычно, Git создаёт дерево путём создания набора объектов из состояния области подготовленных файлов или индекса.
Поэтому для создания дерева необходимо проиндексировать какие-нибудь файлы.
Для создания индекса из одной записи — первой версии файла test.txt — воспользуемся низкоуровневой командой git update-index.
Данная команда может искусственно добавить более раннюю версию test.txt в новый индекс.
Необходимо передать опции --add, так как файл ещё не существует в индексе (да и самого индекса ещё нет), и --cacheinfo, так как добавляемого файла нет в рабочем каталоге, но он есть в базе данных.
Также необходимо передать права доступа, хеш и имя файла:
$ git update-index --add --cacheinfo 100644 \
83baae61804e65cc73a7201a7252750c76066a30 test.txtВ данном случае права доступа 100644 — означают обычный файл.
Другие возможные варианты: 100755 — исполняемый файл, 120000 — символическая ссылка.
Права доступа в Git сделаны по аналогии с правами доступа в UNIX, но они гораздо менее гибки: указанные три режима — единственные доступные для файлов (блобов) в Git (хотя существуют и другие режимы, используемые для каталогов и подмодулей).
Теперь можно воспользоваться командой git write-tree для сохранения индекса в объект дерева.
Здесь опция -w не требуется — команда автоматически создаст дерево из индекса, если такого дерева ещё не существует:
$ git write-tree
d8329fc1cc938780ffdd9f94e0d364e0ea74f579
$ git cat-file -p d8329fc1cc938780ffdd9f94e0d364e0ea74f579
100644 blob 83baae61804e65cc73a7201a7252750c76066a30 test.txtИспользуя ту же команду git cat-file, можно проверить, что созданный объект действительно является деревом:
$ git cat-file -t d8329fc1cc938780ffdd9f94e0d364e0ea74f579
treeДавайте создадим новое дерево со второй версией файла test.txt и ещё одним файлом:
$ echo 'new file' > new.txt
$ git update-index --add --cacheinfo 100644 \
1f7a7a472abf3dd9643fd615f6da379c4acb3e3a test.txt
$ git update-index --add new.txtТеперь в области подготовленных файлов содержится новая версия файла test.txt и новый файл new.txt.
Зафиксируем изменения, сохранив состояние индекса в новое дерево, и посмотрим, что из этого вышло:
$ git write-tree
0155eb4229851634a0f03eb265b69f5a2d56f341
$ git cat-file -p 0155eb4229851634a0f03eb265b69f5a2d56f341
100644 blob fa49b077972391ad58037050f2a75f74e3671e92 new.txt
100644 blob 1f7a7a472abf3dd9643fd615f6da379c4acb3e3a test.txtОбратите внимание, что в данном дереве находятся записи для обоих файлов, а также, что хеш файла test.txt это хеш «второй версии» этого файла (1f7a7a).
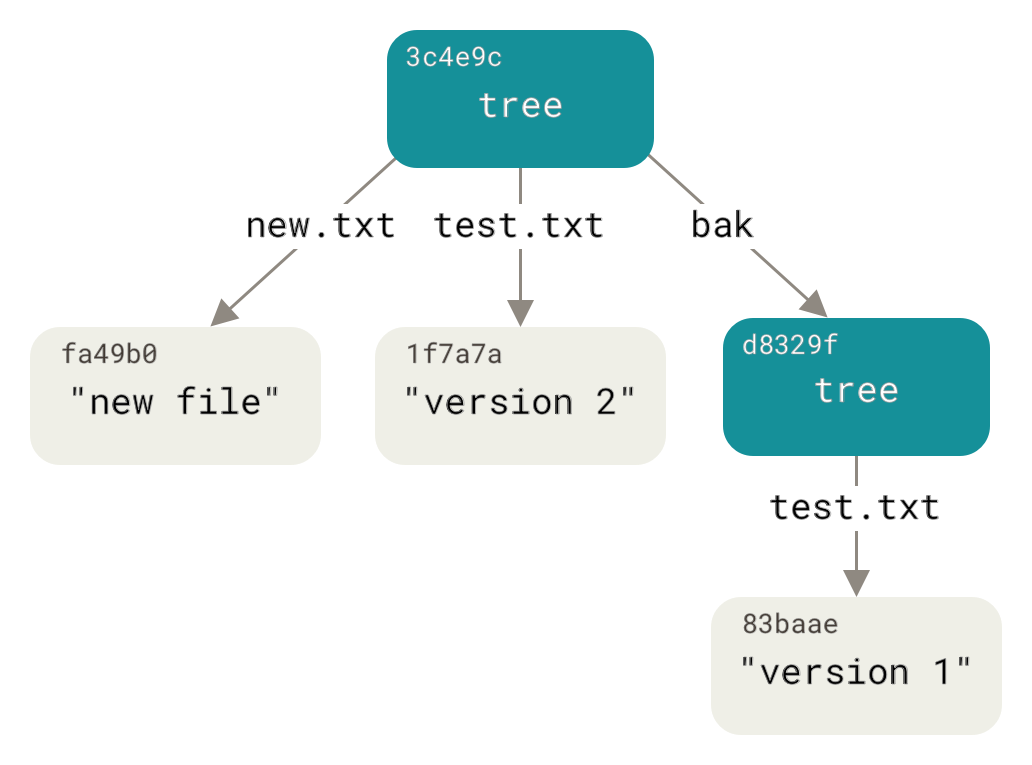
Для интереса, добавим первое дерево как подкаталог текущего.
