
-
1. Démarrage rapide
-
2. Les bases de Git
-
3. Les branches avec Git
-
4. Git sur le serveur
- 4.1 Protocoles
- 4.2 Installation de Git sur un serveur
- 4.3 Génération des clés publiques SSH
- 4.4 Mise en place du serveur
- 4.5 Démon (Daemon) Git
- 4.6 HTTP intelligent
- 4.7 GitWeb
- 4.8 GitLab
- 4.9 Git hébergé
- 4.10 Résumé
-
5. Git distribué
-
6. GitHub
-
7. Utilitaires Git
- 7.1 Sélection des versions
- 7.2 Indexation interactive
- 7.3 Remisage et nettoyage
- 7.4 Signer votre travail
- 7.5 Recherche
- 7.6 Réécrire l’historique
- 7.7 Reset démystifié
- 7.8 Fusion avancée
- 7.9 Rerere
- 7.10 Déboguer avec Git
- 7.11 Sous-modules
- 7.12 Empaquetage (bundling)
- 7.13 Replace
- 7.14 Stockage des identifiants
- 7.15 Résumé
-
8. Personnalisation de Git
- 8.1 Configuration de Git
- 8.2 Attributs Git
- 8.3 Crochets Git
- 8.4 Exemple de politique gérée par Git
- 8.5 Résumé
-
9. Git et les autres systèmes
- 9.1 Git comme client
- 9.2 Migration vers Git
- 9.3 Résumé
-
10. Les tripes de Git
- 10.1 Plomberie et porcelaine
- 10.2 Les objets de Git
- 10.3 Références Git
- 10.4 Fichiers groupés
- 10.5 La refspec
- 10.6 Les protocoles de transfert
- 10.7 Maintenance et récupération de données
- 10.8 Les variables d’environnement
- 10.9 Résumé
-
A1. Annexe A: Git dans d’autres environnements
- A1.1 Interfaces graphiques
- A1.2 Git dans Visual Studio
- A1.3 Git dans Visual Studio Code
- A1.4 Git dans IntelliJ / PyCharm / WebStorm / PhpStorm / RubyMine
- A1.5 Git dans Sublime Text
- A1.6 Git dans Bash
- A1.7 Git dans Zsh
- A1.8 Git dans PowerShell
- A1.9 Résumé
-
A2. Annexe B: Embarquer Git dans vos applications
- A2.1 Git en ligne de commande
- A2.2 Libgit2
- A2.3 JGit
- A2.4 go-git
- A2.5 Dulwich
-
A3. Commandes Git
- A3.1 Installation et configuration
- A3.2 Obtention et création des projets
- A3.3 Capture d’instantané basique
- A3.4 Création de branches et fusion
- A3.5 Partage et mise à jour de projets
- A3.6 Inspection et comparaison
- A3.7 Débogage
- A3.8 Patchs
- A3.9 Courriel
- A3.10 Systèmes externes
- A3.11 Administration
- A3.12 Commandes de plomberie
3.1 Les branches avec Git - Les branches en bref
Presque tous les VCS proposent une certaine forme de gestion de branches. Créer une branche signifie diverger de la ligne principale de développement et continuer à travailler sans impacter cette ligne. Pour de nombreux VCS, il s’agit d’un processus coûteux qui nécessite souvent la création d’une nouvelle copie du répertoire de travail, ce qui peut prendre longtemps dans le cas de gros projets.
Certaines personnes considèrent le modèle de gestion de branches de Git comme ce qu’il a de plus remarquable et il offre sûrement à Git une place à part au sein de la communauté des VCS. En quoi est-il si spécial ? La manière dont Git gère les branches est incroyablement légère et permet de réaliser les opérations sur les branches de manière quasi instantanée et, généralement, de basculer entre les branches aussi rapidement. À la différence de nombreux autres VCS, Git encourage des méthodes qui privilégient la création et la fusion fréquentes de branches, jusqu’à plusieurs fois par jour. Bien comprendre et maîtriser cette fonctionnalité vous permettra de faire de Git un outil puissant et unique et peut totalement changer votre manière de développer.
Les branches en bref
Pour réellement comprendre la manière dont Git gère les branches, nous devons revenir en arrière et examiner de plus près comment Git stocke ses données.
Si vous vous souvenez bien du chapitre Démarrage rapide, Git ne stocke pas ses données comme une série de modifications ou de différences successives mais plutôt comme une série d’instantanés (appelés snapshots).
Lorsque vous faites un commit, Git stocke un objet commit qui contient un pointeur vers l’instantané (snapshot) du contenu que vous avez indexé. Cet objet contient également les noms et prénoms de l’auteur, le message que vous avez renseigné ainsi que des pointeurs vers le ou les commits qui précèdent directement ce commit : aucun parent pour le commit initial, un parent pour un commit normal et de multiples parents pour un commit qui résulte de la fusion d’une ou plusieurs branches.
Pour visualiser ce concept, supposons que vous avez un répertoire contenant trois fichiers que vous indexez puis validez. L’indexation des fichiers calcule une empreinte (checksum) pour chacun (via la fonction de hachage SHA-1 mentionnée au chapitre Démarrage rapide), stocke cette version du fichier dans le dépôt Git (Git les nomme blobs) et ajoute cette empreinte à la zone d’index (staging area) :
$ git add README test.rb LICENSE
$ git commit -m 'initial commit of my project'Lorsque vous créez le commit en lançant la commande git commit, Git calcule l’empreinte de chaque sous-répertoire (ici, seulement pour le répertoire racine) et stocke ces objets de type arbre dans le dépôt Git.
Git crée alors un objet commit qui contient les méta-données et un pointeur vers l’arbre de la racine du projet de manière à pouvoir recréer l’instantané à tout moment.
Votre dépôt Git contient à présent cinq objets : un blob pour le contenu de chacun de vos trois fichiers, un arbre (tree) qui liste le contenu du répertoire et spécifie quels noms de fichiers sont attachés à quels blobs et enfin un objet commit portant le pointeur vers l’arbre de la racine ainsi que toutes les méta-données attachées au commit.
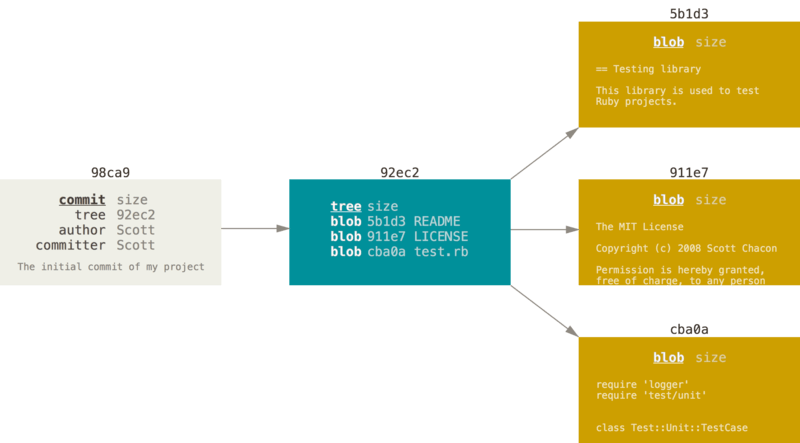
Si vous faites des modifications et validez à nouveau, le prochain commit stocke un pointeur vers le commit le précédant immédiatement.
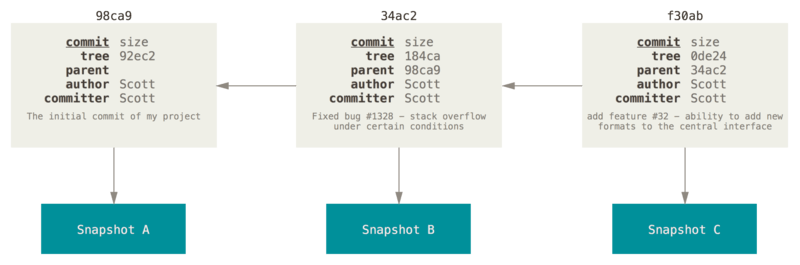
Une branche dans Git est simplement un pointeur léger et déplaçable vers un de ces commits.
La branche par défaut dans Git s’appelle master.
Au fur et à mesure des validations, la branche master pointe vers le dernier des commits réalisés.