Добавлять деревья в область подготовленных файлов можно с помощью команды git read-tree.
В нашем случае, чтобы включить уже существующее дерево в индекс и сделать его поддеревом, необходимо использовать опцию --prefix:
$ git read-tree --prefix=bak d8329fc1cc938780ffdd9f94e0d364e0ea74f579
$ git write-tree
3c4e9cd789d88d8d89c1073707c3585e41b0e614
$ git cat-file -p 3c4e9cd789d88d8d89c1073707c3585e41b0e614
040000 tree d8329fc1cc938780ffdd9f94e0d364e0ea74f579 bak
100644 blob fa49b077972391ad58037050f2a75f74e3671e92 new.txt
100644 blob 1f7a7a472abf3dd9643fd615f6da379c4acb3e3a test.txtЕсли бы вы сейчас добавили только что сохранённое дерево в рабочий каталог, вы бы увидели два файла в его корне и подкаталог bak с первой версией файла test.txt.
В таком случае хранимые структуры данных можно представить следующим образом:
Объекты коммитов
У вас есть три дерева, соответствующих разным состояниям проекта, но предыдущая проблема с необходимостью запоминать все три значения SHA-1, чтобы иметь возможность восстановить какое-либо из этих состояний, ещё не решена. К тому же у нас нет никакой информации о том, кто, когда и почему сохранил их. Такие данные — основная информация, хранимая в объекте коммита.
Для создания коммита необходимо вызвать команду commit-tree и задать SHA-1 нужного дерева и, если необходимо, родительские коммиты.
Начнём с создания коммита для самого первого дерева:
$ echo 'First commit' | git commit-tree d8329f
fdf4fc3344e67ab068f836878b6c4951e3b15f3dПолученный вами хеш будет отличаться, так как отличается дата создания и информация об авторе.
Далее в этой главе используйте собственные хеши коммитов и тегов.
Просмотреть созданный объект коммита можно командой cat-file:
$ git cat-file -p fdf4fc3
tree d8329fc1cc938780ffdd9f94e0d364e0ea74f579
author Scott Chacon <schacon@gmail.com> 1243040974 -0700
committer Scott Chacon <schacon@gmail.com> 1243040974 -0700
First commitФормат объекта коммита прост: в нём указано дерево верхнего уровня, соответствующее состоянию проекта на некоторый момент; родительские коммиты, если существуют (в примере выше объект коммита не имеет родителей); имена автора и коммиттера (берутся из полей конфигурации user.name и user.email) с указанием временной метки; пустая строка и сообщение коммита.