À chaque validation, le pointeur de la branche master avance automatiquement.
|
Note
|
La branche |
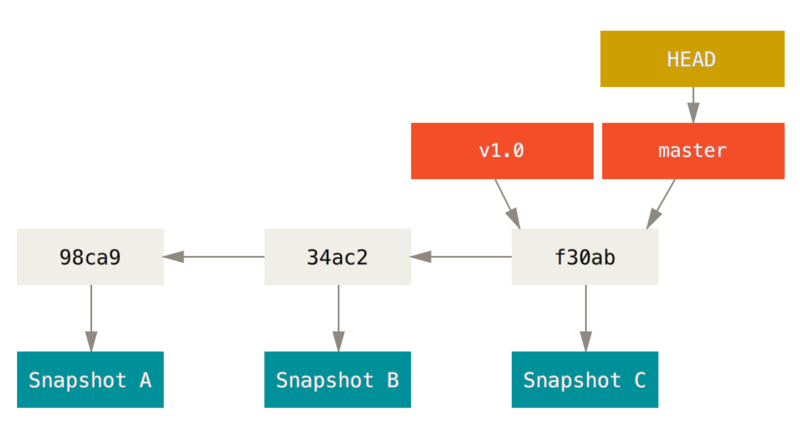
Créer une nouvelle branche
Que se passe-t-il si vous créez une nouvelle branche ?
Eh bien, cela crée un nouveau pointeur pour vous.
Supposons que vous créez une nouvelle branche nommée test.
Vous utilisez pour cela la commande git branch :
$ git branch testingCela crée un nouveau pointeur vers le commit courant.
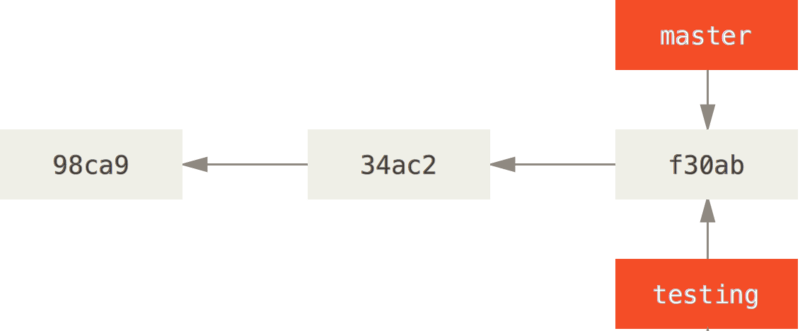
Comment Git connaît-il alors la branche sur laquelle vous vous trouvez ?
Il conserve à cet effet un pointeur spécial appelé HEAD.
Vous remarquez que sous cette appellation se cache un concept très différent de celui utilisé dans les autres VCS tels que Subversion ou CVS.
Dans Git, il s’agit simplement d’un pointeur sur la branche locale où vous vous trouvez.
Dans ce cas, vous vous trouvez toujours sur master.
En effet, la commande git branch n’a fait que créer une nouvelle branche — elle n’a pas fait basculer la copie de travail vers cette branche.
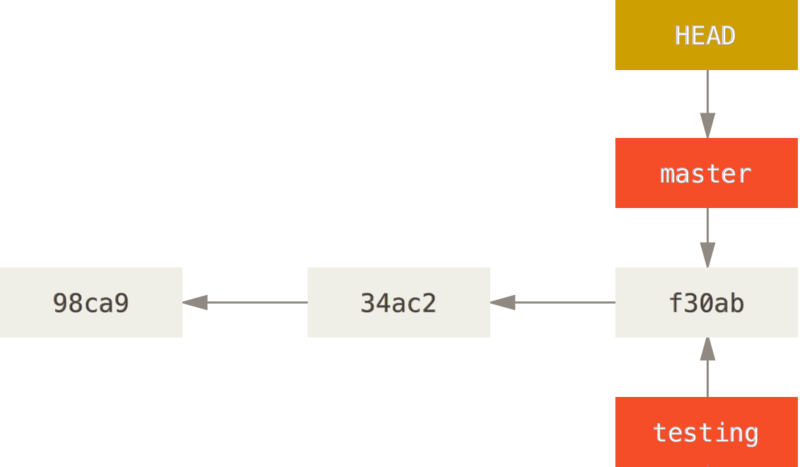
Vous pouvez vérifier cela facilement grâce à la commande git log qui vous montre vers quoi les branches pointent.
Il s’agit de l’option --decorate.
$ git log --oneline --decorate
f30ab (HEAD, master, test) add feature #32 - ability to add new
34ac2 fixed bug #ch1328 - stack overflow under certain conditions
98ca9 initial commit of my projectVous pouvez voir les branches master et test qui se situent au niveau du commit f30ab.
Basculer entre les branches
Pour basculer sur une branche existante, il suffit de lancer la commande git checkout.
Basculons sur la nouvelle branche testing :
$ git checkout testingCela déplace HEAD pour le faire pointer vers la branche testing.
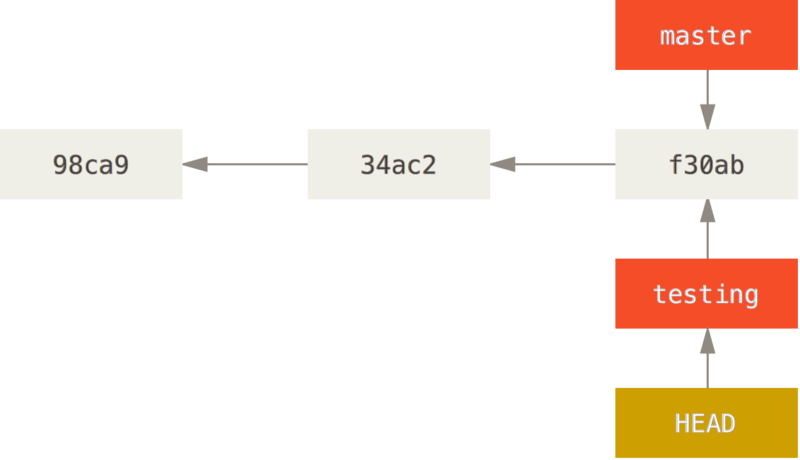
Qu’est-ce que cela signifie ? Et bien, faisons une autre validation :
$ vim test.rb
$ git commit -a -m 'made a change'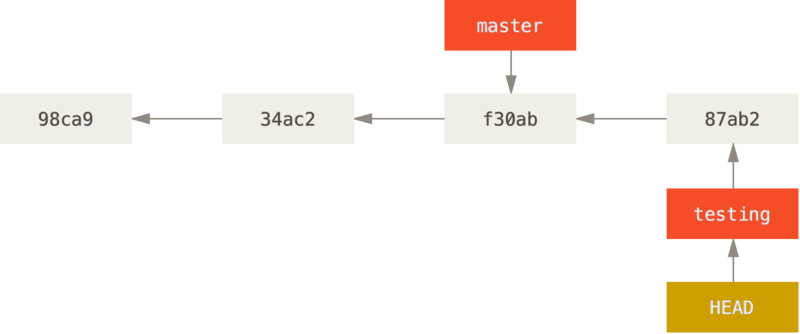
C’est intéressant parce qu’à présent, votre branche testing a avancé tandis que la branche master pointe toujours sur le commit sur lequel vous étiez lorsque vous avez lancé la commande git checkout pour changer de branche.
Retournons sur la branche master :
$ git checkout master|
Note
|
git log ne montre pas toutes les branches tout le tempsSi vous alliez lancer La branche n’a pas disparu ; Git ne sait juste pas que cette branche vous intéresse et il essaie de vous montrer ce qu’il pense être le plus pertinent.
Autrement dit, par défaut, Pour montrer l’historique des commites de la branche désirée, vous devez la spécifier explicitement : |
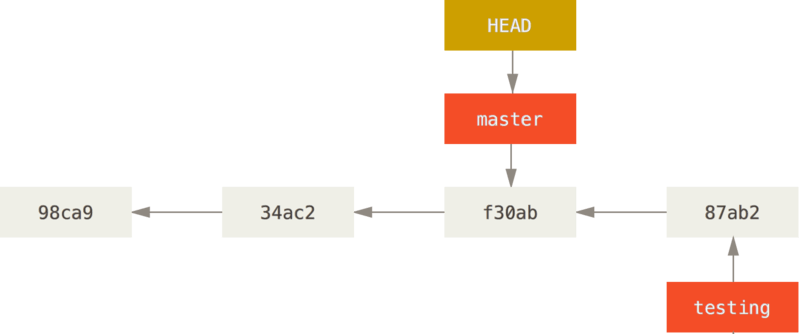
Cette commande a réalisé deux actions.
Elle a remis le pointeur HEAD sur la branche master et elle a replacé les fichiers de votre répertoire de travail dans l’état du snapshot pointé par master.
Cela signifie aussi que les modifications que vous réalisez à partir de ce point divergeront de l’ancienne version du projet.