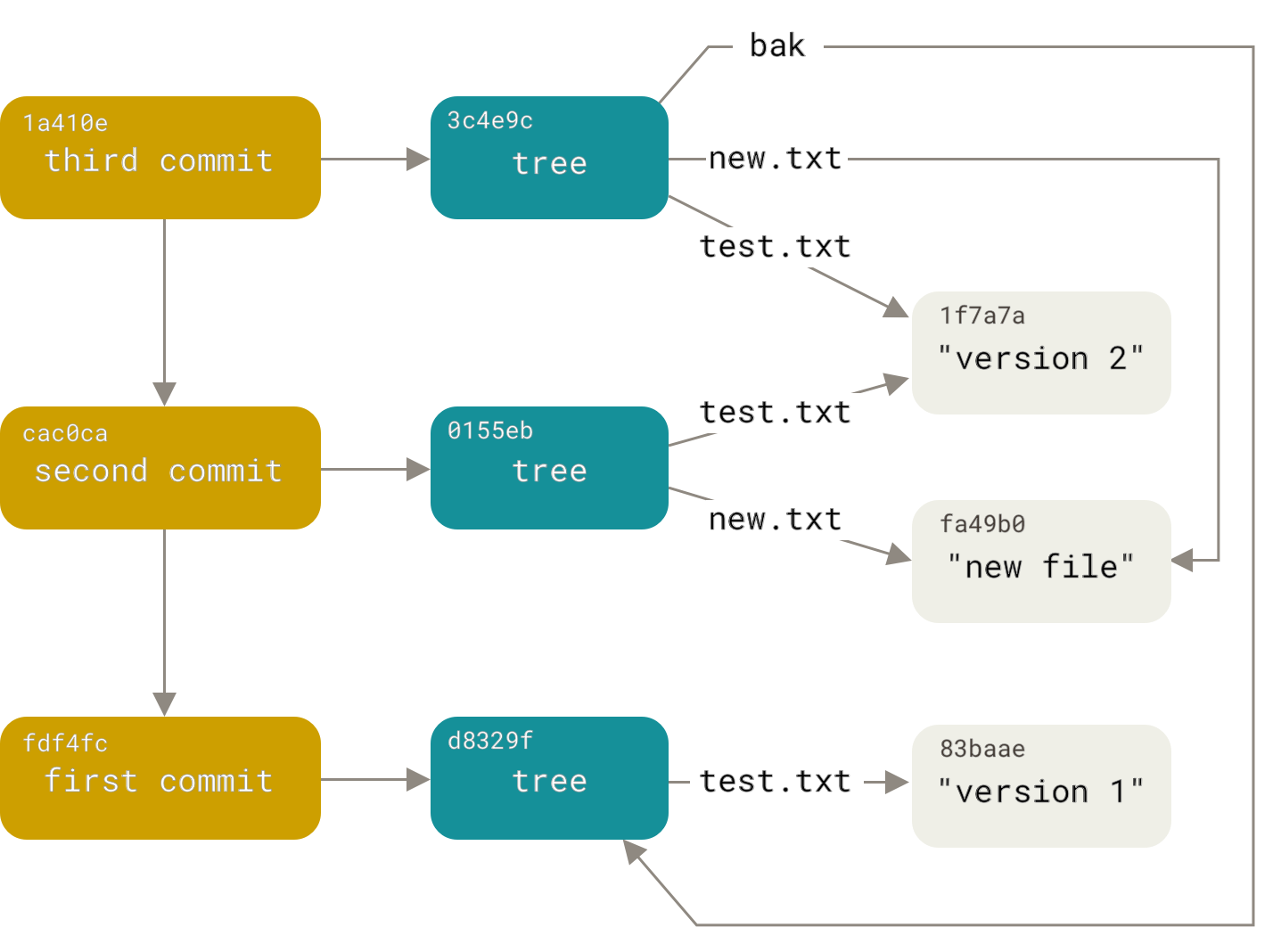
Далее, создадим ещё два объекта коммита, каждый из которых будет ссылаться на предыдущий:
$ echo 'Second commit' | git commit-tree 0155eb -p fdf4fc3
cac0cab538b970a37ea1e769cbbde608743bc96d
$ echo 'Third commit' | git commit-tree 3c4e9c -p cac0cab
1a410efbd13591db07496601ebc7a059dd55cfe9Каждый из созданных объектов коммитов указывает на одно из созданных ранее деревьев состояния проекта.
Вы не поверите, но теперь у нас есть полноценная Git история, которую можно посмотреть командой git log, указав хеш последнего коммита:
$ git log --stat 1a410e
commit 1a410efbd13591db07496601ebc7a059dd55cfe9
Author: Scott Chacon <schacon@gmail.com>
Date: Fri May 22 18:15:24 2009 -0700
Third commit
bak/test.txt | 1 +
1 file changed, 1 insertion(+)
commit cac0cab538b970a37ea1e769cbbde608743bc96d
Author: Scott Chacon <schacon@gmail.com>
Date: Fri May 22 18:14:29 2009 -0700
Second commit
new.txt | 1 +
test.txt | 2 +-
2 files changed, 2 insertions(+), 1 deletion(-)
commit fdf4fc3344e67ab068f836878b6c4951e3b15f3d
Author: Scott Chacon <schacon@gmail.com>
Date: Fri May 22 18:09:34 2009 -0700
First commit
test.txt | 1 +
1 file changed, 1 insertion(+)Здорово, правда?
Мы только что выполнили несколько низкоуровневых операций и получили Git репозиторий с историей без единой высокоуровневой команды.
Именно так и работает Git, когда выполняются команды git add и git commit — сохраняет блобы для изменённых файлов, обновляет индекс, создаёт деревья и фиксирует изменения в объекте коммита, ссылающемся на дерево верхнего уровня и предшествующие коммиты.