Cette commande annule les modifications réalisées dans la branche testing pour vous permettre de repartir dans une autre direction.
|
Note
|
Changer de branche modifie les fichiers dans votre répertoire de travail
Il est important de noter que lorsque vous changez de branche avec Git, les fichiers de votre répertoire de travail sont modifiés. Si vous basculez vers une branche plus ancienne, votre répertoire de travail sera remis dans l’état dans lequel il était lors du dernier commit sur cette branche. Si git n’est pas en mesure d’effectuer cette action proprement, il ne vous laissera pas changer de branche. |
Réalisons quelques autres modifications et validons à nouveau :
$ vim test.rb
$ git commit -a -m 'made other changes'Maintenant, l’historique du projet a divergé (voir Divergence d’historique).
Vous avez créé une branche et basculé dessus, y avez réalisé des modifications, puis vous avez rebasculé sur la branche principale et réalisé d’autres modifications.
Ces deux modifications sont isolées dans des branches séparées : vous pouvez basculer d’une branche à l’autre et les fusionner quand vous êtes prêt.
Et vous avez fait tout ceci avec de simples commandes : branch, checkout et commit.
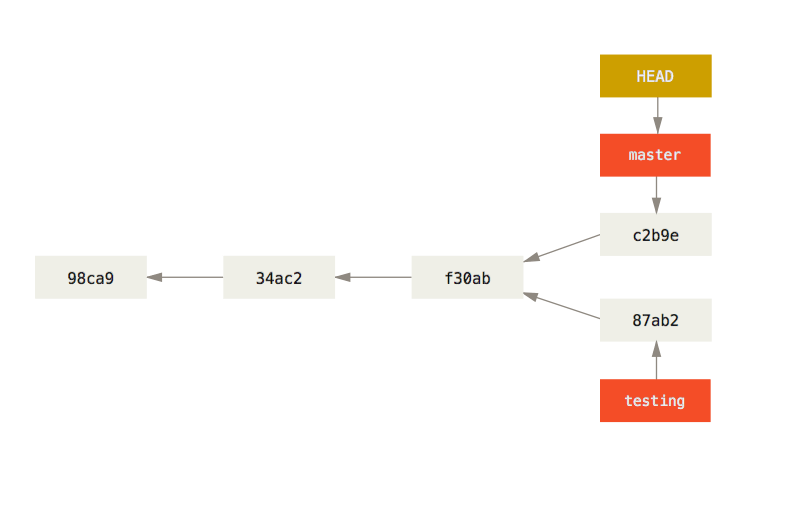
Vous pouvez également voir ceci grâce à la commande git log.
La commande git log --oneline --decorate --graph --all va afficher l’historique de vos commits, affichant les endroits où sont positionnés vos pointeurs de branche ainsi que la manière dont votre historique a divergé.
$ git log --oneline --decorate --graph --all
* c2b9e (HEAD, master) made other changes
| * 87ab2 (test) made a change
|/
* f30ab add feature #32 - ability to add new formats to the
* 34ac2 fixed bug #ch1328 - stack overflow under certain conditions
* 98ca9 initial commit of my projectParce qu’une branche Git n’est en fait qu’un simple fichier contenant les 40 caractères de l’empreinte SHA-1 du commit sur lequel elle pointe, les branches ne coûtent quasiment rien à créer et à détruire. Créer une branche est aussi simple et rapide qu’écrire 41 caractères dans un fichier (40 caractères plus un retour chariot).
C’est une différence de taille avec la manière dont la plupart des VCS gèrent les branches, qui implique de copier tous les fichiers du projet dans un second répertoire. Cela peut durer plusieurs secondes ou même quelques minutes selon la taille du projet, alors que pour Git, le processus est toujours instantané. De plus, comme nous enregistrons les parents quand nous validons les modifications, la détermination de l’ancêtre commun approprié pour la fusion est réalisée automatiquement pour nous et est généralement une opération très facile. Ces fonctionnalités encouragent naturellement les développeurs à créer et utiliser souvent des branches.
Voyons pourquoi vous devriez en faire autant.
|
Note
|
Créer une branche et basculer dessus en même temps
Il est habituel de créer une nouvelle branche et de vouloir basculer sur cette nouvelle branche en même temps — ça peut être réalisé en une seule opération avec |
|
Note
|
Depuis Git version 2.23, on peut utiliser
|