Эти три основных вида объектов Git — блоб, дерево и коммит — сохраняются в виде отдельных файлов в каталоге .git/objects.
Вот как сейчас выглядит список объектов в этом каталоге, в комментарии указано чему соответствует каждый из них:
$ find .git/objects -type f
.git/objects/01/55eb4229851634a0f03eb265b69f5a2d56f341 # tree 2
.git/objects/1a/410efbd13591db07496601ebc7a059dd55cfe9 # commit 3
.git/objects/1f/7a7a472abf3dd9643fd615f6da379c4acb3e3a # test.txt v2
.git/objects/3c/4e9cd789d88d8d89c1073707c3585e41b0e614 # tree 3
.git/objects/83/baae61804e65cc73a7201a7252750c76066a30 # test.txt v1
.git/objects/ca/c0cab538b970a37ea1e769cbbde608743bc96d # commit 2
.git/objects/d6/70460b4b4aece5915caf5c68d12f560a9fe3e4 # 'test content'
.git/objects/d8/329fc1cc938780ffdd9f94e0d364e0ea74f579 # tree 1
.git/objects/fa/49b077972391ad58037050f2a75f74e3671e92 # new.txt
.git/objects/fd/f4fc3344e67ab068f836878b6c4951e3b15f3d # commit 1Если пройти по всем внутренним ссылкам, получится граф объектов, представленный на рисунке:
Хранение объектов
Ранее мы упоминали, что вместе с содержимым объекта сохраняется дополнительный заголовок. Давайте посмотрим, как Git хранит объекты на диске. Мы рассмотрим как происходит сохранение блоб объекта — в данном случае это будет строка «what is up, doc?» — в интерактивном режиме на языке Ruby.
Для запуска интерактивного интерпретатора воспользуйтесь командой irb:
$ irb
>> content = "what is up, doc?"
=> "what is up, doc?"Git создаёт заголовок, начинающийся с типа объекта, в данном случае это блоб. Далее идут пробел, размер содержимого в байтах и в конце нулевой байт:
>> header = "blob #{content.bytesize}\0"
=> "blob 16\u0000"Git объединяет заголовок и оригинальный контент, а затем вычисляет SHA-1 сумму от полученного результата.
В Ruby значение SHA-1 для строки можно получить, подключив соответствующую библиотеку командой require и затем вызвав Digest::SHA1.hexdigest():
>> store = header + content
=> "blob 16\u0000what is up, doc?"
>> require 'digest/sha1'
=> true
>> sha1 = Digest::SHA1.hexdigest(store)
=> "bd9dbf5aae1a3862dd1526723246b20206e5fc37"Давайте сравним полученный результат с выводом команды git hash-object.
Здесь используется echo -n для предотвращения автоматического добавления переноса строки.
$ echo -n "what is up, doc?" | git hash-object --stdin
bd9dbf5aae1a3862dd1526723246b20206e5fc37Git сжимает новые данные при помощи zlib, в Ruby это можно сделать с помощью одноимённой библиотеки.
Сперва необходимо подключить её, а затем вызвать Zlib::Deflate.deflate():
>> require 'zlib'
=> true
>> zlib_content = Zlib::Deflate.deflate(store)
=> "x\x9CK\xCA\xC9OR04c(\xCFH,Q\xC8,V(-\xD0QH\xC9O\xB6\a\x00_\x1C\a\x9D"После этого сохраним сжатую строку в объект на диске.
Определим путь к файлу, который будет записан (первые два символа хеша используются в качестве названия каталога, оставшиеся 38 — в качестве имени файла в ней).
В Ruby для безопасного создания нескольких вложенных каталогов можно использовать функцию FileUtils.mkdir_p().
Далее, откроем файл вызовом File.open() и запишем сжатые данные вызовом write() для полученного файлового дескриптора:
>> path = '.git/objects/' + sha1[0,2] + '/' + sha1[2,38]
=> ".git/objects/bd/9dbf5aae1a3862dd1526723246b20206e5fc37"
>> require 'fileutils'
=> true
>> FileUtils.mkdir_p(File.dirname(path))
=> ".git/objects/bd"
>> File.open(path, 'w') { |f| f.write zlib_content }
=> 32Теперь проверим содержимое объекта с помощью git cat-file:
---
$ git cat-file -p bd9dbf5aae1a3862dd1526723246b20206e5fc37
what is up, doc?
---Вот и всё, мы создали корректный блоб объект для Git.
Все другие объекты создаются аналогичным образом, меняется лишь запись о типе в заголовке: «blob», «commit» либо «tree». Стоит добавить, что блоб может иметь практически любое содержимое, однако содержимое объектов деревьев и коммитов записывается в очень строгом формате.